









在前面的一些关于机器案例中使用了激活函数,
如 机器学习(1)--神经网络初探 开篇中的 tanh(x)与tanh_deriv(x)两个函数
TensorFlow实例(5.1)--MNIST手写数字进阶算法(卷积神经网络CNN) 中在最大池化时使用的 tf.nn.relu
我们为什么要使用激活函数,通常他有如下一些性质:
非线性: 如果是线性的时候,多层的神经网络是无意义的
可微性: 做梯度下降,这是不可少的
单调性: 如果是非单调的,那么无法保证网络是凸函数。
全是高数的东东,看着晕,相当的感觉用处不大,如果你数学足够好,自己能创建或写出新的激活函数,
立马觉得我这写得太简单,然后一块豆腐把我拍个半死,丫的什么都不懂
如果你数学和我一样不太好,那就用用别人常用的就好了,所以卵用没有,纯粹为了假装很懂,让你不明觉厉
激活函数用在什么地方
又是一串的高等数学,高数基本干什么不太明白?不想深入就算了,想深入还是翻翻书吧。
这时,虽然最后也会有效果,但中间层完全没有作用,都是直来直去的嘛
数理上也简单,如果不使用激活函数,那么可以假设这个激活函数为f(x)=x 同样,导数f'(x)=1,在反向调整误差时,中间层没发生变化
所以综合一句, 如果不使用激活函数,则神经网络的效果只相当于只有输入层与输出层两层,设置多少层中间层也没卵用
先介绍几个激活函数,同时后面有相应的python代码,同样会绘制出相关的曲线
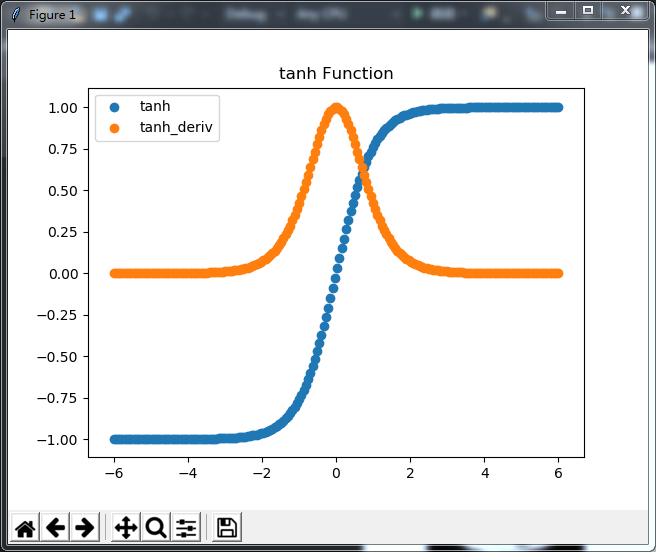
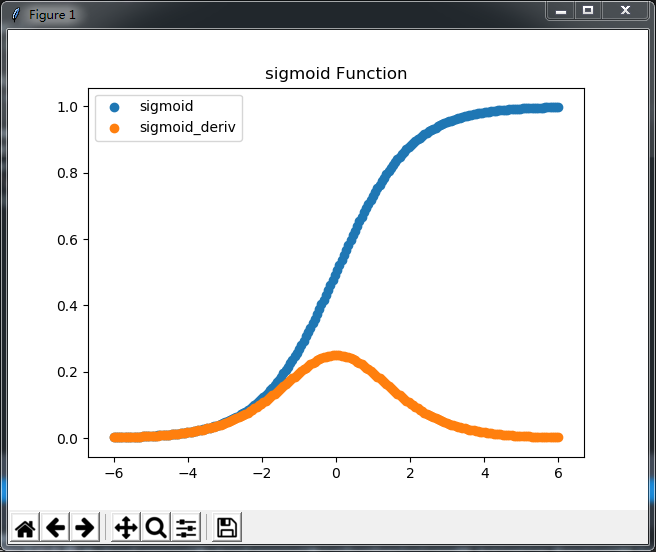
1、Sigmoid 与 tanh 函数,这两个函数差不多,从下图中就能看得出来,能够把输入的连续实际值进行压缩。
主要差异在于Sigmoid 把值压到0-1之间,tanh把值压到-1,1之间
仔细看看图再想想也就看得出来了,这两种函数都有一个共同的缺点,
同样这两个函数比较的话,tanh会更好点,因为Sigmoid 把值压到0-1之间,假设所有x正负值相同时,Sigmoid对应的y值不是零均值,而tanh是零均值,因此,在实际应用中,tanh 会比 sigmoid 更好,
2、RELU 与 Leaky RELU函数
2.1 RELU 函数现在好像越来越受欢迎,看了好多关于为什么RELU对神经网络最后效果明显的根本原因
但没感觉有哪个有特别的说服力,无所谓了,大家说好了,我也赞一下,
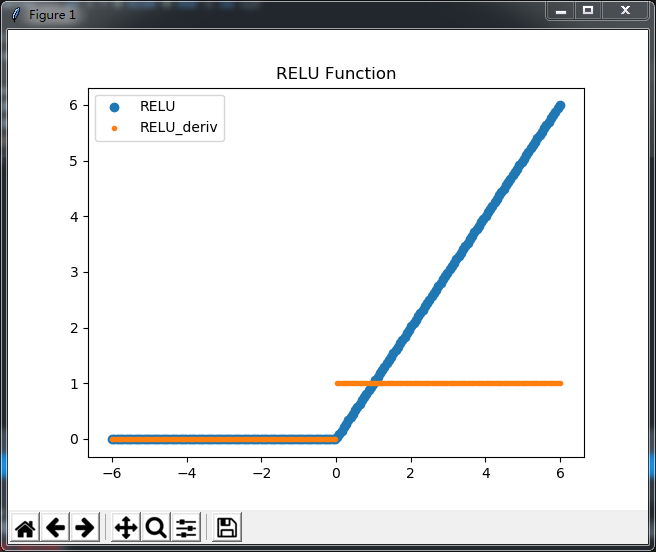
这个函数很简单f(x)=max(0,x),文字表达就是,x小于零时取零,x大于零时就是x,更简单的说负数不要
在实操中,如果你的学习率很大时,那么很有可能非常多的神经元无效。
当然,较小的学习率,这个问题就不明显,但因为学习率的降低,最后的计算量也就大了。
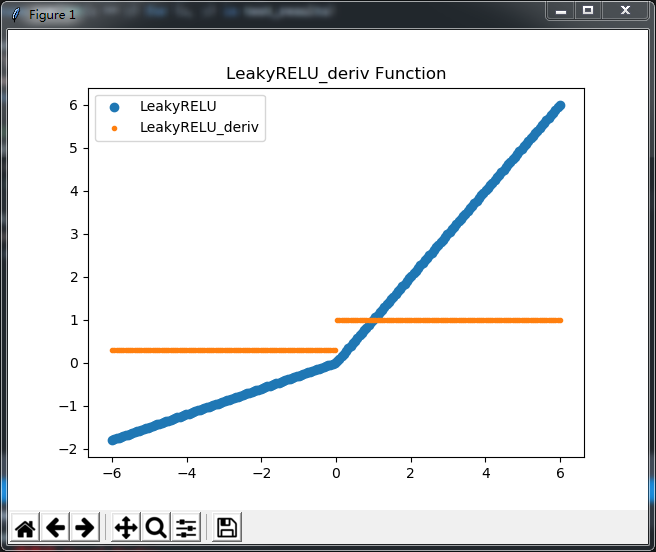
2.2 Leaky RELU 是RELU的一个简单变形,就是把x小于零的部份乘以一个很小的值,这样把负值的部份进行等比压缩
至于最终的效果好不好我也不清楚,有人说好有人说不好,反正我没试过,
我也不知道,...,怎么眼前全是豆腐,
个人感觉,纯属个人感觉,使用RELU,调整学习率很重要,tanh比Sigmoid好用一点,
