







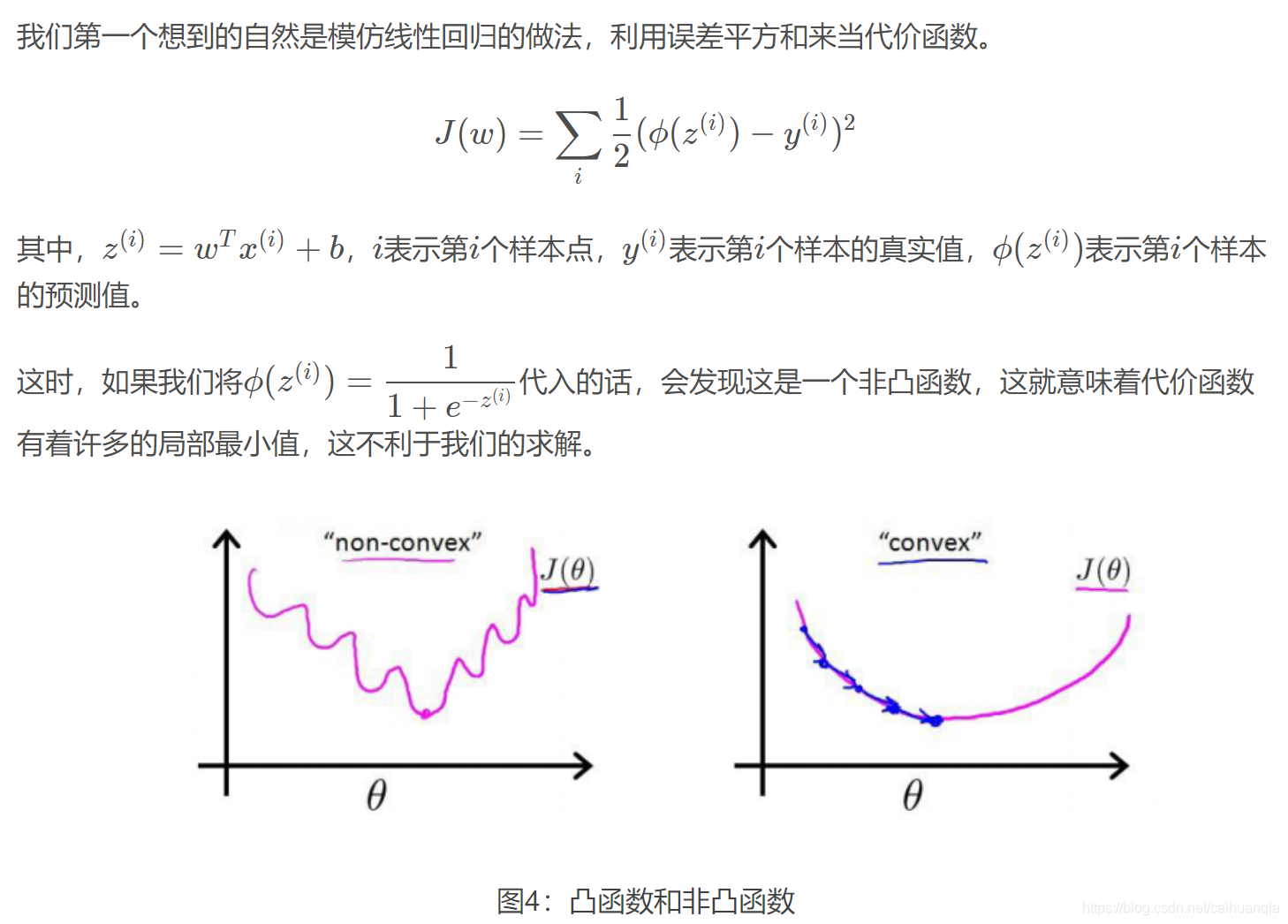
一句话概括:
1、logistic回归假设数据服从伯努利分布,通过极大似然法,运用梯度下降求解参数,从而实现分类。
2、梯度下降就是通过对代价函数求导,得到梯度的方向,也就是代价下降最快的方向,然后使得参数沿着该方向更新就可以使得代价下降最快。
之前一直在想逻辑回归为啥跟神经网络差不多,其实,他们本来就差不多~~只是区别在神经网络可能有多层,逻辑回归只有一层。
可以将Logistic Regression看做是仅含有一个神经元的单层的神经网络!
