









###################################
本文全部为单节点部署配置,不涉及任何集群。
###################################
前提
安装JDK1.8

配置ssh免密登录

mongoDB导出CSV格式的数据文件
mongoexport导出文件格式支持csv和json,不同的是csv格式必须显示的指定要导出的字段:
mongoexport -d rbac -c rbacs -o d:/web/rbac.csv --type csv -f name,type
举例:导出消息中心的message_ali集合下的日志记录
./mongoexport -d message_center -c message_ali -o message_center.message_ali.json --type csv -f _id,_class,appId,method,apiKey,messageType,createTime,bizContent
Hadoop安装配置:
1.Hadoop官网下载压缩包,解压后如下图

2.万年不变的配置环境变量:
vim /etc/profile
export HADOOP_HOME=/mnt/xvdb/hadoop/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin
3.万年不变的配置Hive的配置文件:

主要修改core-site.xml和hdfs-site.xml这两个配置文件,修改内容如下:
core-site.xml
hdfs-site.xml
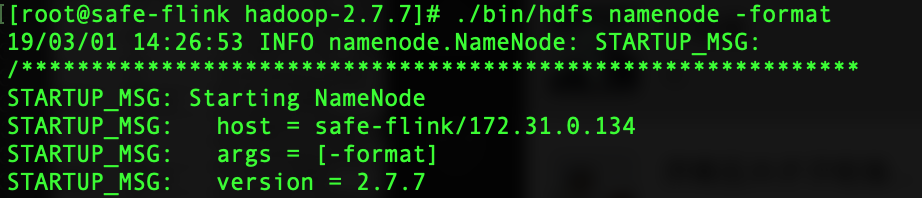
4.HDFS格式化
./bin/hdfs namenode -format

5.HDFS创建目录
创建目录主要服务于hive
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hive
hdfs dfs -mkdir /user/hive/warehouse
修改读写权限
hdfs dfs -chmod g+w /user/hive/warehouse
6.启动Hadoop
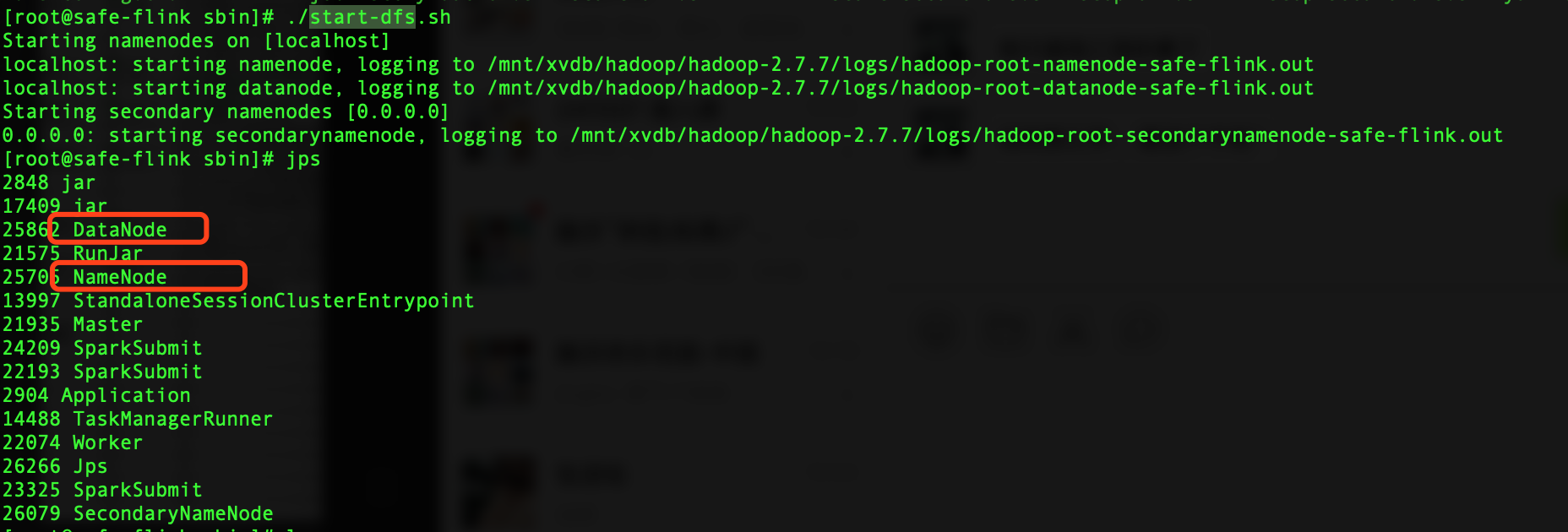
./sbin/start-dfs.sh
启动后可以用jps看下是否有DataNode和NameNode两个服务,如果没有或者是缺一,表示启动有问题,需要检查。

