








 超级会员免费看
超级会员免费看

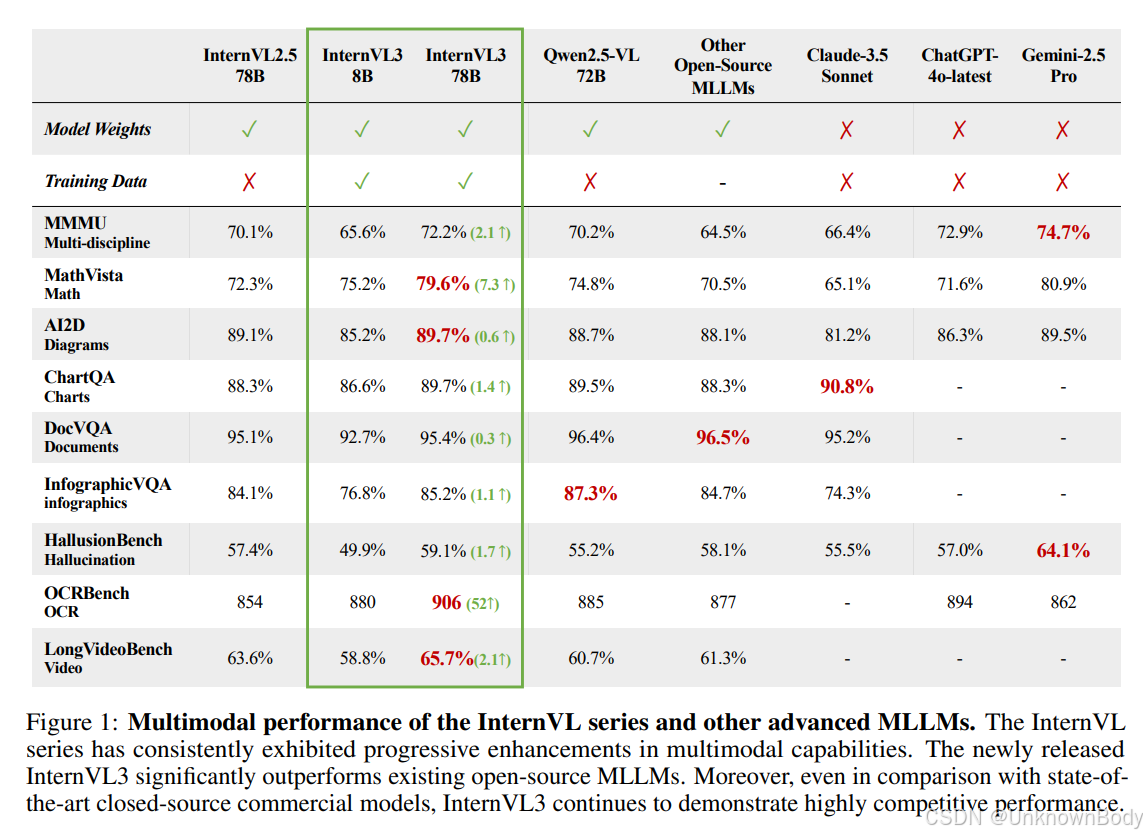
主要内容
- 模型架构:遵循“ViT-MLP-LLM”范式,使用预训练的视觉编码器和语言模型初始化,引入可变视觉位置编码(V2PE),通过像素重组操作提升处理高分辨率图像的能力。
- 训练方法
- 原生多模态预训练:将语言预训练和多模态对齐训练整合为一个阶段,通过多模态自回归公式和联合参数优化,使模型同时学习语言和多模态能力,使用多模态数据和纯语言数据进行训练,并采用特定采样策略确定数据比例。
- 后训练:采用监督微调(SFT)和混合偏好优化(MPO)两个阶段。SFT使用更高质量和更多样的数据,MPO通过引入正负样本监督来对齐模型响应分布,提升推理性能。
- 测试时缩放策略:采用Best-of-N评估策略,使用VisualPRM-8B作为评判模型,通过给解决方案步骤打分来选择最佳响应,用于推理和数学评估。
- 基础设施

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