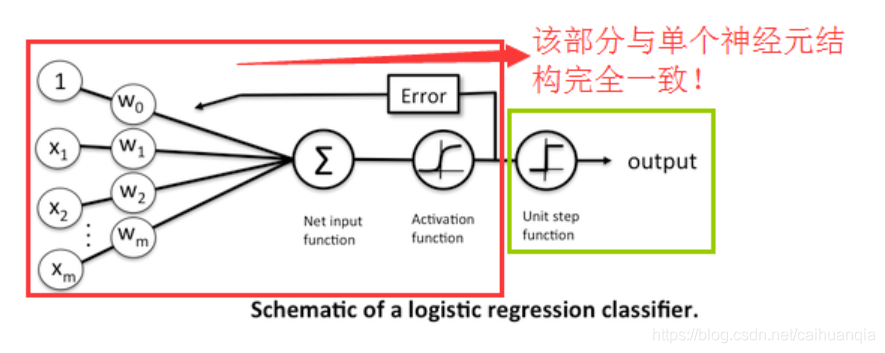
逻辑回归
包含了5个点 1:逻辑回归的假设,2:逻辑回归的损失函数,3:逻辑回归的求解方法,4:逻辑回归的目的,5:逻辑回归如何分类
下面先一一解答:
1、假设
假设1伯努利分布指的是对于随机变量X有, 参数为p(0<p<1),如果它分别以概率p和1-p取1和0为值。EX= p,DX=p(1-p)。
假设2 样本为1的概率是—sigmoid; 0就是1-p
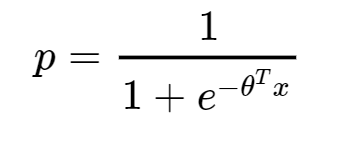
逻辑回归的最终形式也就是得到上述p。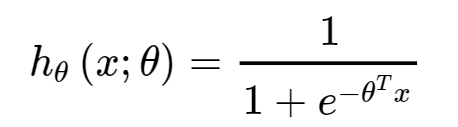
普通的逻辑回归只能用于二分类,,如果用于多分类,就采用softmax loss。也是很简单,多分类,自然参数量增多,梯度下降也是对不同的参数进行下降,对loss函数进行求导。与二分类基本无异。
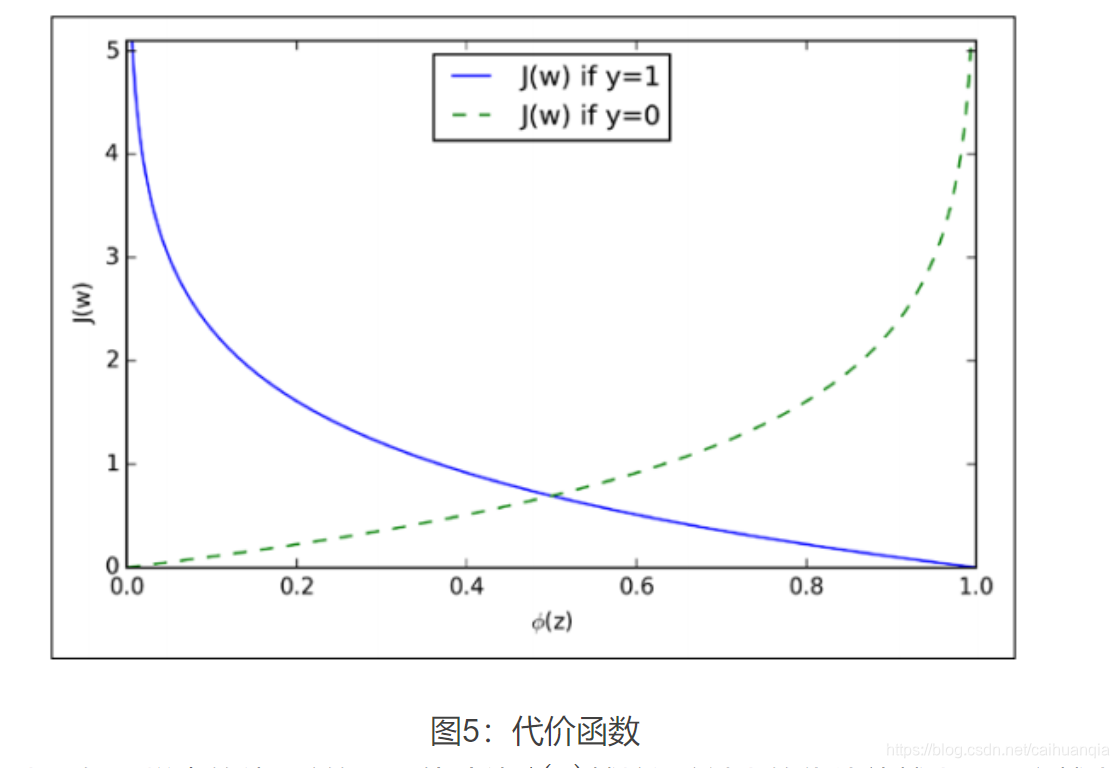
2、逻辑回归损失函数
损失函数一般有四种,平方损失函数,对数损失函数,HingeLoss0-1损失函数,绝对值损失函数
对数损失函数—极大似然函数:
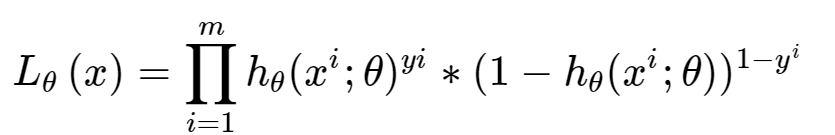
极大似然函数就是求出来的两个类别的概率,正类的概率的积 -----越大越好------取相反数 就越小越好-----作为loss.
采用梯度下降进行求解
方式:随机梯度下降、批梯度下降
随机梯度下降:优点:更新快 ,可能找到更好的局部最优解;缺点是每次更新可能并不会按照正确的方向进行, 参数具有高方差, 从而导致损害函数剧烈波动
批梯度下降:会获得全局最优解,缺点计算量大,更新一次参数需要遍历所有的数据。更新较慢。
小批量梯度下降结合了sgd和batch gd的优点,每次更新的时候使用n个样本。减少了参数更新的次数,可以达到更加稳定收敛结果,一般在深度学习当中我们采用这种方法
为什么选择 极大似然函数进行梯度下降而不是平方损失函数?m
这个问题有点像在问分类问题为什么不采用平方损失函数而采用交叉熵损失 ???