Hive安装配置:
1.Hive官网下载压缩包,解压后如下图

2.驱动配置:
用mysql存储Hive相关的元数据,默认的derby不能同时保持多个连接,所以直接上mysql。
如果需要替换hive默认数据库的话需要下载相应的数据库驱动,这里替换为mysql,所以需要额外下载mysql驱动:mysql-connector-java-5.1.46.jar
注意如果最新的mysql驱动可能导致不兼容,如mysql-connector-java-6.0.6.jar,会导致后续功能无法正常使用。
将下载后的驱动jar放到hive目录下的lib下:/mnt/xvdb/hive/apache-hive-2.3.4-bin/lib
3.万年不变的配置环境变量:
vim /etc/profile
export HIVE_HOME=/mnt/xvdb/hive/apache-hive-2.3.4-bin
export PATH=$PATH:$HIVE_HOME/bin
4.万年不变的配置Hive的配置文件:
conf目录下的配置文件多以.template结尾,这是官方提供的配置样例,我们这里目前只用到hive-default.xml.template
执行下面命令复制一个hive-site.xml的配置文件,注意名称不要用hive-default.xml,否则不生效(至少在2.3.4这个版本是这样)
cp hive-default.xml.template hive-site.xml

5.然后对hive-site.xml进行修改:
路径修改,否则后续会启动使用会报错。



默认数据库修改为mysql

非必须配置,看是否会报相关方面的错误。

6.mysql准备工作:
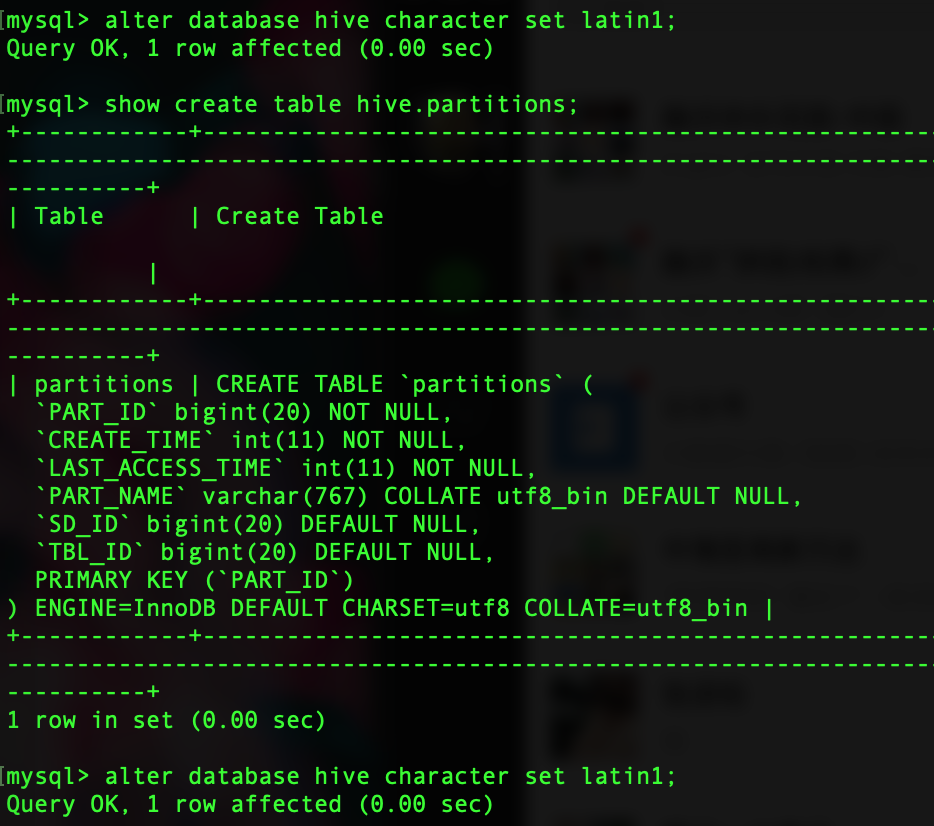
mysql中新建一个hive的schema,之后需要修改字符编码(alter database hive character set latin1;),否则默认的可能是UTF-8,后面在spark-sql中执行show databases或者类似的脚本时会报下图的错误

