








本人新手入门深度学习,在此记录一下自己学习过程中的心得和自己做的小项目
这里的小课题主要是用在生物特征识别中,目前最广泛的有掌纹识别虹膜识别,我们的这个课题组主要是做手掌静脉识别的,通过红外成像得到掌脉图像然后进行识别。在这里我主要负责的工作是手掌静脉识别时的感兴趣区域的提取(ROI)。
主要是分为三个步骤,虽然实际实现的时候不是很难,但是需要很多的的前期工作。
第一:设计算法分辨左右手,这样的目的可以减少在图像库中匹配和识别的时间,我们可以制作两个数据集,分左右手,识别出左右手之后直接在所在的数据集中进行识别匹配。
第二:设计网络识别手掌图像的ROI区域
第三:做实验验证算法的可行性与精确度
接下来我们来看一下如何用matconvnet来训练自己的数据实现左右手的分类
一、matconvnet的安装与配置
这一步很多博主都写得很清楚了,这里给出一个我参考的链接
当然还有官网的教程
根据上面的教程,如果你运行setup.m没有问题,那就好了。不得不是matconvnet真是很适合想学习深度学习入门最好的工具,因为不需要很高的硬件要求也没有像caffe要求编译那么多,出现的问题也就会少很多。
二、训练自己的数据
1.修改网络结构
我的学习主要是学习example文件夹下的mnist文件为主,在cnn_mnist_init.m中主要是设置了网络结构,初始化了网络参数,如果我们要自己设计网络的时候,可以直接在这里改,注意在改的时候需要注意一下,
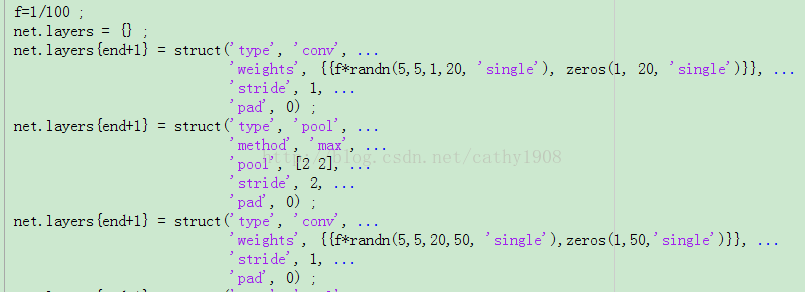
已上图为例,layer1和核大小为5*5,有20个这样的核,所以在之后的偏置也就是zeros(1,20)中,后面的一个数必须与randn(5,5,1,20)的最后一个数要一致,不要改了前面忘了后面,同时改了上层之后,下层的值也是要改的,也是要注意一致的问题。我刚开始的时候犯了这个错误。
2.数据集制作
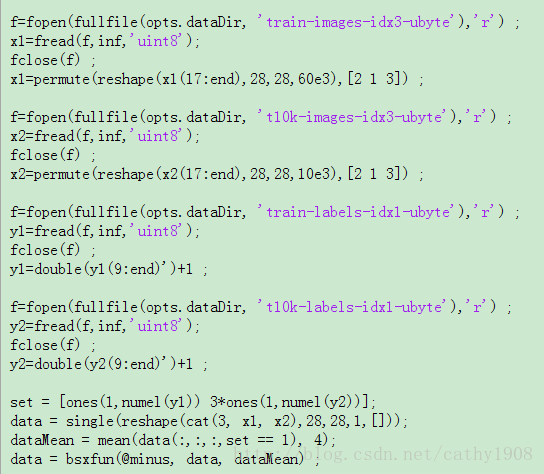
function imdb = getMnistImdb(opts)
x1=zeros(28,28,600);
%y1(1:300) stores female labels(1) in the train set
%y1(301:600) stores male labels(2) in the train set
%变量“x1”存储训练集中的图片,左手和右手的图片各给300张,其前300维存储左手,
%后300维存储右手;而变量“y1”存储训练集对应的标签,也是其前300维存储左手,
%后300维存储右手,这里需要注意的是,matconvnet不能把类别标签设置为“0”,
%否则对其他一些类别不能再识别;这里为二分类问题,这里,左手对应于标签“1”,右手对应于标签“2”。
%同理,“x2”和“y2”对应于验证集中的数据,其中左手和右手图片各80张
y1=cat(2,ones(1,300),ones(1,300)+1);
%读取训练集图片左手
img_file_path=fullfile(vl_rootnn,'data\palm\train\left_hand');
img_dir=dir(img_file_path);
for i=1:length(img_dir)-2
filename=fullfile(img_file_path,img_dir(i+2).name);
I=imread(filename);
I=imresize(I,[28,28]); %将图片压缩为28*28大小
x1(:,:,i)=I;
end
img_file_path=fullfile(vl_rootnn,'data\palm\train\right_hand');
img_dir=dir(img_file_path);
for i=1:length(img_dir)-2
filename=fullfile(img_file_path,img_dir(i+2).name);
I=imread(filename);
I=imresize(I,[28,28]); %将图片压缩为28*28大小
x1(:,:,i+300)=I;
end
x2=zeros(28,28,160);
y2=cat(2,ones(1,80),ones(1,80)+1);
img_file_path=fullfile(vl_rootnn,'data\palm\val\left_hand');
img_dir=dir(img_file_path);
for i=1:length(img_dir)-2
filename=fullfile(img_file_path,img_dir(i+2).name);
I=imread(filename);
I=imresize(I,[28,28]); %将图片压缩为28*28大小
x2(:,:,i)=I;
end