**分类一版采用sigmoid(二分类的话),那么,平方损失函数的导数-- 对sigmoid求导,那么f’ = f * (1-f),所以如果x比较大,那么就趋于饱和,梯度会非常小。**交叉熵损失的导数是线性的,所以适合。
二分类的话就是得到一个0-1的数。正类的话越接近1越好,负类的话越接近0越好。
逻辑回归的目的:
逻辑回归的目的:将数据进行二分类,提高准确率。
逻辑回归的优缺点:
在这里我们总结了逻辑回归应用到工业界当中一些优点:
1、形式简单,模型的可解释性非常好。从特征的权重可以看到不同的特征对最后结果的影响,某个特征的权重值比较高,那么这个特征最后对结果的影响会比较大。
2、模型效果不错。在工程上是可以接受的(作为baseline),如果特征工程做的好,效果不会太差,并且特征工程可以大家并行开发,大大加快开发的速度。
3、训练速度较快。分类的时候,计算量仅仅只和特征的数目相关。并且逻辑回归的分布式优化sgd发展比较成熟,训练的速度可以通过堆机器进一步提高,这样我们可以在短时间内迭代好几个版本的模型。
4、资源占用小,尤其是内存。因为只需要存储各个维度的特征值,。
5、方便输出结果调整。逻辑回归可以很方便的得到最后的分类结果,因为输出的是每个样本的概率分数,我们可以很容易的对这些概率分数进行cutoff,也就是划分阈值(大于某个阈值的是一类,小于某个阈值的是一类)。
但是逻辑回归本身也有许多的缺点:
准确率并不是很高。因为形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布。
很难处理数据不平衡的问题。举个例子:如果我们对于一个正负样本非常不平衡的问题比如正负样本比 10000:1.我们把所有样本都预测为正也能使损失函数的值比较小。但是作为一个分类器,它对正负样本的区分能力不会很好。
处理非线性数据较麻烦。逻辑回归在不引入其他方法的情况下,只能处理线性可分的数据,或者进一步说,处理二分类的问题 。
逻辑回归本身无法筛选特征。有时候,我们会用gbdt来筛选特征,然后再上逻辑回归。
1.概念
逻辑斯蒂回归又称为“对数几率回归”,虽然名字有回归,但是实际上却是一种经典的分类方法,其主要思想是:根据现有数据对分类边界线(Decision Boundary)建立回归公式,以此进行分类。
2.特点
-