如果你已经遇到了上面的错误,去mysql中执行下show create table hive.partitions看下随便一个表的创建脚本,如果如下图中一样显示charset=utf8而非charset=latin1,你就需要修改默认字符编码来解决这个问题了。

修改hive这个schema的默认字符编码,不影响其他schema,脚本如下
alter database hive character set latin1;
执行完毕后需要将之前创建过的表全部清空,或者直接删除schema后创建新的schema再执行上述脚本也行,视具体情况决定。
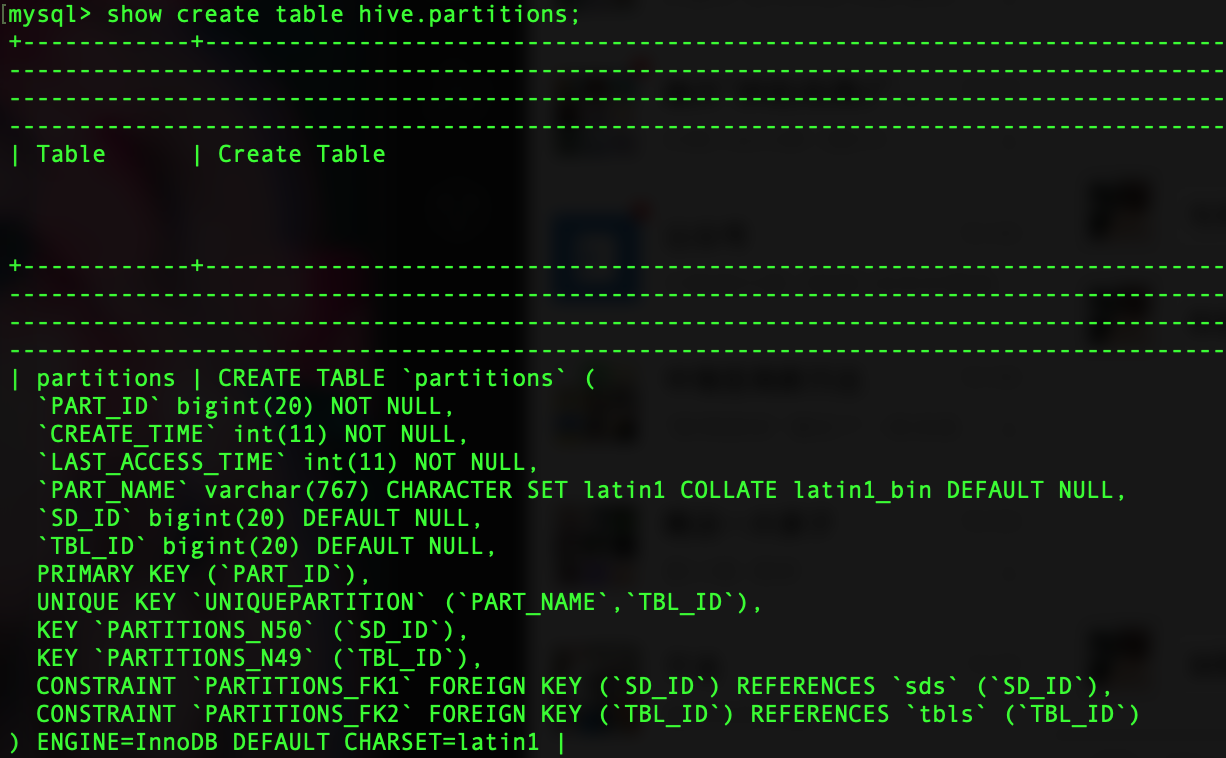
重新建表后再次执行
show create table hive.partitions;
查看编码是否修正,如果修正的话如下图:(恭喜你编码至少没问题了)

