







Feature list:
1. 支持Set/Get/Replace/Update, 优化编译下默认16级冲突下单进程下Set/Get可达170w次/s。(理论上只要不达到内容的带宽限制,而且是多核的机器下性能是随线进程数陪增)
2. 支持多程下操作(可预见低的出错概率)
3. 支持CAS弱一致性检测(需要编译时开启)
4. 支持二进制文件导出/导入
5. 支持遍历处理(回调)
6. 可以自定义最大可冲突级数/单个桶最大长度(需要重新编译库)
注意:下面版本是32位机上实现的,64位机需要做些兼容修改
提供运维工具
a) 支持Bindump/Binrestore:共享内存保存到二进制文件和从二进制文件恢复到内存(支持跨机器操作)
b) 查看当前使用率与各级桶的使用率( 未实现 )
c) 修改为只读、只写模式( 未实现 )
d) 支持远程恢复与同步( 未实现 )
实现
1. 预设N个大素数(PRIMER_TABLE,目前取值是1000037~1001323,共100个,最大数为1000,000*100 = 1亿个元素,默认初始化为16级hash)
2. 第一个素数作为一个桶长度,存储hash后的value时,就是以%素数来取模
3. 存储共享内存是一个线性空间,所以要先计算好每列的偏移量
(PRIMER_TABLE_OFFSET[i] = ∑PRIMER_TABLE[i])
4. Value需要定义固定长度,不能是指针指向外一个内存块
5. Hash值计算 ( key + Factor*k )%L, Factor初设为一个素数作为hash因子,用于扩散hash 值,减少冲突发生 1 11%10(后继可以考虑更好的hash算法 )
6. 支持char* hash( time33 hash算法)
7. 每次set都要先遍历k阶是否key存在,插入中O(k)
8. 为了确保性能,可设置共享内存块不允许换出
9. 大小限制,32位机器受单个进程的进程空间限制,最大为4G。共享内在需要映射到进程空间,考虑到进程本身也需要使用到相应的内存,所以尽量限制在2G以下
设计理念:1)尽可能高的性能 2)能够提供尽可能的多线程安全 3)数据持久化
冲突处理
a) 先从第一个桶hash,如果当前位置已设置
(第一个桶hash + maxline*factor )%1000037
b) 再向下一个桶hash,按下一个桶的大素数来取余
c) 最大可冲突次数为hash级数( 可冲突次数越多,占满率越高,但是影响性能
优点:
1.非常地快!基于共享内存可以多进程共享
2.基于一维线性空间实现可从外部copy数据备份/恢复
3.空间利用率高,可达90%
4.Set/Get在优化编译后性能高
缺点:
1. 在设定的多次hash级内都冲突的话就插入不成功,但是机率很少。但是要慎重选择hash级数(建议起始级数设定16级,下面有数据说明)
2. 由于对同一个key的取value操作不是原子的,在非常低的概率下,可能在取一个key的同时在对这个key做set,导致只取值不完整(但是需要对一个key的操作在1/170w s内 )。除非是key很少,而且频繁访问(这种操作是建议加锁)
3. 单进程共享内在需要限制在4G(最好是2G)以内
4. Key不能为0
测试数据
(4字节的key, 12个字节value,直接rand(),成生的随机数可能不够足够精确)
测试环境:
Intel(R) Xeon(R) CPU E5405 @ 2.00GHz(4核)
16G内存DDR3,内存带宽 =(1066/8)×64×8=68224Mbit/8 ~ 8GB/s
测试期间CPU 只使用到一个核 100%
|
| 10 | 16 | 20 | 32 |
| 总容量 | 1kw(~100M) | 1.6kw(~200M) | 2kw(~250M) | 3.2kw(400M) |
| 插入失败时的Rand次数 | 6,539,556 | 12,786,141 | 16,604,767 | 28,811,470 |
| 插入元素 | 6,529,720 | 12,748,311 | 16,540,688 | 28,618,666 |
| 耗时(未开-O3) | 15,536,487us | 49,602,499us | 81,243,290us | 210,149,843us |