优点:计算代价不高,具有可解释性,易于实现。不仅可以预测出类别,而且可以得到近似概率预测,对许多需要利用概率辅助决策的任务很有用。
-
缺点:容易欠拟合,分类精度可能不高。
-
适用数据类型:数值型和标称型数据。
几个关键点:sigmoid函数—对数函数,通过极大似然函数(后验概率)来使得属于该类的概率越大越好,因此得到的函数表达式取反就得到了loss函数,所以loss函数越小越好。–loss函数下面的推导是通过梯度下降-链式法则得到的。通过求loss函数对W的导数。因此可以通过W来更新logistic函数进行分类。
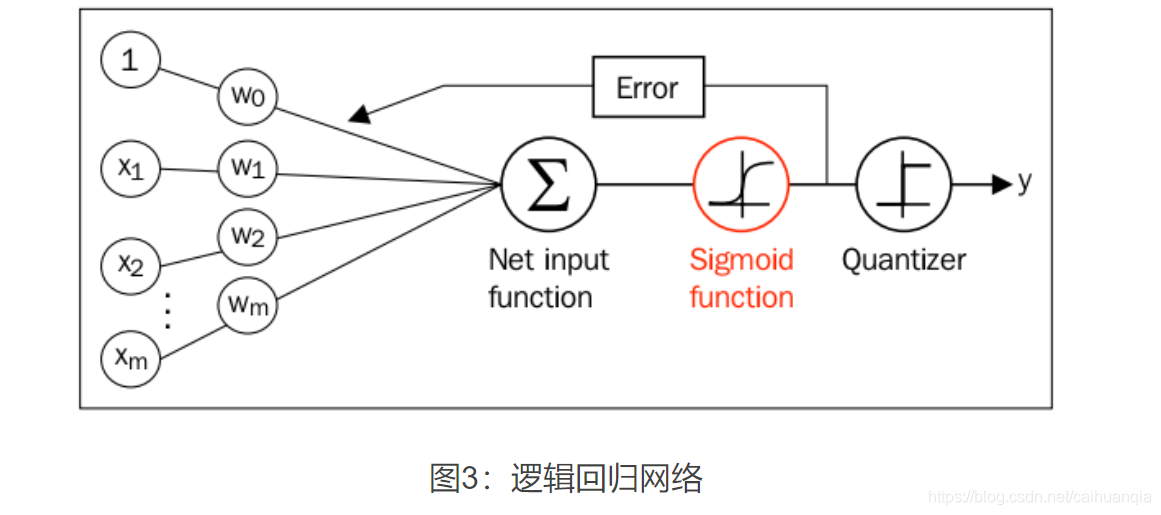
极大似然函数,L越大,说明在w和x确定下,选择某个Y的可能性越大,总的乘积越大,说明w越可信,所以最终选择这个w。
下面的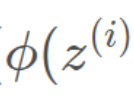 代表的是类1的输出。则类2的输出是1-上述输出,—伯努利分布----
代表的是类1的输出。则类2的输出是1-上述输出,—伯努利分布----
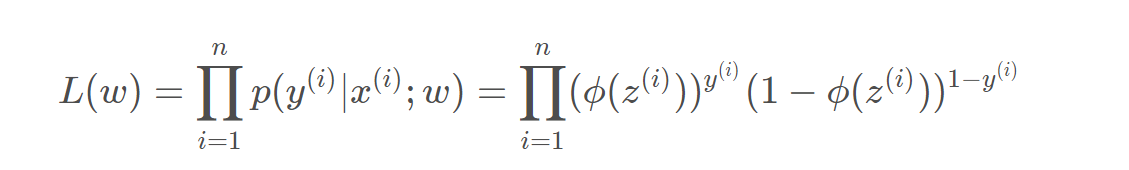