7.Hive启动
hive metastore 服务端启动命令:
hive --service metastore -p <port_num>
如果不加端口默认启动:hive --service metastore,则默认监听端口是:9083 。
加&后端启动

8.Hive测试
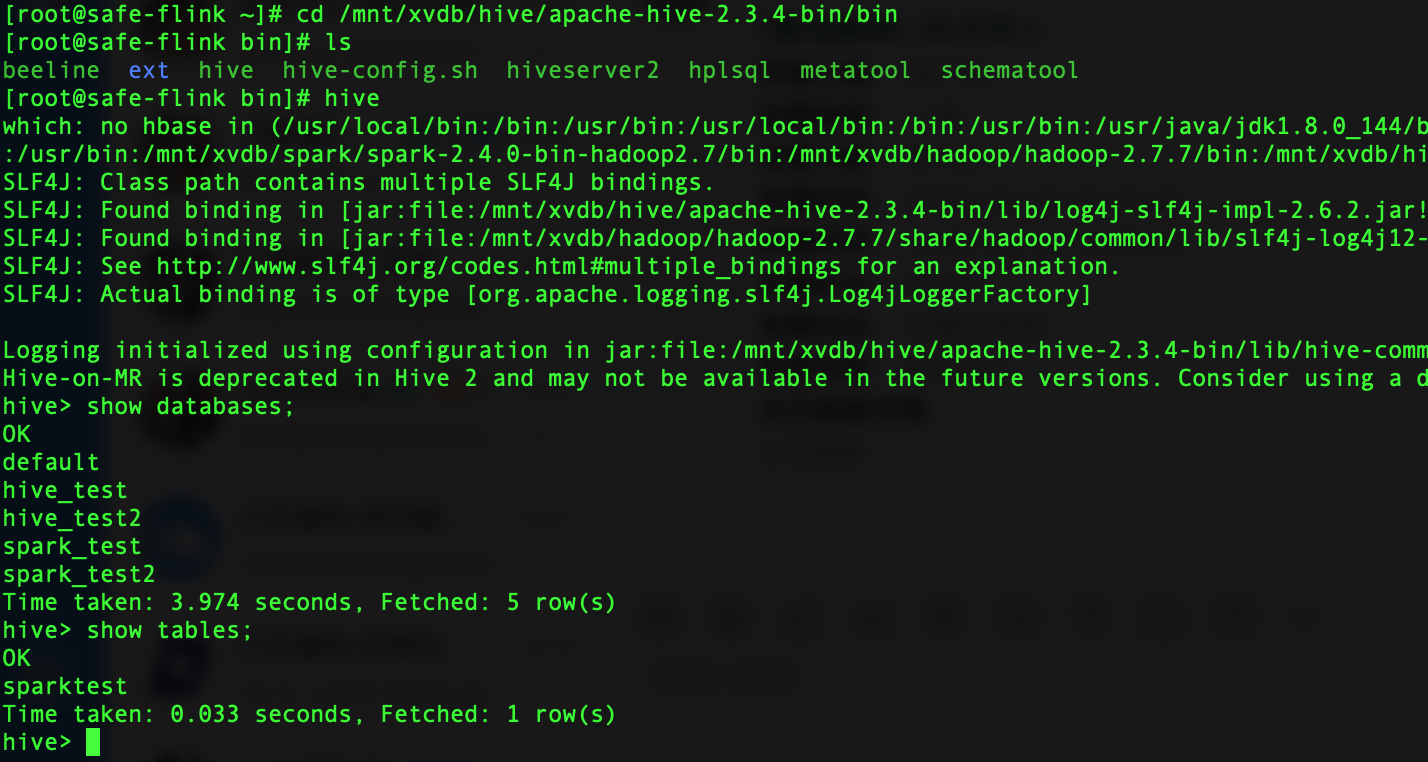
运行./bin/hive
在命令窗口中输入以下脚本进行简单测试:
show databases;
如果没有创建任何DB的话默认只有default。