| 存取率(未开-O3) | ~42w/s | ~25.7w/s | ~20w/s | ~13w/s |
| 耗时(打开-O3) | 2,910,194us | 7,379,382us | 15,267,184us | 35,694,707us |
| 存取率(打开-O3) | ~225w/s | ~175w/s | ~109w/s | ~80w/s |
| 利用率 | 0.6529 | 0.796655 | 0. 826898 | 0.894123 |
| 是否达上限 | 是 | 是 | 是 | 是 |
16级( 10次测试时间)
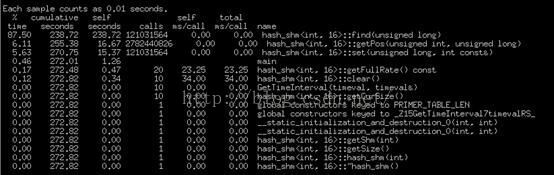
从测试数据可得出结论:
1) 在正式使用时要打开O3的标记编译,可以编译成一个独立库来使用
2) 使用级数越多,使用率越高,性能也随之下降
3) 由于优化编译后性能非常高,所以可以尽量使用多的冲突级,减少因冲突无法插入的情况,同时提高hash空间的使用率真
4) 初始化桶是取从1000037后素数,可以扩大桶的长度,从而减少级数
5) 默认使用16级,根据需要自己再提高使用级数,可预计处理量约为1.2kw
冲突处理
问题:不同的字符串,可能hash出同一个值
Time33的算法,大概是 100w数据,有100~150个冲突
测试:
try set times:1000000
conflict times:105
conflict rate:0.000105
不同hash算法的测试结果:
测试条件:随机 32位数,%lu-%i-%j 的形式生成字符串,100w(排除因级数不够无法插入的情况,因开启测速gprof/-g, 所以性能有很大影响 )
| Hash 函数 | 来源 | 结果 | 说明 |
| time33_ hash | gcc/redis | hash total size:10001108 use time: 9940793us
try set times:1000000 conflict times:112 conflict rate:0.000112 | 最简单实现 |
| bobjenkins_hash | memcache | hash total size:10001108 use time: 9407349us
try set times:1000000 conflict times:128 conflict rate:0.000128 | 通过多次rot将key散列,但是从测试效果来说不太明显 |
| blizzard_hash | 网上找的一个one-way hash | hash total size:10001108 use time: 9491830us
try set times:1000000 conflict times:125 conflict rate:0.000125 | 通过预生成一个查找表来生成hash,但是多了一层函数调用,在频率调用下反而速度有少少影响 |
| murmur_hash | levelDB | hash total size:10001108 use time: 8885562us
try set times:1000000 conflict times:120 conflict rate:0.00012 | 支持设置初始值可以生成多个不同的hash值,较为简洁 |
结论:
1. 从多个开源软件用到的hash函数抽出测试来看,对同一个字符串结果集做hash出的key冲突率都差不多(这里的冲突是指两个不同的字符串hash出同一个一样的32值)
2. 综合来说选择 murmur_hash 比较合适
3. 同样需要解决的一个问题:怎么处理两个不同的字符串hash出同一个值的情况?
解决:
1) 以同一个字符串str, 同时hash出三个值
h1 = murmur_hash( str, 0 );
h2 = murmur_hash( str, 1 );
h3 = murmur_hash( str, 2 );
2) h1 用作key的定位,计算hash要保存的位置。h2/h3作是比较值,即:对于一个key,需要满足三个hash值都一致时才认为是需要找的key
3) 对于不同的str1/str2, 如果三个值都一样发生的机率是 (150/1000000 )^3 ~ 0.000000000003375。即约为 1/30b的机率,基本可以忽略了!
