






Goal: assign a probability to a sentence
- Machine Translation - which word fits the meaning and structure better
- Spell correction
- Speech Recognition - two word has same pronounceation
- etc.
The chain rule:
P(ABCD)=P(A)P(B|A)P(C|AB)P(D|ABC)
Cannot simply calculate the chain rule by counting, because there are too many possibles
Markov Assumption:
计数和计算整句话的概率太小,结果的代表性不强,因此使用相邻的几个词建模
k=0 Unigram model P(w1w2…wn)=TT P(wi)
k=1 Bigram model P(wi|w1w2…wi-1)=P(wi|wi-1)
……
In general, this is insufficient, because language has long-distance dependencies. But in most cases, this is enough.
Estimating bigram: MLE P(Wi|Wi-1)=count(wi-1,wi)/count(wi-1)
Knowledge got from the statistic:
World
Grammar
It is prossible the combination is legal, but not appeared in the training data.
We do everything in log space:
- Avoid underflow - 乘积会变得非常非常小,难以计算
- Adding is faster than multiplying
p1*p2*p3*p4=logp1+logp2+logp3+logp4
Evaluation: How good is our model?
If it assigns higher probability to a “real” or “frequently observed” sententce.
Extrinsic evaluation: to put each modal in a task, i.e. spelling corrector, speech recognizer, MT system, and compare the accuracy. Time-consuming
So sometimes use intrinsic evaluation: perplexity
Perplexity is good only when the test data looks just like the training data, but is helpful to think about.
Intuition of perplexity:
The Shannon Game: How well can we predict the next word?
lower perplexity = better model
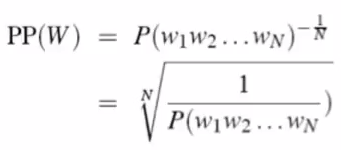















 7653
7653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