如 机器学习(1)--神经网络初探 开篇中的 tanh(x)与tanh_deriv(x)两个函数
TensorFlow实例(5.1)--MNIST手写数字进阶算法(卷积神经网络CNN) 中在最大池化时使用的 tf.nn.relu
我们为什么要使用激活函数,通常他有如下一些性质:
非线性: 如果是线性的时候,多层的神经网络是无意义的
可微性: 做梯度下降,这是不可少的
单调性: 如果是非单调的,那么无法保证网络是凸函数。
全是高数的东东,看着晕,相当的感觉用处不大,如果你数学足够好,自己能创建或写出新的激活函数,
立马觉得我这写得太简单,然后一块豆腐把我拍个半死,丫的什么都不懂
如果你数学和我一样不太好,那就用用别人常用的就好了,所以卵用没有,纯粹为了假装很懂,让你不明觉厉
激活函数用在什么地方
当我们定义好神经网络层,并在每两层间做完矩阵乘法计算weight时,即np.dot后,
我们设val=np.dot(w,x),这时我们会再调用激活函数,如tanh(val)
当神经网络正向计算完后,进行反向计算时,
通过 y(实际值)-y(计算值)求出误差error ,通过error * tanh_deriv() 可以得到我们要调整的值
基中tanh_deriv是tanh的导数,所以激活函数一定是成对出现,正向使用激活函数,反向使用激活函数的导数又是一串的高等数学,高数基本干什么不太明白?不想深入就算了,想深入还是翻翻书吧。
再问一次,我们为什么要使用激活函数
如果上面导数的部份理解,那下面好理解, 导数不理解的话,就简单记记吧
如果我们不使用激活函数,那么正向运算时,val=np.dot(w,x)计算完就结束了,同样反向计算时,计算到 error=y(实际值)-y(计算值)后也结束了这时,虽然最后也会有效果,但中间层完全没有作用,都是直来直去的嘛
数理上也简单,如果不使用激活函数,那么可以假设这个激活函数为f(x)=x 同样,导数f'(x)=1,在反向调整误差时,中间层没发生变化
所以综合一句, 如果不使用激活函数,则神经网络的效果只相当于只有输入层与输出层两层,设置多少层中间层也没卵用
先介绍几个激活函数,同时后面有相应的python代码,同样会绘制出相关的曲线
1、Sigmoid 与 tanh 函数,这两个函数差不多,从下图中就能看得出来,能够把输入的连续实际值进行压缩。
主要差异在于Sigmoid 把值压到0-1之间,tanh把值压到-1,1之间
仔细看看图再想想也就看得出来了,这两种函数都有一个共同的缺点,
当输入非常大或者非常小的时候,这些神经元的梯度是接近于0的,
也就是说,当初始值没设好,会导致很多值接近于0,而在梯度下降时,就会跳过
所以对初始值的设置与调试非常重要同样这两个函数比较的话,tanh会更好点,因为Sigmoid 把值压到0-1之间,假设所有x正负值相同时,Sigmoid对应的y值不是零均值,而tanh是零均值,因此,在实际应用中,tanh 会比 sigmoid 更好,
# -*- coding:utf-8 -*-
#tanh 函数
import numpy as np
import matplotlib.pyplot as plt