多线、进程下一致性处理(未实现)
1. CAS机制:
a) 为每一个Node在Set的时候分配一个cas值(返回的Node和存储Node的cas值一样,每次要更新这个Node时要检查是否cas与取出来时一致
b) 如果打开了这项检查,需要强制传入模块带上一个unsigned int cas;字段
c) 只有在Update一个key的value时才会造成多线程冲突,只是Set/Get是不会的。单线程也不会
d) 增加步进的概念:cas每次自增每个线程都不一样,这样可以每个线程有一个确定变量,如果是由其它线程修改的一定与本线程的cas不一样
i. 每个线程/进程有一个初始化,如果有10个进程就是0 ~9
ii. 每次cas值增加都是按进程数来加,step[0] += 10,因为每个进程的cas都不会一样
iii. 缺点是需要额外的初始化
场景:线程T1对key1、线程T2对Key1并发Get更新了Value值后想Set回去,可能会出现后一个操作覆盖前一个操作值,而且这个值是涉及到事务性的。正确是应该是T1 Set完后,T2才能取,串行化操作
=》CAS就是解决这个问题,如果发现cas值不一样了,就会Set失败,需要重取再设置(假定某时刻T1 的cas值为9,T2 的cas值为10。如果没有步进时,T1处理后cas值为10,T2再处理就认为没有改变过)
=》一般情况下都不需要这样的事务性,所以是弱线程安全的(很少概率出现,即使出现这样的冲突也不会造成很在原影响
2. 弱线程安全
a) 在多线程使用下( 为每个线程生成一个成员对象操作)。在很低的概率下,可能会出现两个不同的key,hash出同一个值,并同时操作同一个value的node位置
b) 操作系统对同一个内存位置的操作不保证是串行化的,
c) 概率计算:由于每一个桶的取模素数都不一样,所以大约出现冲突概率是1/N(默认桶长取为100w,所以出现概率为 1/100w,而我们的并发处理不可能达到这个数量级)
3. 强线程安全
a) 情景1:Write Lock
i. 为了达到强线程安全,引入加锁机制
ii. 每个Node增加一个字段char bLock;( 可设置flag的一个位),每次在写的时候都设置为1,写完后再设置为0
iii. 当另一个线程对这个Node处理里就需要先判断是否被锁
b) 情景2:Update Lock
处理的Scale
1. 在默认16级的情况下大约能处理1.2kw的用户量,如果想提高处理能力可以
a) 扩展每个桶的长度 100w->1000kw
b) 增加级数
c) 注意系统内存量是否足够:容量*Value len。单进程共享内在需要限制在2G以内
d) 分布式处理,考虑到单机单进程受限于内存大小,所以数据一致性尽量考虑由上层处理。如多机按取模处理,每个机器只负责部分号段,或者实现一致性的算法为减少扩容影响
库级支持定时遍历处理
有一种使用场景,需要遍历Hash表里的所有元素并进行相关的操作。基本实现就是传入一个预设参数的函数指针:
初始版本:
Foreach( void (*callback)( const unsigned long _key, valueType& _value) );
但是发现,只能处理全局的一些外部变量,无法处理指定类成员。所以添加一个外部传入的param指针,使得可以传入到回调函数里处理
第二版:
Foreach( void (*callback)( const unsigned long _key, valueType& _value, void* param_out ), void* param_in );
解决了参数问题,还有一个运行时问题:如果每次遍历触发的元素较多,可能一次过处理量会很大!这里需要使用者注意,应该多加一个上次检查时间来触发。
定时扫描器功能
TimerCallBack( fn, timer_id, set_timeout, set_excute_time_interval );
a) 设置一个为定时器设定的回调函数fn与处理id timer_id, 在每个set_timeout触发时遍布所有元素,为每个超过set_excute_time_interval的Node调用一下回调函数fn
b) 每个Node需要有一个dwLastCheckTs字段
后续功能构想
2. 支持共享内存/内存/内在映射文件
3. 动态自动扩展=》rehash( redis实现 )
4. 运维工具
a) 格式化输出指定key-Value/全输出
ChsDB(Cola’s hash shm DB )基于以上版本的扩展版( 未实现 )
理念:数据先存共享内存再同步,实现一个轻量级高速key-value 数据库
1. 支持只读、只写模式(需要由提供的运维工具修改)
2. 支持定时数据快照snapshot(写本地文件)
3. 支持主-从(多从),主-主模式的数据同步
4. 库级支持定时遍历处理(回调)
错误处理
1.Share memory get failed
1) 检查系统共享内存量设置是否足够大( 减少级数或者
2) 是否有足够内存(级数*100w*sizeof(TemplateNode) )
3) 是未初始成每个线程一个对象(使用全局对象来操作,确保只操加载到进程空间一次)
共享内存操作
Ipcs –l 列出所有共享内存相关的信息
ipcs-m 列出本机使用的共享内存列表
ipcrm –M id 删除一个共享内存块
使用说明(附源码)
1. 初始化
1)定义存储的数据结构
struct HASH_MSG_INFO
{
unsigned int dwUin;
unsigned int dwLastCheck;
unsigned char ucFlag;
char ucResvered[7];
};
2) 生成对象
CHashShm< HASH_MSG_INFO > ht(123);
if( !ht. IsInitOK() )
return false;
(1)默认16级冲突,可自定义级数: CHashShm< HASH_MSG_INFO,32 > ht( key_t(123));
(2)设置步进:CHashShm< HASH_MSG_INFO,32,1 > ht(key_t(123));用于多线/进程下弱冲突处理
(3)使用全局变量的方式,确保只操加载到进程空间一次
2. Set/Get/Replace/Update
Set:如果Key不存在,则插入hash表,如果存在就返回失败(支持key类型为unsigned long,char*+len,string)
HASH_MSG_INFO hMsg;
hMsg.dwUin = 12345;
hMsg.dwLastCheck= 12345;
if(ht.Set( 12345, hMsg ) != HASHSHM_OK )
{…}
Else{…}
Get
HASH_MSG_INFO hMsg;
if(ht.Get( 12345, hMsg ) != HASHSHM_OK )
Replace: 如果Key不存在,则插入hash表,如果存在就替换
Update:在编译时打开CAS开关,会做线程数据检查,需要先Get。如果数据已经被修改则update失败
注:由于不支持从value查到key,所以value里最好有一个相同的key字段。如果是char/string类型的key,还需要是定长,不能是STL对象
