







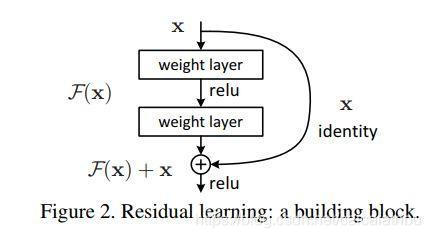
本系列为darknet源码解析,本次解析src/short_layer.h 与 src/short_layer.c 两个。在yolo v3中short_layer主要完成直连操作,完成残差块中的恒等映射操作;
shortcut_layer.h 的定义如下:
#ifndef SHORTCUT_LAYER_H
#define SHORTCUT_LAYER_H
#include "layer.h"
#include "network.h"
// 构建yolo v3的shortcut层
layer make_shortcut_layer(int batch, int index, int w, int h, int c, int w2, int h2, int c2);
// shortcut层的前向,反向传播
void forward_shortcut_layer(const layer l, network net);
void backward_shortcut_layer(const layer l, network net);
void resize_shortcut_layer(layer *l, int w, int h);
#ifdef GPU
void forward_shortcut_layer_gpu(const layer l, network net);
void backward_shortcut_layer_gpu(const layer l, network net);
#endif
#endifshortcut_layer.c 的详细解析如下:
#include "shortcut_layer.h"
#include "cuda.h"
#include "blas.h"
#include "activations.h"
#include <stdio.h>
#include <assert.h>
/**
* 构建yolo v3中shortcut层
* @param batch 一个batch中包含图片的张数
* @param index 输入层的编号
* @param w 输入图片的宽度
* @param h 输入图片的高度
* @param c 输入图片的通道数
* @param w2 输出图片的宽度
* @param h2 输出图片的高度
* @param c2 输出图片的通道数
* @return
*/
layer make_shortcut_layer(int batch, int index, int w, int h, int c, int w2, int h2, int c2)
{
fprintf(stderr, "res %3d %4d x%4d x%4d -> %4d x%4d x%4d\n",index, w2,h2,c2, w,h,c);
layer l = {0};
l.type = SHORTCUT; // 层类别
l.batch = batch; // 一个batch中包含图片的张数
l.w = w2; // 输入图片的宽度
l.h = h2; // 输入图片的高度
l.c = c2; // 输入图片的通道数
l.out_w = w; // 输出图片的宽度
l.out_h = h; // 输出图片的高度
l.out_c = c; // 输出图片的通道数
l.outputs = w*h*c; // shortcut层对应一张输入图片的输出元素个数
l.inputs = l.outputs; // sortcut层一张输入图片的元素个数
l.index = index; // 输入层的编号
l.delta = calloc(l.outputs*batch, sizeof(float)); // shortcut层的误差项(包含整个batch的)
l.output = calloc(l.outputs*batch, sizeof(float)); // shortcut层的所有输出(包含整个batch的)
l.forward = forward_shortcut_layer; // short层的前向传播
l.backward = backward_shortcut_layer; // short层的反向传播
#ifdef GPU
l.forward_gpu = forward_shortcut_layer_gpu;
l.backward_gpu = backward_shortcut_layer_gpu;
l.delta_gpu = cuda_make_array(l.delta, l.outputs*batch);
l.output_gpu = cuda_make_array(l.output, l.outputs*batch);
#endif
return l;
}
void resize_shortcut_layer(layer *l, int w, int h)
{
assert(l->w == l->out_w);
assert(l->h == l->out_h);
l->w = l->out_w = w;
l->h = l->out_h = h;
l->outputs = w*h*l->out_c;
l->inputs = l->outputs;
l->delta = realloc(l->delta, l->outputs*l->batch*sizeof(float));
l->output = realloc(l->output, l->outputs*l->batch*sizeof(float));
#ifdef GPU
cuda_free(l->output_gpu);
cuda_free(l->delta_gpu);
l->output_gpu = cuda_make_array(l->output, l->outputs*l->batch);
l->delta_gpu = cuda_make_array(l->delta, l->outputs*l->batch);