def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x) * np.tanh(x)
x = np.linspace(-6,6,200)
plt.scatter(x,tanh(x),label="tanh")
plt.scatter(x,tanh_deriv(x),label="tanh_deriv")
plt.title('tanh Function')
plt.legend(loc = 'upper left')
plt.show()#Sigmoid
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(z):
return 1.0 / (1.0 + np.exp(-z))
def sigmoid_deriv(z):
return sigmoid(z) * (1 - sigmoid(z))
x = np.linspace(-6,6,200)
plt.scatter(x,sigmoid(x),label="sigmoid")
plt.scatter(x,sigmoid_deriv(x),label="sigmoid_deriv")
plt.title('sigmoid Function')
plt.legend(loc = 'upper left')
plt.show()2、RELU 与 Leaky RELU函数
2.1 RELU 函数现在好像越来越受欢迎,看了好多关于为什么RELU对神经网络最后效果明显的根本原因
但没感觉有哪个有特别的说服力,无所谓了,大家说好了,我也赞一下,
这个函数很简单f(x)=max(0,x),文字表达就是,x小于零时取零,x大于零时就是x,更简单的说负数不要
在实操中,如果你的学习率很大时,那么很有可能非常多的神经元无效。
当然,较小的学习率,这个问题就不明显,但因为学习率的降低,最后的计算量也就大了。
2.2 Leaky RELU 是RELU的一个简单变形,就是把x小于零的部份乘以一个很小的值,这样把负值的部份进行等比压缩
至于最终的效果好不好我也不清楚,有人说好有人说不好,反正我没试过,
#RELU
import numpy as np
import matplotlib.pyplot as plt
def RELU(z):
return np.array([x if x > 0 else 0 for x in z])
def RELU_deriv(z):
return np.array([1 if x > 0 else 0 for x in z])
x = np.linspace(-6,6,200)
plt.scatter(x,RELU(x),label="RELU")
plt.scatter(x,RELU_deriv(x),marker='.',label="RELU_deriv",)
plt.title('RELU Function')
plt.legend(loc = 'upper left')
plt.show()#Leaky RELU
import numpy as np
import matplotlib.pyplot as plt
def LeakyRELU(z,a=0.3):
return np.array([x if x > 0 else a * x for x in z])