3. 设置进程退出是detach共享内存
ht. SetBehavior(HASH_ENABLE_DETACH )
4. 遍历
//遍历hash shm中的所有在线列表
g_ht.Foreach( ProcMsgCheck, this );
ProcMsgCheck 是回调函数
void ProcMsgCheck( unsigned long key, ST_ON_STATE& value,void* param )
注意 value 直接引用共享内在的位置!!
头文件:
#ifndef _COLALIANG_HASH_SHM_H_
#define _COLALIANG_HASH_SHM_H_
//-------------------------------------------
//Cola's Hash Shm Library 1.03
//colaliang( SNG Instant Messaging Application Department )
//last update: 2012-12-27
//Makefile
// g++ -O3 -c hash_shm.cpp
// ar cq libchs.a hash_shm.o
//Enable extra function:
//1. CAS
// -DHASH_SHM_ENABLE_CAS
//2. TIMER_CALL_BACK
//-DHASH_SHM_ENABLE_TCB
//多级hash实现解释
//
//
// i
//PRIMER_TABLE: 2 3 5 7 11 13 17 ( bucket size, using primes )
//PRIMER_TABLE_TATAL: 0 2 5 10 17 28 41 ( line address begin position )
//
//1. 冲突解决:通过检查 ( _key + lines*factor ) % PRIMER_TABLE[i]; 的位置是否已经设置, 否则检查下一个位置
//2. hash 多级取模, 通过计算素数来尽量散列
//3. lines 指定了最多的可能冲突次数
//4. maxline 确定共享内级的冲突最大级数
//5.初始化时需要指定 valueType, 元素固定长度, 不能为stl
//------------------------------------------
#include<iostream>
#include<cstdlib>
#include<cmath>
#include<sys/shm.h>
#include<fstream>
#include<vector>
#include<string>
using std::cout;
using std::cerr;
using std::string;
using std::vector;
using std::ifstream;
using std::ofstream;
using std::ios;
extern const int PRIMER_TABLE_LEN;
extern const int PRIMER_TABLE[ ] ;
enum HASH_RETURN_CODE
{
HASHSHM_OK = 0,
HASHSHM_KEYEXIST,
HASHSHM_ERROR,
HASHSHM_NOTFOUND,
HASHSHM_INSERTERROR,
HASHSHM_OUTOFMEM,
HASHSHM_UPDATE_ERROR,
};
enum HASH_STATUS
{
HASH_STATUS_NORMAL = 0x1,
HASH_STATUS_WRITE_ONLY = 0x2,
HASH_STATUS_READ_ONLY = 0x4
};
enum HASH_ENABLE_FLAG
{
HASH_ENABLE_NONE = 0x0,
HASH_ENABLE_DETACH = 0x1, //detach from shm, when all process detach,the shm will release
};
//max conflict time, max items = MAX_LINES * BaseBucketLen ( default 100w )
const int MAX_LINES = 32;
//hash factor, use for better hash distrubition
const int FACTOR = 5381;
//use for thread magic id
const int THREAD_STEP = 1;
//string hash time33
unsigned long hash_time33(char const *str, int len =-1 );
template< typename valueType, int lines = MAX_LINES, int thread_step = THREAD_STEP >
class CHashShm
{
public:
CHashShm():bInitOk(false){};
virtual ~CHashShm();
//init with the share memory key,it will get share memory
//if fail,exit
bool Init( key_t shm_key );
public:
//set node into shm
// 1) if the _key exists,return HASHSHM_KEYEXIST
// 2) if set success,return HASHSHM_OK
// 3) if fail return HASHSHM_ERROR
int Set( const unsigned long _key ,const valueType &_value);
int Set( const char* skey, const int len ,const valueType &_value );
int Set( const string& strkey ,const valueType &_value );
//get node from shm
int Get( const unsigned long _key, valueType& _value );
int Get( const char* skey, const int len, valueType& _value );
int Get( const string& strkey , valueType &_value );
int Replace( const unsigned long _key ,const valueType& _value );
int Replace( const char* skey, const int len,const valueType& _value );
int Replace( const string& strkey ,const valueType &_value );