取对数
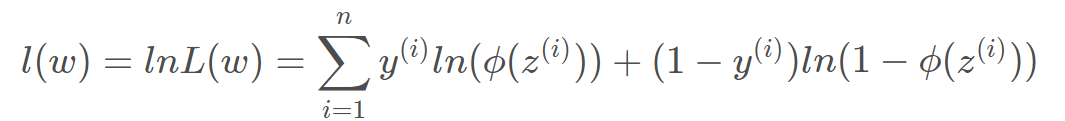
加上负号,就变成了Loss函数,越小越好。
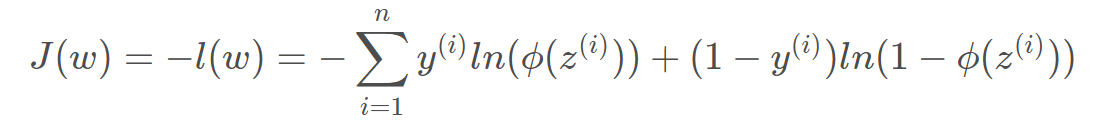
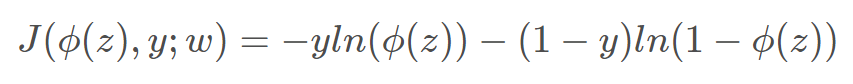
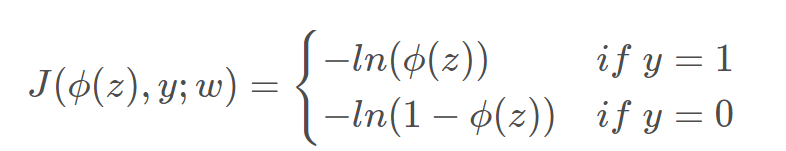
梯度下降-----代价函数求导得到梯度的方向,从而对参数进行更新,参数的变化就可以使得代价函数下降最快。

sigmoid函数求导得到:
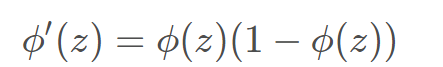

梯度的负方向就是代价函数下降最快的方向, 为什么是上述式子呢?J就是代价函数的导数,α是学习率/步长,也就是每一次走多大的步伐,往山下去
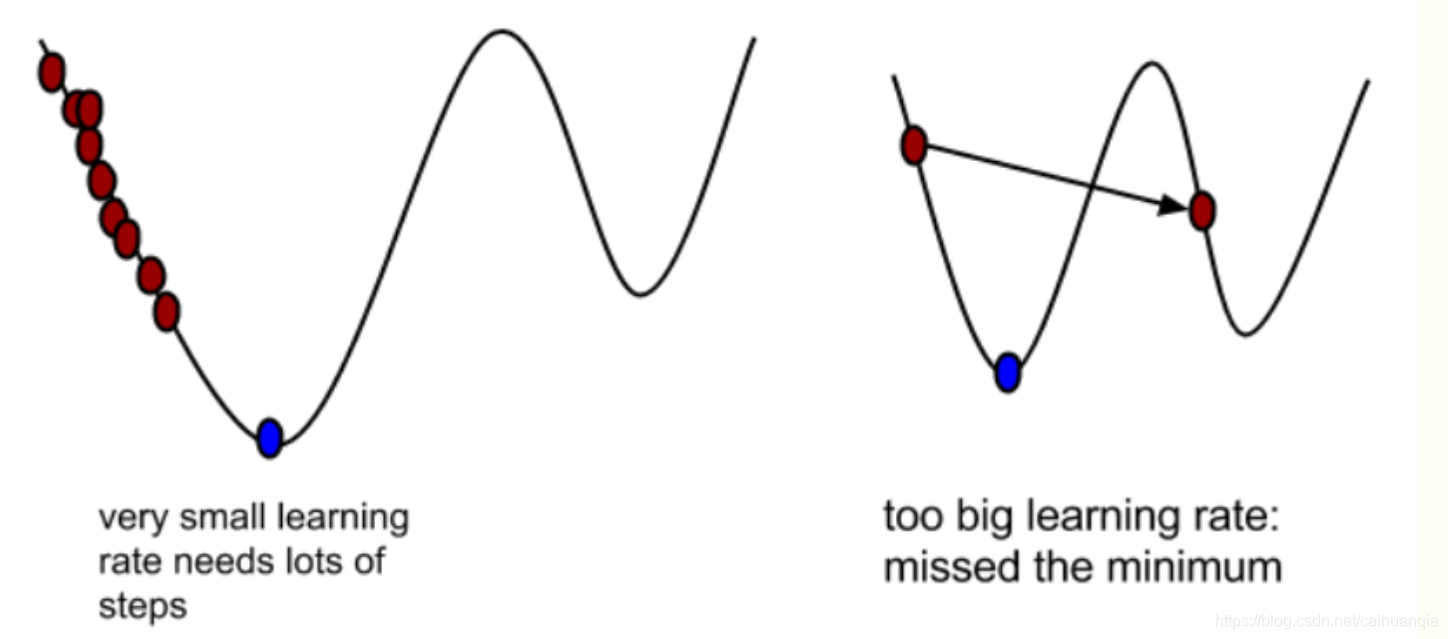
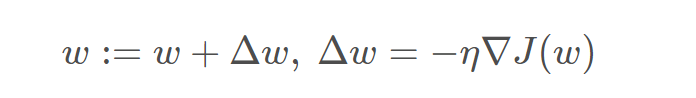
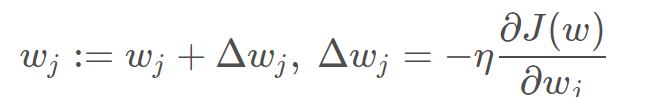
