







欢迎大家批评指正和转载,不过还是希望大家尊重一下劳动成果,转载注明出处。
转载请注明出处:http://blog.csdn.net/caoshichao520326/article/details/8859822
在解析XML文件的过程中,发现API文档中对于解析事件描述的不够详尽,给解析XML文件带来了不少的困扰,今天做了个事件类型分析的demo和大家分享一下。第一步:新建一个Android工程文件,其他都不用改,只要在onCreate()方法中写一个xmlTest()方法即可,代码如下:
package com.csc.xmltest;
import java.io.IOException;
import org.xmlpull.v1.XmlPullParser;
import org.xmlpull.v1.XmlPullParserException;
import android.app.Activity;
import android.content.res.XmlResourceParser;
import android.os.Bundle;
public class MainActivity extends Activity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
xmlTest();
}
/**
* 测试Pull解析方式中的事件类型
*/
private void xmlTest() {
//定义事件类型
int eventType = 0;
try {
XmlResourceParser xrp = getResources().getXml(R.xml.timezones);
// 获取到xml文件时,XmlResourceParser的是指向文档开始处
eventType = xrp.getEventType();
// System.out.println("-------->"+eventType);//查看事件的数值
while (eventType != XmlPullParser.END_DOCUMENT) {
switch (eventType) {
case XmlPullParser.START_DOCUMENT:
System.out.println("Start document");
break;
case XmlPullParser.START_TAG:
System.out.println("Start tag " + xrp.getName());
break;
case XmlPullParser.TEXT:
System.out.println("Text " + xrp.getText());
break;
case XmlPullParser.END_TAG:
System.out.println("End tag " + xrp.getName());
break;
default:
break;
}
eventType = xrp.next();
//System.out.println("-------->"+eventType);//查看事件的数值
}
} catch (XmlPullParserException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//判断事件类型是不是文档结束
if (eventType == XmlPullParser.END_DOCUMENT) {
System.out.println("End document");
}
}
}
<?xml version="1.0" encoding="utf-8"?>
<timezones>
<timezone id="Pacific/Majuro">马朱罗</timezone>
<timezone id="Pacific/Midway">中途岛</timezone>
</timezones>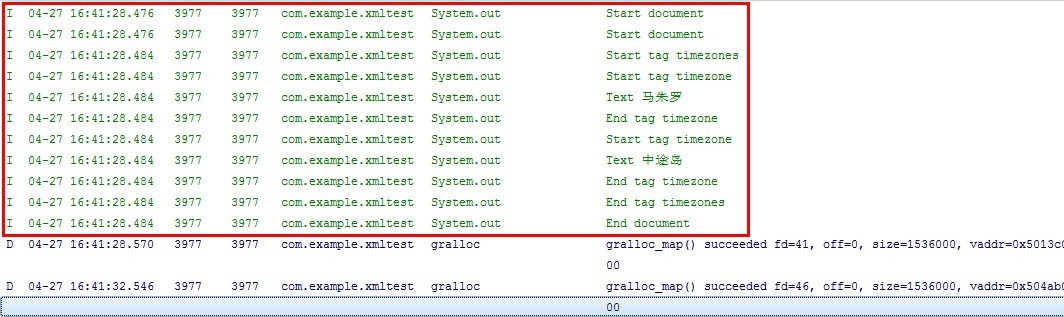
我们对打印结果做分析如下:
1.可以看到Start document打印了两次,说明当程序实例化XmlResourceParser这个对象后,Pull解析器默认的事件是XmlPullParser.START_DOCUMENT,当执行一次XmlResourceParser.next()后,事件仍然指向XmlPullParser.START_DOCUMENT。
2.之后再执行XmlResourceParser.next()则依次向下取一个事件。
3.常用的事件有:XmlPullParser.START_DOCUMENT、XmlPullParser.START_TAG、XmlPullParser.TEXTXmlPullParser.END_TAG、XmlPullParser.END_DOCUMENT。
根据事件的值,就可以解析出xml文档的内容,具体怎么处理数据,就根据大家的需要来编写了。
源码下载地址:http://download.csdn.net/detail/caoshichao520326/5310287
欢迎大家批评指正和转载,不过还是希望大家尊重一下劳动成果,转载注明出处。
转载请注明出处:http://blog.csdn.net/caoshichao520326/article/details/8859822















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