//if _key not in the table,return HASHSHM_NOTFOUND, else remove the node,set the node key 0 and return HASHSHM_OK
int Remove( const unsigned long _key );
int Remove( const char* skey, const int len );
int Remove( const string& strkey );
//callback function/param for execute, param_in will be pass to callback function as param_out
void Foreach( void (*callback)( const unsigned long _key, valueType& _value, void* param_out ), void* param_in );
//remove all the data
void Clear();
//operation enable behavior
int SetBehavior( unsigned int iflag );
int UnsetBehavior( unsigned int iflag );
bool IsInitOK(){ return bInitOk; }
public:
bool BinDump( char* filename = "./chsbin" );
bool BinRestore( char* filename = "./chsbin" );
public:
//the rate of the space used
double GetFullRate() const;
//the bucket size( begin 0 )
void GetBucketSize( unsigned int index ) const ;
//get one bucket's item count
int GetBucketUseSize( unsigned int index ) const ;
unsigned long GetCurSize() { return m_hashHead->currentSize; }
unsigned long GetSize() { return maxSize; };
private:
//the start position of the share memory
// 1) the begin mem space used to storage the runtime data, reserved 16 byte
// 2) currentSize = (unsigned long *)((long)mem)
void *mem;
//current size of the table ,the pointer of the shm begin
struct hash_head{
unsigned long currentSize;
unsigned long status;
unsigned long reservered2;
unsigned long reservered3;
};
hash_head * m_hashHead;
//the size of the share memory
unsigned long memSize;
//PRIMER_TABLE_TATAL[i] is the summary of the PRIMER_TABLE when x<=i
unsigned long PRIMER_TABLE_TATAL[lines];
//the size of the table
unsigned long maxSize;
//write by the find function,record the last find place
void *lastFound;
//Init flag
bool bInitOk;
//enable operation flag
unsigned int flag;
//the node of the hash table
// 1) when key==0,the node is empty
// 2) name-value pair
struct hash_node{
unsigned long key;
valueType value;
};
private:
//if _key in the table,return HASHSHM_OK,and set lastFound the position,otherwise return HASHSHM_NOTFOUND
int find( const unsigned long _key );
//get share memory,used by the constructor
bool getShm( key_t shm_key );
//get the positon with the (row,col), map to line pos
void *getPos( const unsigned int _row, const unsigned long _col )
{
//calculate the positon from the start
unsigned long pos = PRIMER_TABLE_TATAL[_row] + _col;
if ( pos >= maxSize + sizeof(hash_head))
return NULL;
return (void *)((long)mem+ sizeof(hash_head) + pos*sizeof(hash_node));
}
};
template< typename vT, int lines, int thread_step >
bool CHashShm<vT,lines,thread_step>::Init( key_t shm_key )
{
if( lines > PRIMER_TABLE_LEN )
return false;
//constructor with get share memory
maxSize=0;
int i;
for(i=0;i<lines;i++)
{
//caculate the PRIMER_TABLE_TATAL
maxSize+=PRIMER_TABLE[i];
if(i!=0)
PRIMER_TABLE_TATAL[i] = PRIMER_TABLE_TATAL[i-1]+PRIMER_TABLE[i-1];
else
PRIMER_TABLE_TATAL[i]=0;
}
//extra 16byte for use
memSize=sizeof(hash_node)*maxSize + sizeof(hash_head);
if(!getShm( shm_key ))
bInitOk = false;
else
{
m_hashHead = (hash_head*)((long)mem );