Spark安装配置
1.Spark官网下载压缩包,解压后如下图

2.驱动配置:
因为Spark要访问Hive的数据库,而Spark的数据库被我们替换为了mysql,所以Spark也同样要依赖mysql的驱动jar,将mysql-connector-java-5.1.46.jar放到/mnt/xvdb/spark/spark-2.4.0-bin-hadoop2.7/jars目录下。
3.万年不变的配置环境变量:
vim /etc/profile
export SPARK_HOME=/mnt/xvdb/spark/spark-2.4.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
4.万年不变的配置Spark的配置文件:
因为Spark要访问Hive的数据库,这里要把Hive的配置文件hive-site.xml拷贝至Spark的配置文件目录下
/mnt/xvdb/spark/spark-2.4.0-bin-hadoop2.7/conf

5.启动spark
./sbin/start-all.sh

6.Spark测试
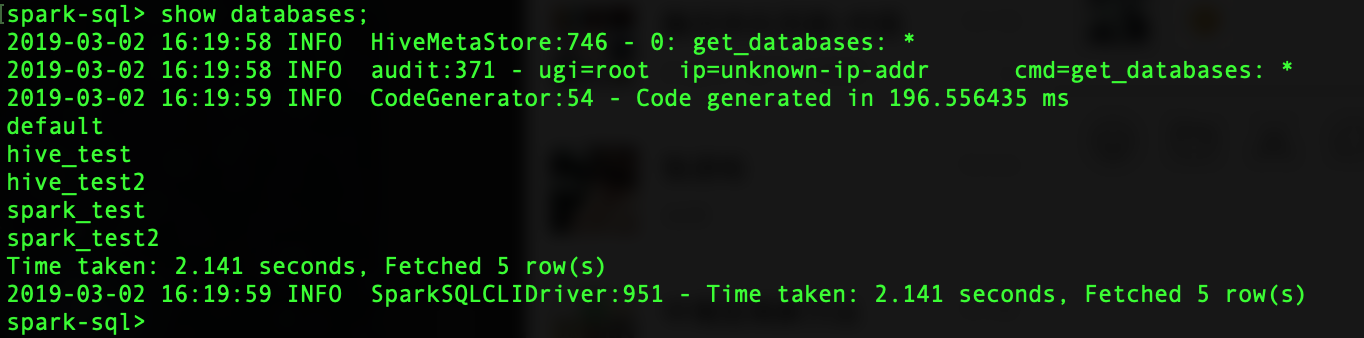
运行./bin/spark-sql
启动上述命令后在控制台输入show databases;
成功的情况下可以看到Hive中创建的database