img_file_path=fullfile(vl_rootnn,'data\palm\val\right_hand');
img_dir=dir(img_file_path);
for i=1:length(img_dir)-2
filename=fullfile(img_file_path,img_dir(i+2).name);
I=imread(filename);
I=imresize(I,[28,28]); %将图片压缩为28*28大小
x2(:,:,i+80)=I;
end
set = [ones(1,numel(y1)) 3*ones(1,numel(y2))];
data = single(reshape(cat(3, x1, x2),28,28,1,[]));
dataMean = mean(data(:,:,:,set == 1), 4);
data = bsxfun(@minus, data, dataMean) ;
imdb.images.data = data ;
imdb.images.data_mean = dataMean;
imdb.images.labels = cat(2, y1, y2) ;
imdb.images.set = set ;
imdb.meta.sets = {'train', 'val', 'test'} ;
imdb.meta.classes = arrayfun(@(x)sprintf('%d',x),0:1,'uniformoutput',false) ;
3.训练网络
得到训练结果如下,我们的数据只有600张,所以训练的效果不是很好。虽然结果不怎么好,但是实现是没用问题的,接下来就是加大数据集来试试了。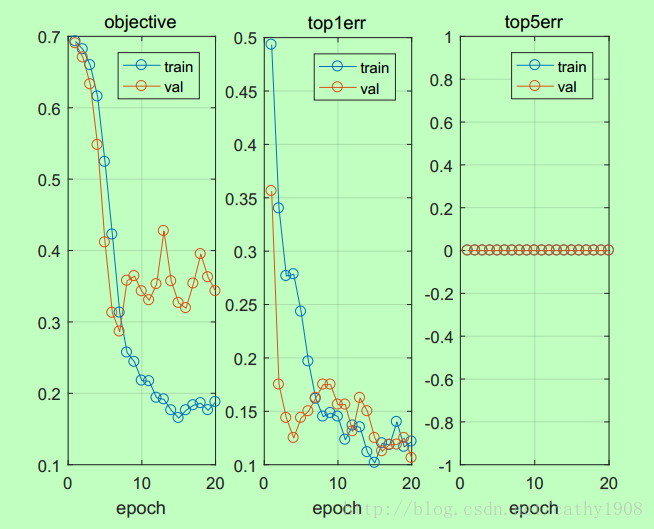
First, you make a prediction using the CNN and obtain the predicted class multinomial distribution (∑pclass=1∑pclass=1).
Now, in the case of top-1 score, you check if the top class (the one having the highest probability) is the same as the target label.
In the case of top-5 score, you check if the target label is one of your top 5 predictions (the 5 ones with the highest probabilities).
In both cases, the top score is computed as the times a predicted label matched the target label, divided by the number of data-points evaluated.
Finally, when 5-CNNs are used, you first average their predictions and follow the same procedure for calculating the top-1 and top-5 scores.
4.结果测试
train_imdb_path=fullfile(vl_rootnn,'\data\mnist-baseline-simplenn\imdb.mat');
net=load('net.mat');
net=net.net;
net.layers{end}.type = 'softmax';
im1=imread('H:\dataSet\CISIA_dataSet\0004_m_r_05.jpg');
im=imresize(im1,[28,28]);
test_img = single(im);
train_imdb=load(train_imdb_path);
train_data_mean=train_imdb.images.data_mean;
test_img=bsxfun(@minus,test_img,train_data_mean);
res = vl_simplenn(net,test_img);
scores=squeeze(gather(res(end).x));
[bestScore, best] = max(scores);
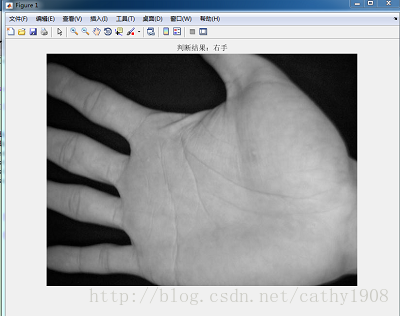
imshow(im1);
switch best
case 1
title('判断结果:左手');
case 2
title('判断结果:右手');
end














 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









