







GoogLeNet
Inception
结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构。
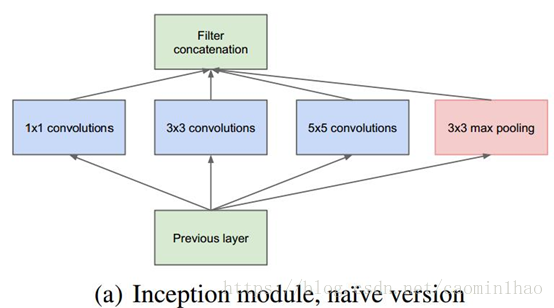
对上图做以下说明:
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
4 . 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
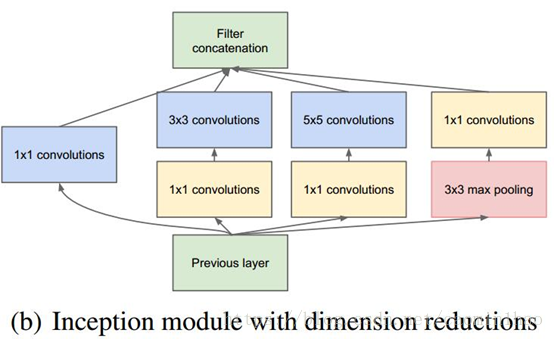
但是,使用5x5的卷积核仍然会带来巨大的计算量。 为此,文章借鉴NIN2,采用1x1卷积核来进行降维。
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 +32x5x5x256,大约减少了4倍。
具体改进后的Inception Module如下图:
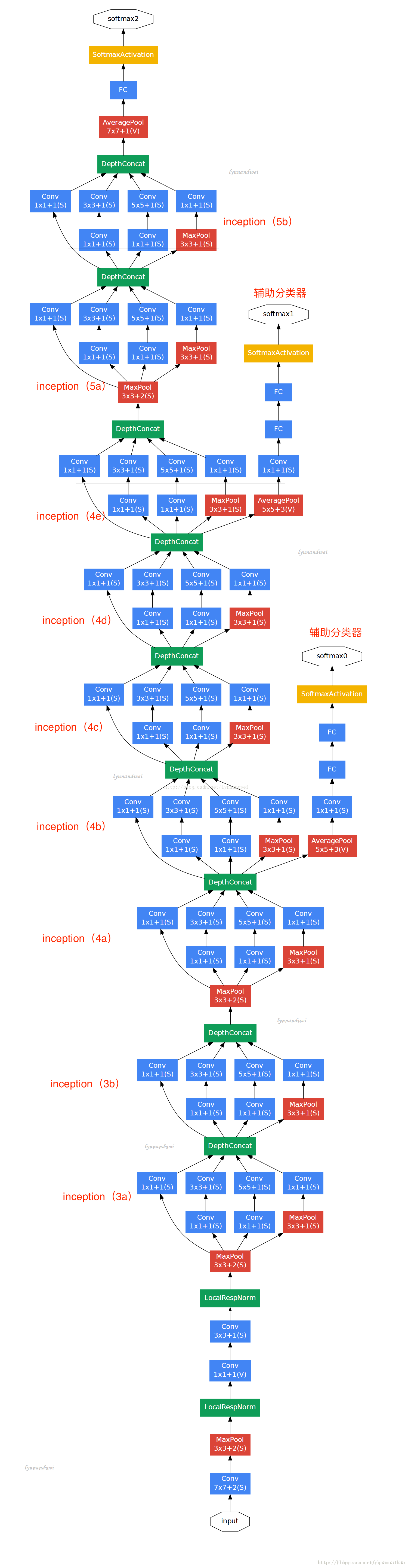
GoogLeNet整体结构图GoogLeNet图
对下图做如下说明:
1 . 显然 GoogLeNet 采用了模块化的结构,方便增添和修改;
2 . 网络最后采用了 average pooling 来代替全连接层,想法来自 NIN, 事实证明可以将 TOP1 accuracy 提高 0.6% 。但是,实际在最后还是加了一个全连接层,主要是为了方便以后大家 finetune ;