7.Spark加载数据
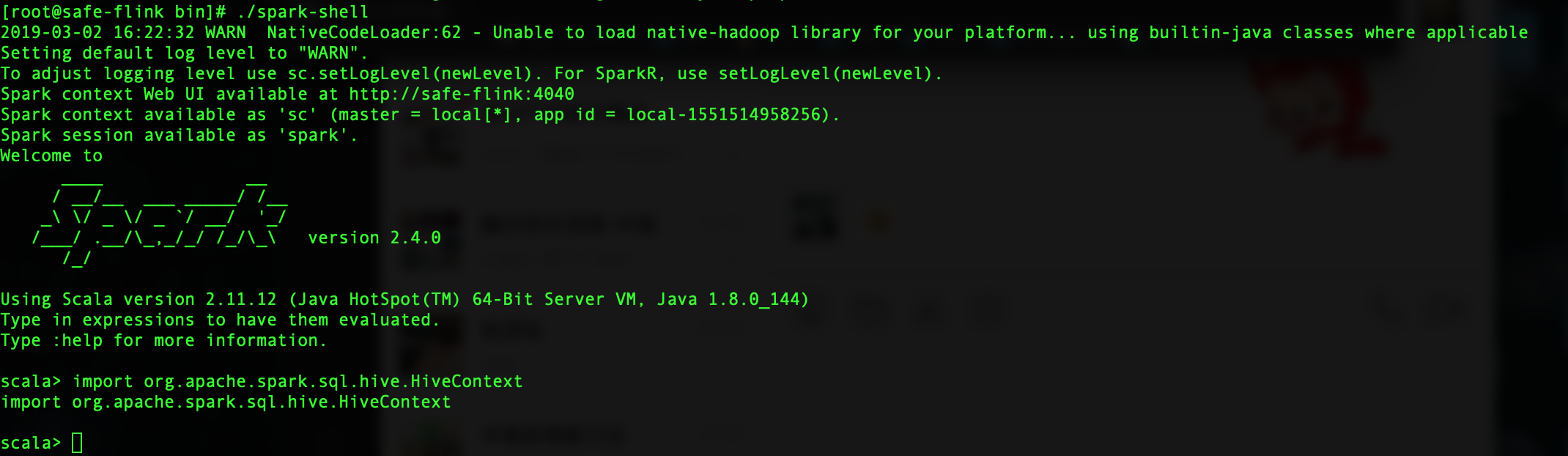
运行./bin/spark-shell

输入import org.apache.spark.sql.hive.HiveContext看下你的spark版本是否支持hive,如果显示
import org.apache.spark.sql.hive.HiveContext的话说明你的spark版本是支持hive的,否则你就要换版本或者自行编译带hive的spark版本,否则没法正常对接Hive。
依次执行下面脚本
//创建HiveContext
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
//加载csv或者json格式的文本数据,因为mongoDB中的一些特殊字段类型(如下图)会导致数据导入失败,所以这里推荐用csv格式。
val df = sqlContext.read.format("csv").option("header", "true").load("/mnt/xvdb/druid/slf_data/message_center.message_ali_test.csv")
JSON数据的特殊格式会导致spark导入数据的时候有问题

//打印数据(可以不执行,只是验证是否加载的数据正确与否)
df.show

//保存数据到表,注意要用hive中创建的schema,否则hadoop中找不到数据文件,原因不详
df.write.saveAsTable("hive_test.message_ali_csv_test2");