m_hashHead->currentSize = 0;
//initialize as normal
m_hashHead->status = HASH_STATUS_NORMAL;
//init operation enable to default none
flag = HASH_ENABLE_NONE;
bInitOk = true;
}
return bInitOk;
}
template< typename vT, int lines, int thread_step >
CHashShm<vT,lines,thread_step>::~CHashShm()
{
//detach from share mem if HASH_ENABLE_DETACH setd. Because
if( flag& HASH_ENABLE_DETACH )
shmdt( mem );
}
template< typename vT, int lines, int thread_step >
void CHashShm<vT,lines,thread_step>::Clear()
{
memset(mem,0,memSize);
m_hashHead->currentSize=0;
}
template< typename vT, int lines, int thread_step >
bool CHashShm<vT,lines,thread_step>::getShm( key_t shm_key )
{
int shm_id=shmget(shm_key,memSize,0666);
//check if the shm exists
if( shm_id==-1 )
{
//create the shm
shm_id=shmget(shm_key,memSize,0666|IPC_CREAT);
if(shm_id==-1){
cerr<<"Share memory get failed\n";
return false;
}
//create the shm
mem=shmat(shm_id,NULL,0);
memset(mem,0,memSize);
if(int(mem)==-1){
cerr<<"shmat system call failed\n";
return false;
}
}
else
{
//exist, point to the shm
mem=shmat(shm_id,NULL,0);
if(int(mem)==-1){
cerr<<"shmat system call failed\n";
return false;
}
}
return true;
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::find( const unsigned long _key)
{
unsigned long hash;
hash_node *pH=NULL;
for(int i=0;i<lines;i++)
{
//calculate the col position
hash = ( _key + lines * FACTOR ) % PRIMER_TABLE[i];
pH = ( hash_node *)getPos( i, hash );
//position exceed the shm size, just break
if( NULL == pH )
break;
if( pH->key == _key )
{
lastFound=pH;
return HASHSHM_OK;
}
}
return HASHSHM_NOTFOUND;
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::Set( const unsigned long _key,const vT&_value)
{
//if the key exists
if( find(_key )== HASHSHM_OK )
return HASHSHM_KEYEXIST;
unsigned long hash;
hash_node *pH=NULL;
for(int i=0;i<lines;i++)
{
//minimize conflict using primes
// 1) firs hash pos( calculate the col position )
hash=( _key + lines * FACTOR ) % PRIMER_TABLE[i];
// 2) second hash pos( row, col )
pH=(hash_node *)getPos( i,hash );
// insert position exceed the shm size
if( NULL == pH )
return HASHSHM_OUTOFMEM;
//find the insert position,insert the value
if( pH->key== 0 )
{
pH->key = _key;
pH->value = _value;
m_hashHead->currentSize++;
return HASHSHM_OK;
}
}
//all the appropriate position filled
return HASHSHM_ERROR;
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::Set( const char* skey, const int len, const vT &_value )
{
unsigned long ulHashKey = hash_time33( skey, len );
return Set( ulHashKey, _value );
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::Set( const string& strkey, const vT &_value )
{
unsigned long ulHashKey = hash_time33( strkey.data(), strkey.size() );
return Set( ulHashKey, _value );
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::Get( const unsigned long _key, vT& _value )
{
if( find( _key ) != HASHSHM_OK )
return HASHSHM_NOTFOUND;
//memset( &_value, &((hash_node*)lastFound)->value, sizeof(_value) );
//Do I need memset?( c++' bitwise copy )
_value = ((hash_node*)lastFound)->value;
return HASHSHM_OK;