3 . 虽然移除了全连接,但是网络中依然使用了 Dropout ;
4 . 为了避免梯度消失,网络额外增加了 2 个辅助的 softmax 用于向前传导梯度。文章中说这两个辅助的分类器的 loss 应该加一个衰减系数,但看 caffe 中的 model 也没有加任何衰减。此外,实际测试的时候,这两个额外的 softmax 会被去掉。
1 . 显然 GoogLeNet 采用了模块化的结构,方便增添和修改;
2 . 网络最后采用了 average pooling 来代替全连接层,想法来自 NIN, 事实证明可以将 TOP1 accuracy 提高 0.6% 。但是,实际在最后还是加了一个全连接层,主要是为了方便以后大家 finetune ;
3 . 虽然移除了全连接,但是网络中依然使用了 Dropout ;
4 . 为了避免梯度消失,网络额外增加了 2 个辅助的 softmax 用于向前传导梯度。文章中说这两个辅助的分类器的 loss 应该加一个衰减系数,但看 caffe 中的 model 也没有加任何衰减。此外,实际测试的时候,这两个额外的 softmax 会被去掉。
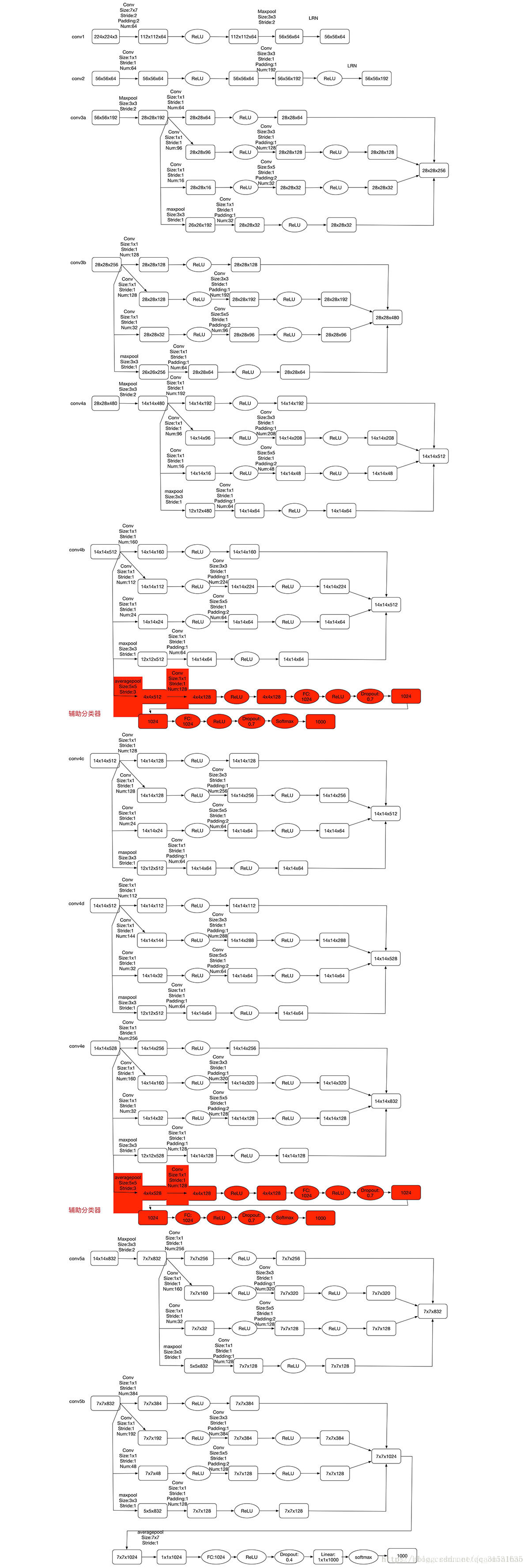
实现细节,用tensorflow时,在DepthConcat层,tensorflow中使用tf.concat()将不同大小卷积核卷积大小组合起来,增加深度,具体见下图。














 696
696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