def LeakyRELU_deriv(z,a=0.3):
return np.array([1 if x > 0 else a for x in z])
x = np.linspace(-6,6,200)
plt.scatter(x,LeakyRELU(x),label="LeakyRELU")
plt.scatter(x,LeakyRELU_deriv(x),marker='.',label="LeakyRELU_deriv",)
plt.title('LeakyRELU_deriv Function')
plt.legend(loc = 'upper left')
plt.show()我也不知道,...,怎么眼前全是豆腐,
个人感觉,纯属个人感觉,使用RELU,调整学习率很重要,tanh比Sigmoid好用一点,
又是屁话,学习率很重要?初始化、学习率,网络层设置哪个不重要?全部都重要好的吧
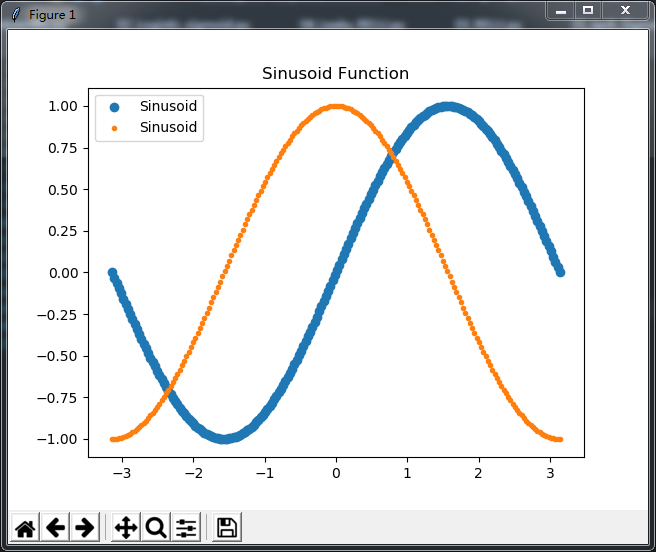
再画几个激活函数,有用?没用?好用?难用?我也没用过,不知道,只想装个X,
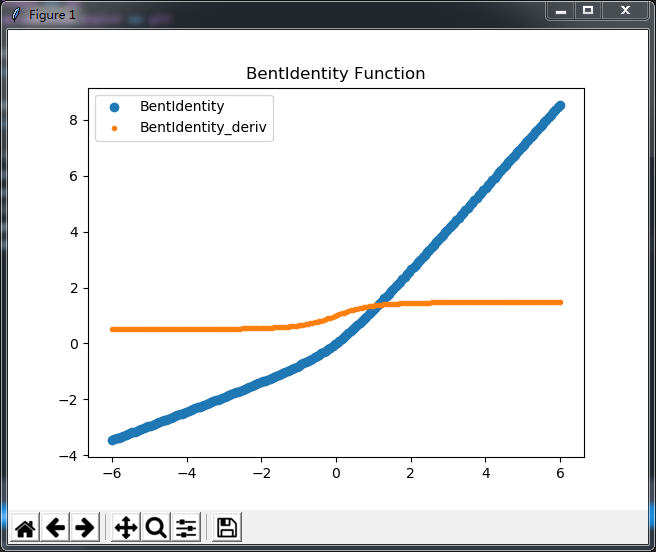
#BentIdentity
import numpy as np
import matplotlib.pyplot as plt
def BentIdentity(z):
return (np.sqrt(z ** 2 + 1) - 1) / 2 + z
def BentIdentity_deriv(z):
return z / (2 * np.sqrt(x ** 2 + 1)) + 1
x = np.linspace(-6,6,200)
plt.scatter(x,BentIdentity(x),label="BentIdentity")
plt.scatter(x,BentIdentity_deriv(x),marker='.',label="BentIdentity_deriv",)
plt.title('BentIdentity Function')
plt.legend(loc = 'upper left')
plt.show()
#Sinusoid
import numpy as np
import matplotlib.pyplot as plt
def Sinusoid(z):
return np.sin(z)
def Sinusoid_deriv(z):
return np.cos(z)
x = np.linspace(-np.pi,np.pi,200)
plt.scatter(x,Sinusoid(x),label="Sinusoid")
plt.scatter(x,Sinusoid_deriv(x),marker='.',label="Sinusoid",)
plt.title('Sinusoid Function')
plt.legend(loc = 'upper left')
plt.show()














 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