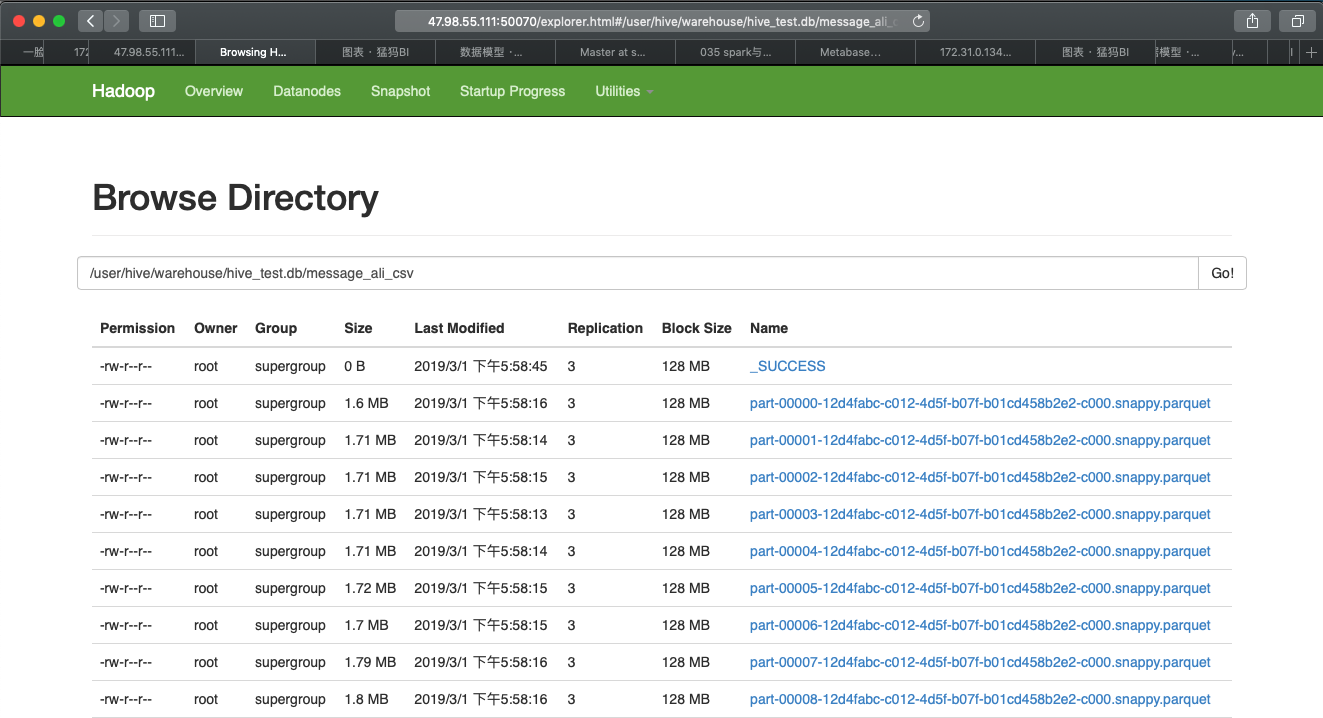
执行完成后可以在hadoop中看到对应的数据文件

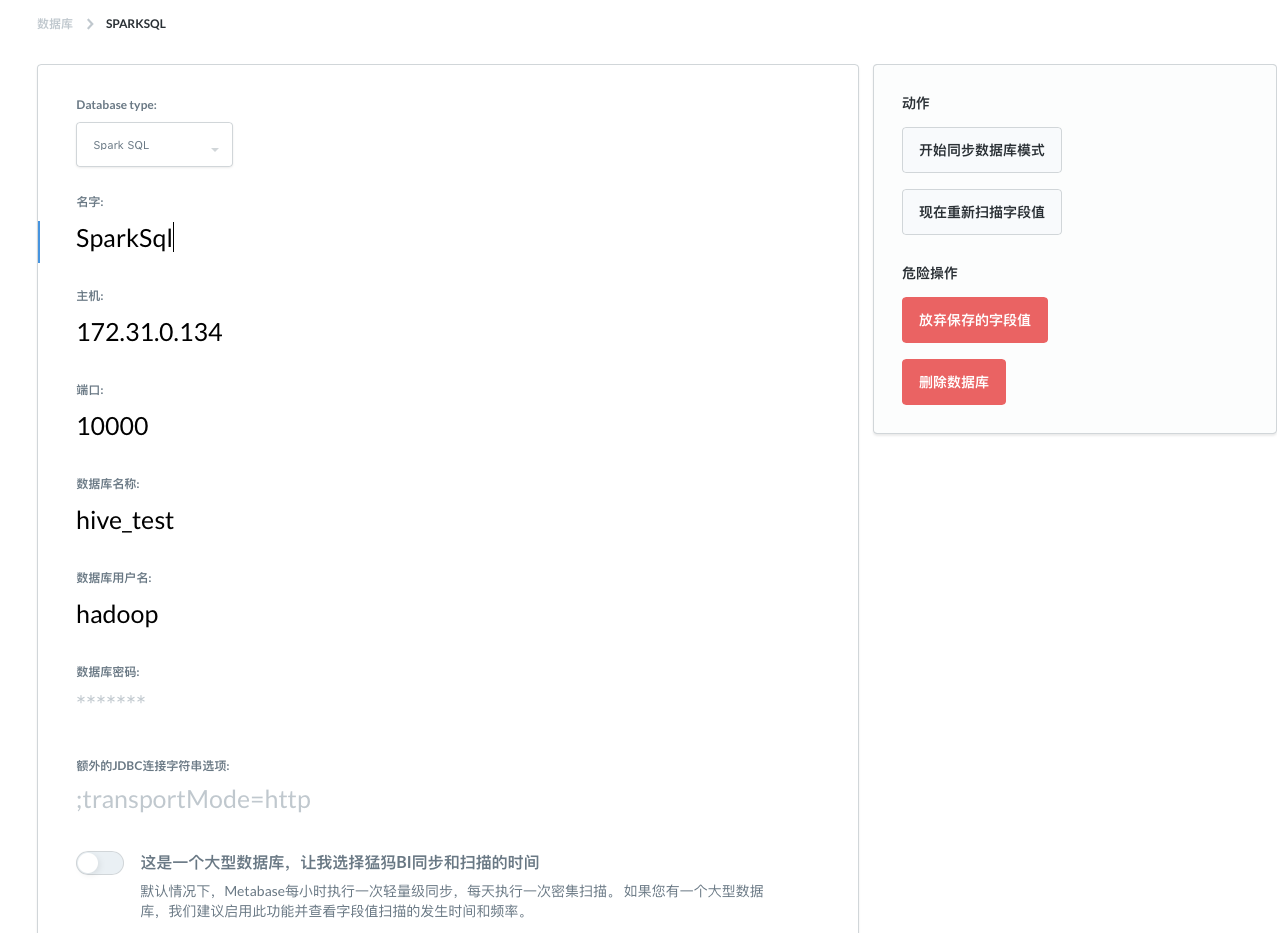
Metabase对接Spark
Metabase对接Spark的配置如下:

如果配置信息正确无误,但是保存时候提示超时或者是吧,很有可能是因为你没有开启thriftserver服务,该服务开启后方能对外提供JDBC式的访问,启动脚本如下:
./sbin/start-thriftserver.sh

性能简单对比
获取以下截图的时候的数据情况如下:
message_ali_csv位于hive,数据记录数为750万+
message_ali位于mongodb,数据记录数为800万+
查询spark

查询mongdb

通过以上对比可以看出,数仓的性能优势还是很明显的
Attachments:
 image2019-3-2_13-5-28.pngimage2019-3-2_13-10-31.pngimage2019-3-2_13-16-25.pngimage2019-3-2_13-17-42.pngimage2019-3-2_13-17-50.pngimage2019-3-2_13-22-24.pngimage2019-3-2_13-36-5.pngimage2019-3-2_13-37-13.pngimage2019-3-2_13-38-50.pngimage2019-3-2_13-41-52.pngimage2019-3-2_13-42-17.pngimage2019-3-2_14-12-18.pngimage2019-3-2_15-42-34.pngimage2019-3-2_15-53-9.pngimage2019-3-2_16-2-32.pngimage2019-3-2_16-18-12.pngimage2019-3-2_16-20-11.pngimage2019-3-2_16-23-7.pngimage2019-3-2_16-33-0.pngimage2019-3-2_16-36-6.pngimage2019-3-2_16-36-49.pngimage2019-3-2_17-8-0.pngimage2019-3-2_17-9-36.pngimage2019-3-2_17-12-19.pngimage2019-3-2_17-14-46.pngimage2019-3-2_17-17-3.pngimage2019-3-2_17-25-36.pngimage2019-3-2_17-26-38.pngimage2019-3-2_17-34-45.pngimage2019-3-2_17-39-43.pngimage2019-3-2_17-42-41.pngimage2019-3-2_17-43-23.png
image2019-3-2_13-5-28.pngimage2019-3-2_13-10-31.pngimage2019-3-2_13-16-25.pngimage2019-3-2_13-17-42.pngimage2019-3-2_13-17-50.pngimage2019-3-2_13-22-24.pngimage2019-3-2_13-36-5.pngimage2019-3-2_13-37-13.pngimage2019-3-2_13-38-50.pngimage2019-3-2_13-41-52.pngimage2019-3-2_13-42-17.pngimage2019-3-2_14-12-18.pngimage2019-3-2_15-42-34.pngimage2019-3-2_15-53-9.pngimage2019-3-2_16-2-32.pngimage2019-3-2_16-18-12.pngimage2019-3-2_16-20-11.pngimage2019-3-2_16-23-7.pngimage2019-3-2_16-33-0.pngimage2019-3-2_16-36-6.pngimage2019-3-2_16-36-49.pngimage2019-3-2_17-8-0.pngimage2019-3-2_17-9-36.pngimage2019-3-2_17-12-19.pngimage2019-3-2_17-14-46.pngimage2019-3-2_17-17-3.pngimage2019-3-2_17-25-36.pngimage2019-3-2_17-26-38.pngimage2019-3-2_17-34-45.pngimage2019-3-2_17-39-43.pngimage2019-3-2_17-42-41.pngimage2019-3-2_17-43-23.png















 1881
1881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}