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::Get( const char* skey, const int len, vT&_value )
{
unsigned long ulHashKey = hash_time33( skey, len );
return Get( ulHashKey, _value );
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::Get( const string& strkey, vT&_value )
{
unsigned long ulHashKey = hash_time33( strkey.data(), strkey.size() );
return Get( ulHashKey, _value );
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::Replace( const unsigned long _key,const vT &_value)
{
//if the key exists, replace the value
if( find(_key )== HASHSHM_OK )
{
((hash_node*)lastFound)->value = _value;
return HASHSHM_OK;
}
//if not found, the find a hash place
unsigned long hash;
hash_node *pH=NULL;
for(int i=0;i<lines;i++)
{
//minimize conflict using primes
// 1) firs hash pos( calculate the col position )
hash=( _key + lines * FACTOR ) % PRIMER_TABLE[i];
// 2) second hash pos( row, col )
pH=(hash_node *)getPos( i,hash );
// insert position exceed the shm size
if( NULL == pH )
return HASHSHM_OUTOFMEM;
//find the insert position,insert the value
if( pH->key== 0 )
{
pH->key = _key;
pH->value = _value;
m_hashHead->currentSize++;
return HASHSHM_OK;
}
}
//all the appropriate position filled
return HASHSHM_ERROR;
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::Replace( const char* skey, const int len, const vT&_value )
{
unsigned long ulHashKey = hash_time33( skey, len );
return Replace( ulHashKey, _value );
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::Replace( const string& strkey, const vT&_value )
{
unsigned long ulHashKey = hash_time33( strkey.data(), strkey.size() );
return Replace( ulHashKey, _value );
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::Remove( const unsigned long _key)
{
//not found
if( find(_key) != HASHSHM_OK )
return HASHSHM_NOTFOUND;
hash_node *pH=(hash_node *)lastFound;
//only set the key 0
pH->key=0;
m_hashHead->currentSize--;
return HASHSHM_OK;
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::Remove( const char* skey, const int len )
{
unsigned long ulHashKey = hash_time33( skey, len );
return Remove( ulHashKey );
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::Remove( const string& strkey )
{
unsigned long ulHashKey = hash_time33( strkey.data(), strkey.size() );
return Remove( ulHashKey );
}
template< typename vT, int lines, int thread_step >
void CHashShm<vT,lines,thread_step>::Foreach(void (*callback)( const unsigned long _key,vT &_value,void * param_out ), void* param_in )
{
typedef unsigned long u_long;
u_long beg=(u_long)mem + sizeof(hash_head);
u_long end=(u_long)mem+ sizeof(hash_head) + sizeof(hash_node)*(PRIMER_TABLE[lines-1]+PRIMER_TABLE_TATAL[lines-1]);
hash_node *p=NULL;
for(u_long pos=beg;pos<end;pos+=sizeof(hash_node))
{
//directly referece the actual memory place, so value can be modify outside directly
p=(hash_node *)pos;
if(p->key!=0)
callback( p->key,p->value, param_in );
}
}
template< typename vT, int lines, int thread_step >
bool CHashShm<vT,lines,thread_step>::BinDump( char* filename)
{
ofstream os( filename, ios::out | ios::binary );
if( !os )
return false;
os.write( (char*)mem, memSize );