#endif
}
// shortcut_cpu(l.batch, l.w, l.h, l.c, net.layers[l.index].output, l.out_w, l.out_h, l.out_c, l.alpha, l.beta, l.output);
// shortcut_cpu(l.batch, l.out_w, l.out_h, l.out_c, l.delta, l.w, l.h, l.c, 1, l.beta, net.layers[l.index].delta);
void shortcut_cpu(int batch, int w1, int h1, int c1, float *add, int w2, int h2, int c2, float s1, float s2, float *out)
{
// 在yolo v3中w1=w2,h1=h2
int stride = w1/w2;
int sample = w2/w1;
assert(stride == h1/h2);
assert(sample == h2/h1);
if(stride < 1) stride = 1;
if(sample < 1) sample = 1;
int minw = (w1 < w2) ? w1 : w2;
int minh = (h1 < h2) ? h1 : h2;
int minc = (c1 < c2) ? c1 : c2;
int i,j,k,b;
for(b = 0; b < batch; ++b){
for(k = 0; k < minc; ++k){
for(j = 0; j < minh; ++j){
for(i = 0; i < minw; ++i){
int out_index = i*sample + w2*(j*sample + h2*(k + c2*b)); // 输出层index
int add_index = i*stride + w1*(j*stride + h1*(k + c1*b)); // 输入层index
out[out_index] = s1*out[out_index] + s2*add[add_index]; // 在yolov3中,s1=1, s2=1
}
}
}
}
}
/**
* shortcut层的前向传播函数
* @param l 当前shortcut层
* @param net 整个网络
*/
void forward_shortcut_layer(const layer l, network net)
{
// l.output = net.input
copy_cpu(l.outputs*l.batch, net.input, 1, l.output, 1);
// 前向传播
shortcut_cpu(l.batch, l.w, l.h, l.c, net.layers[l.index].output, l.out_w, l.out_h, l.out_c, l.alpha, l.beta, l.output);
// 使用线性激活函数
activate_array(l.output, l.outputs*l.batch, l.activation);
}
/**
* shortcut层的反向传播函数
* @param l 当前shortcut层
* @param net 整个网络
*/
void backward_shortcut_layer(const layer l, network net)
{
// 使用线性激活,所有l.delta *= 1
gradient_array(l.output, l.outputs*l.batch, l.activation, l.delta);
// net.delta += l.delta
axpy_cpu(l.outputs*l.batch, l.alpha, l.delta, 1, net.delta, 1);
// 梯度反传
shortcut_cpu(l.batch, l.out_w, l.out_h, l.out_c, l.delta, l.w, l.h, l.c, 1, l.beta, net.layers[l.index].delta);
}
#ifdef GPU
void forward_shortcut_layer_gpu(const layer l, network net)
{
copy_gpu(l.outputs*l.batch, net.input_gpu, 1, l.output_gpu, 1);
shortcut_gpu(l.batch, l.w, l.h, l.c, net.layers[l.index].output_gpu, l.out_w, l.out_h, l.out_c, l.alpha, l.beta, l.output_gpu);
activate_array_gpu(l.output_gpu, l.outputs*l.batch, l.activation);
}
void backward_shortcut_layer_gpu(const layer l, network net)
{
gradient_array_gpu(l.output_gpu, l.outputs*l.batch, l.activation, l.delta_gpu);
axpy_gpu(l.outputs*l.batch, l.alpha, l.delta_gpu, 1, net.delta_gpu, 1);
shortcut_gpu(l.batch, l.out_w, l.out_h, l.out_c, l.delta_gpu, l.w, l.h, l.c, 1, l.beta, net.layers[l.index].delta_gpu);
}
#endif
完,














 3338
3338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