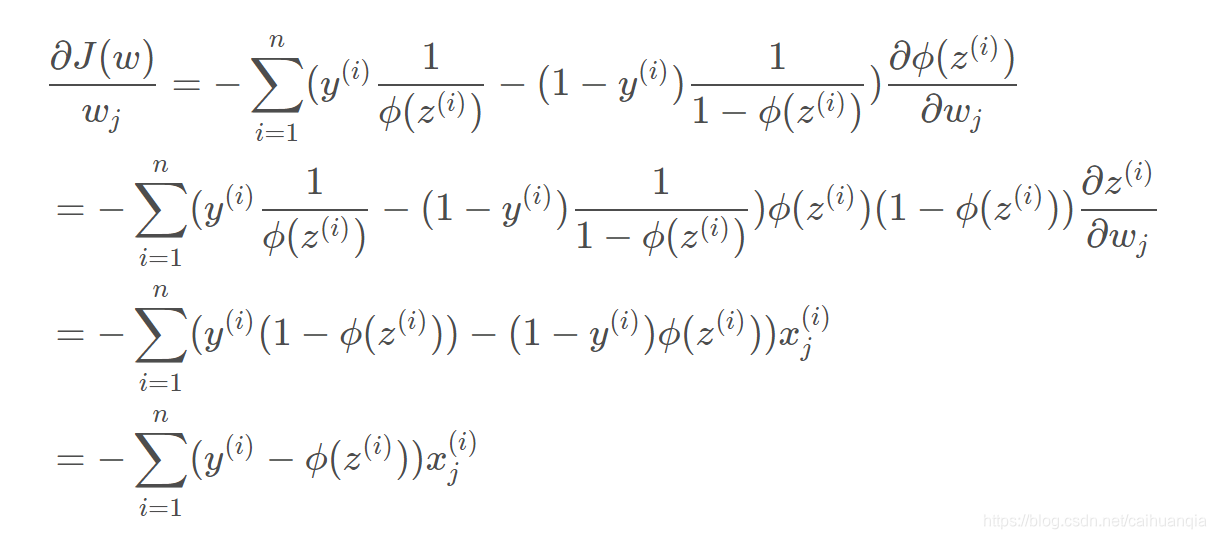
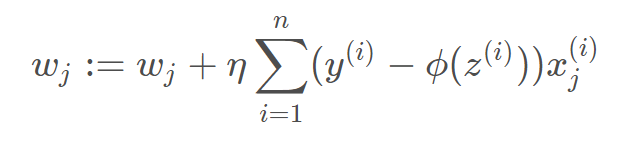
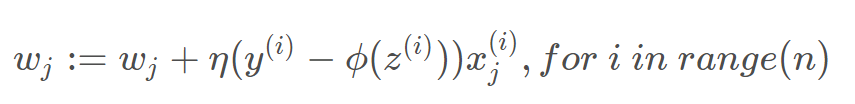
梯度下降
梯度下降就是对于每一个参数量的更新是利用损失函数对该参数的导

参考,这个文章写的好

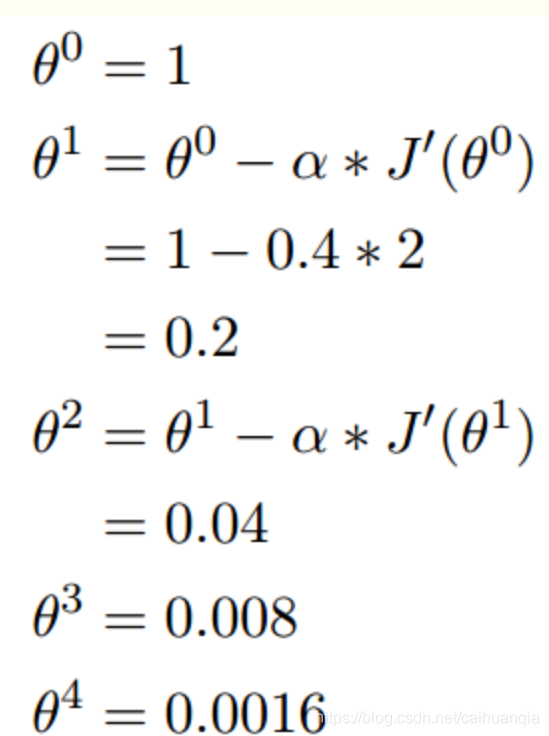
还蛮简单的。哈哈
多变量梯度下降----同样的道理,就是两个一起下降而已。

求导注意要分别进行微分,因为有两个变量。

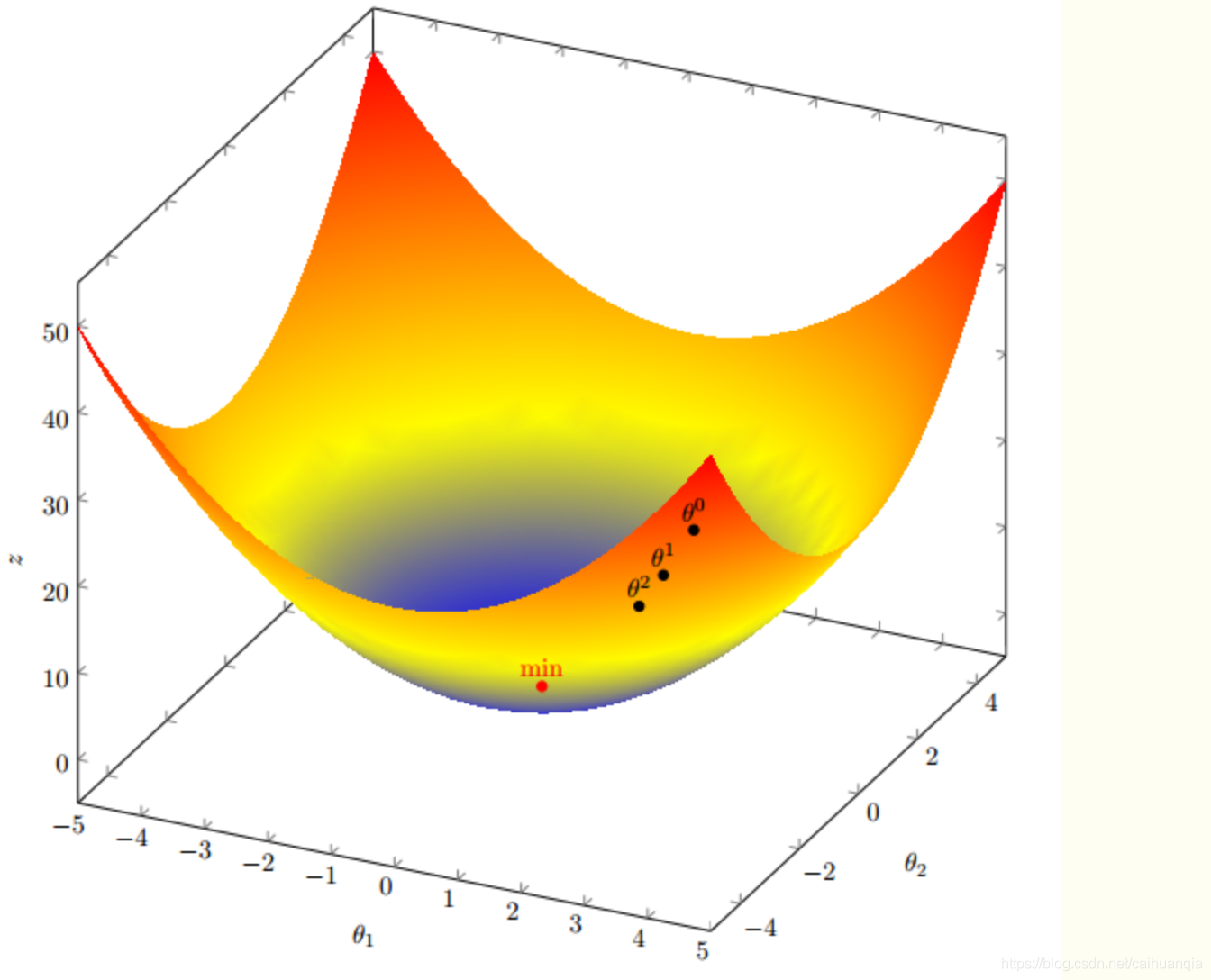
注意是对代价函数进行求导得到的梯度,也就是代价函数下降最快的方向—然后作用到权重参数上。
具体的梯度下降的过程、公式、代码
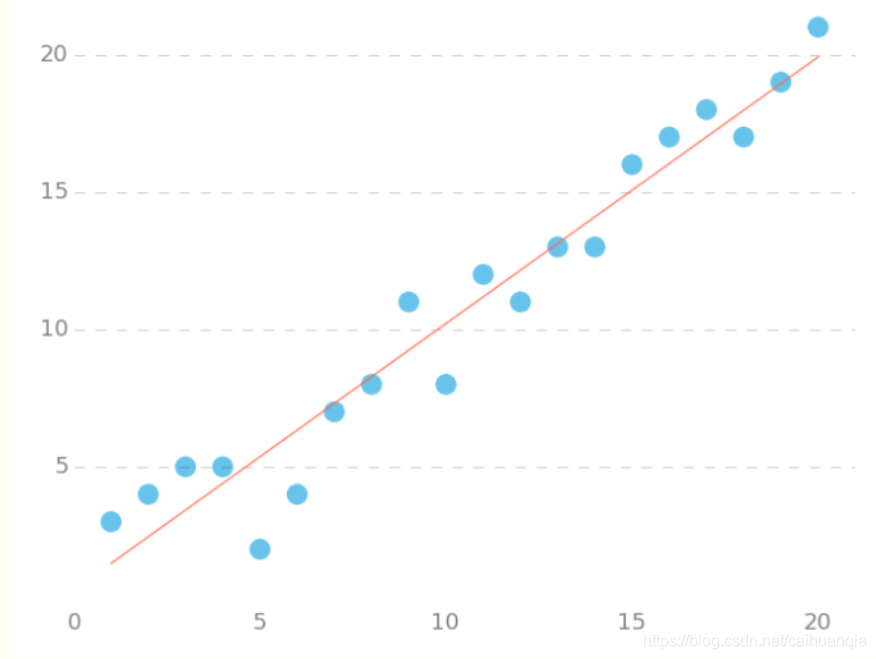
首先是一个线性回归的case:
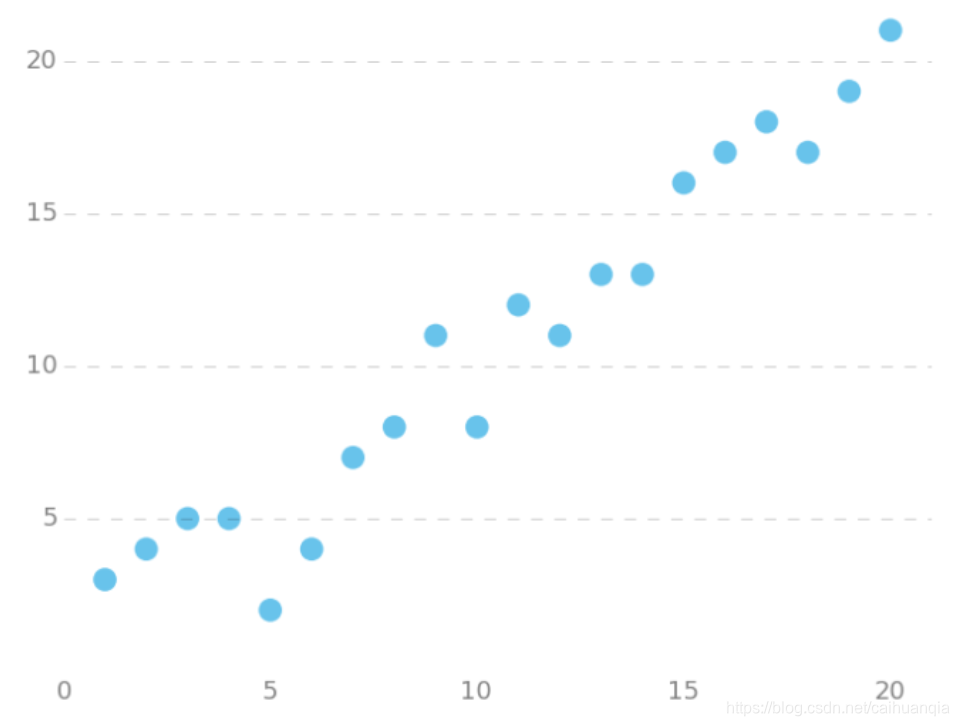
用梯度下降法来拟合出这条直线!