os.close();
return true;
}
template< typename vT, int lines, int thread_step >
bool CHashShm<vT,lines,thread_step>::BinRestore( char* filename)
{
ifstream ios( filename, ios::binary );
if( !ios )
return false;
// get length of file:
ios.seekg (0, ios::end);
unsigned long file_length = ios.tellg();
ios.seekg (0, ios::beg);
if( file_length != memSize )
return false;
ios.read( (char*)mem, memSize );
ios.close();
return true;
}
//the rate of the space used
template< typename vT, int lines, int thread_step >
double CHashShm<vT,lines,thread_step>::GetFullRate() const
{
return double( m_hashHead->currentSize )/maxSize;
};
//the bucket size( begin 0 )
template< typename vT, int lines, int thread_step >
void CHashShm<vT,lines,thread_step>::GetBucketSize( unsigned int index ) const
{
return index>=lines?0:PRIMER_TABLE[index];
} ;
//get one bucket's item count
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::GetBucketUseSize( unsigned int index ) const
{
if( index>=lines )
return 0;
int sum = 0;
hash_node * pNode = (hash_node *)((long)mem+ sizeof(hash_head) + index*sizeof(hash_node));
for( int i=0; i<PRIMER_TABLE[index]; i++ )
{
if( pNode->key != 0 )
++sum;
}
return sum;
}
//set operation enable flag
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::SetBehavior( unsigned int iflag )
{
flag |= iflag;
return flag;
}
template< typename vT, int lines, int thread_step >
int CHashShm<vT,lines,thread_step>::UnsetBehavior( unsigned int iflag )
{
flag &= ~iflag;
return flag;
}
#endif
Cpp文件:
//-------------------------------------------
//Cola's Hash Shm Library 1.03
//colaliang( SNG Instant Messaging Application Department )
//last update: 2012-12-27
#include "hash_shm.h"
const int PRIMER_TABLE_LEN = 64;
const int PRIMER_TABLE[ PRIMER_TABLE_LEN ] = {
1511,1523,1531,1543,1549,1553,1559,1567,1571,1579,1583,1597,1601,1607,1609,1613,1619,1621,1627,1637,1657,1663,1667,1669,1693,
1697,1699,1709,1721,1723,1733,1741,1747,1753,1759,1777,1783,1787,1789,1801,1811,1823,1831,1847,1861,1867,1871,1873,1877,1879,
1889,1901,1907,1913,1931,1933,1949,1951,1973,1979,1987,1993,1997,1999
};
unsigned long hash_time33(char const *str, int len )
{
//get from php
unsigned long hash = 5381;
//variant with the hash unrolled eight times
// if len not specify, use default time33
char const *p = str;
if( len < 0 )
{
for(; *p; p++)
{
hash = hash * 33 + *p;
}
return hash;
}
#define TIME33_HASH_MIXED_CH() hash = ((hash<<5)+hash) + *p++
//use eighe alignment
for (; len >= 8; len -= 8)
{
TIME33_HASH_MIXED_CH(); // 1
TIME33_HASH_MIXED_CH(); // 2
TIME33_HASH_MIXED_CH(); // 3
TIME33_HASH_MIXED_CH(); // 4
TIME33_HASH_MIXED_CH(); // 5
TIME33_HASH_MIXED_CH(); // 6
TIME33_HASH_MIXED_CH(); // 7
TIME33_HASH_MIXED_CH(); // 8
}
switch (len)
{
case 7: TIME33_HASH_MIXED_CH();
case 6: TIME33_HASH_MIXED_CH();
case 5: TIME33_HASH_MIXED_CH();
case 4: TIME33_HASH_MIXED_CH();
case 3: TIME33_HASH_MIXED_CH();
case 2: TIME33_HASH_MIXED_CH();
case 1: TIME33_HASH_MIXED_CH(); break;
case 0: break;
}
return hash;
}














 1604
1604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