m是数据集中点的个数
½是一个常量,这样是为了在求梯度的时候,二次方乘下来就和这里的½抵消了,自然就没有多余的常数系数,方便后续的计算,同时对结果不会有影响
y 是数据集中每个点的真实y坐标的值
h 是我们的预测函数,根据每一个输入x,根据Θ 计算得到预测的y值,即
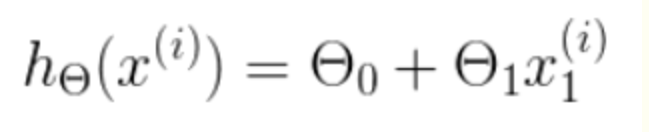
我们要求的就是hθ,所以变量有两个。是一个多变量的梯度下降问题,求解出代价函数的梯度,也就是分别对两个变量进行微分
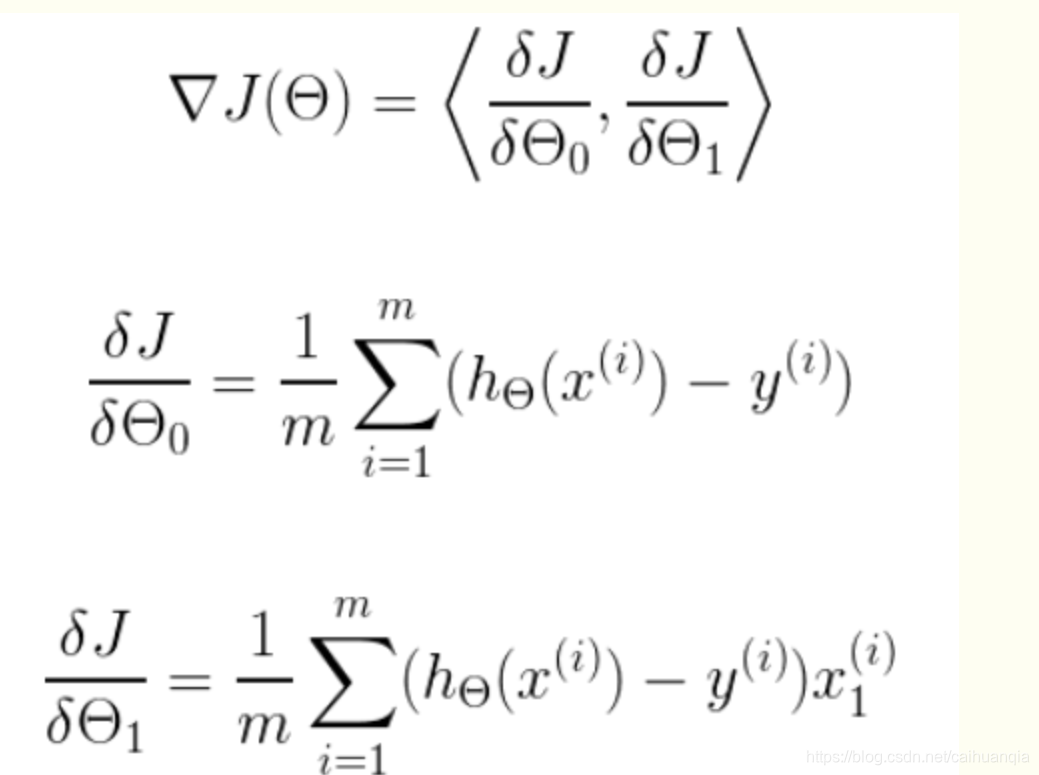
明确了代价函数和梯度,以及预测的函数形式。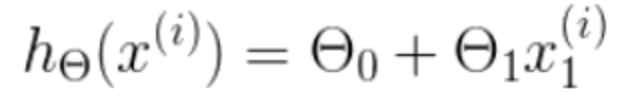
代价函数的形式,平方相当于矩阵转置乘以原矩阵,以及求导后的形式:
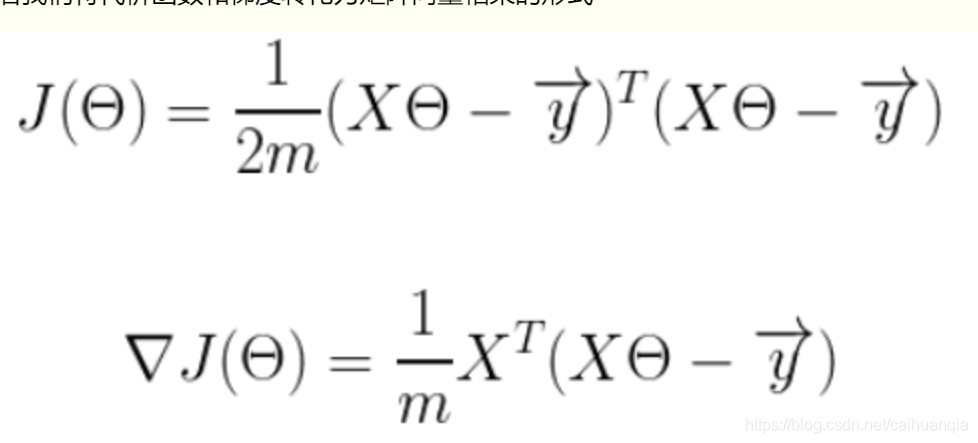
所以,求得梯度只需要根据下面的式子带入对应的x既可以求到梯度。
import numpy as np
# Size of the points dataset.
m = 20
# Points x-coordinate and dummy value (x0, x1).
X0 = np.ones((m, 1))
X1 = np.arange(1, m+1).reshape(m, 1)
X = np.hstack((X0, X1))
# Points y-coordinate
y = np.array([
3, 4, 5, 5, 2, 4, 7, 8, 11, 8, 12,
11, 13, 13, 16, 17, 18, 17, 19, 21
]).reshape(m, 1)
# The Learning Rate alpha.
alpha = 0.01
def error_function(theta, X, y):
'''Error function J definition.'''
diff = np.dot(X, theta) - y
return (1./2*m) * np.dot(np.transpose(diff), diff)
def gradient_function(theta, X, y):
'''Gradient of the function J definition.'''
diff = np.dot(X, theta) - y
return (1./m) * np.dot(np.transpose(X), diff)
def gradient_descent(X, y, alpha):
'''Perform gradient descent.'''
theta = np.array([1, 1]).reshape(2, 1)
gradient = gradient_function(theta, X, y)
while not np.all(np.absolute(gradient) <= 1e-5):
theta = theta - alpha * gradient
gradient = gradient_function(theta, X, y)
return theta
optimal = gradient_descent(X, y, alpha)
print('optimal:', optimal)
print('error function:', error_function(optimal, X, y)[0,0])















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









