







Unicode
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
char数据类型
C程序中使用char数据类型来定义和存储字符和字符串
下面的声明定义和初始化一个包含单一字符的变量:
char c = 'A';
定义一个指向字符串的指针:
char *p;
因为Windows是一个32位的操作系统,指针变量p需要4个字节的存储空间。还可以如下初始化一个指向字符串的指针:
char *p = "Hello!";
更宽的字符
使用Unicode或者是宽字符并不会改变C语言中的字符数据类型。char类型继续代表一个字节的存储空间,而且sizeof(char)继续返回1.理论上来说,C语言中的一个字节可能长于8位,但是对于大多数人来说,一个字节(因而就是一个char)是8位宽。
C语言中的宽字符是基于wchar_t数据类型的。这个数据类型被定义在多个头文件中,包括WCHAR.H,如下所示:
typedef unsingned short wchar_t;
因此,wchar_t数据类型和一个无符号短整型一样,都是16位宽。
可以用下面的语句来定义一个包含单个宽字符的变量:
wchar_t c = 'A';
还可以如下定义一个已初始化的指向宽字符串的指针:
wchar_t *p = L'Hello!';
大写的字母L(表示长整型)紧接着左引号。这向编译器表明这个字符将使用宽字符存储----也就是说,每个字符占用2个字节。指针变量p还是需要4个字节,但是这个字符需要14个字节—每个字符需要两个字节(Hello! 6*2),再加上最后需要的0的两个字节。
同样,还可以如下定义一个宽字符的数组:
static wchar_t a[] = L'Hello!';
这个字符串同样需要14个字节的存储空间,而sizeof(a)也会返回14.你可以索引a数组来得到每个单独的字符,引号之前的那个L非常重要,并且两个符号之间绝对不能有空格。只有有了这个L,编译器才知道你想要字符串以每个字符两个字节的方式存储。当我们看到在定义变量以外的地方使用宽字符的时候,依然会再次看到L紧跟着引号,也可以在单个字符变量前面使用L前缀,表明它们应该被解释为宽字符:
wchar_t = L'A'; //但是通常是不需要的 C编译器会在字符后面加0补齐
宽字符函数库
找一个指向字符串的指针:
char *pc = "Hello!";
//我们可以调用
int iLength = strlen(pc);
宽字符版本的strlen函数被称为wcslen(“宽字符字符串长度”),并定义在STRING.H(也就是strlen被定义的地方)和WCHAR.H中。
strlen的函数声明如下:
size_t __cdecl strlen (const char * str);
而wcslen函数的声明如下:
size_t __cdecl wcslen (const wchar_t * wcs);
wchar_t *pw = L"Hello!";
iLength = wcslen(pw);
让代码通用的一些方法
1.在变成的时候使用TCHAR数据类型,此类型能够根据预编译宏的定义,将其转换为ANSI或者是Unicode
2.预编译宏_MBCS、_UNICODE和UNICODE._MBCS是多字节和ANSI字符串的编译宏。此时TCHAR转换为char. _UNICODE和UNICODE是Unicode编码的预编译宏,TCHAR转换为wchar_t。
3._UNICODE宏用于C运行期库的头文件,UNICODE宏用于Windows头文件。一般同时定义两个宏
如果一个命名为UNICODE的标识符被定义了并且TCHAR.H头文件被包含在你的程序中。_tcslen就被定义为wcslen:
#define _tcslen wcslen
如果UNICODE并没有被定义,那么_tcslen就被定义为strlen:
#define _tcslen strlen
由此类推,TCHAR.H也用一个命名为TCHAR的新的数据类型解决了两个字符数据类型的问题,如果_UNICODE标识符被定义了,TCHAR就是wchar_t:
typedef wchar_t TCHAR;
否则的话,TCHAR就是一个简单的char:
typedef char TCHAR;
MultiByteToWideChar和WideCharToMultiByte
函数简单介绍
涉及到的头文件:
函数所在头文件:windows.h
#inclode<windows.h>
wchar_t类型所需要的头文件:wchar.h
#include<wchar.h>
MultiByteToWideChar()
函数功能:该函数映射一个字符串到一个宽字符(unicode)的字符串。由该函数映射的字符串没必要是多字节字符串。
函数原型:
int MultiByteToWideChar(
UINT CodePage,
DWORD dwFlags,
LPCSTR lpMultiByteStr,
int cchMultiByte,
LPWSTR lpWideCharStr,
int cchWideChar
);
参数:
**1>CodePage:**指定执行转换的多字节字符所使用的字符集
这个参数可以为系统已安装或有效的任何字符集所给定的值。你也可以指定其为下面的任意一值:
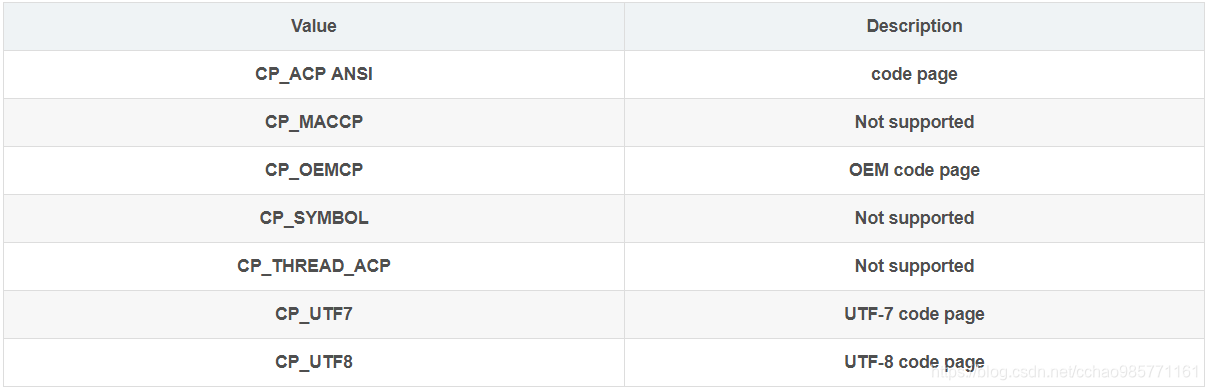
**2> dwFlags:**一组位标记,用以指出是否未转换成预作或宽字符(若组合形式存在),是否使用象形文字替代控制字符,以及如何处理无效字符。你可以指定下面是标记常量的组合,含义如下:
MB_PRECOMPOSED:通常使用预作字符——就是说,由一个基本字符和一个非空字符组成的字符只有一个单一的字符值。这是缺省的转换选择。不能与MB_COMPOSITE值一起使用。
MB_COMPOSITE:通常使用组合字符——就是说,由一个基本字符和一个非空字符组成的字符分别有不同的字符值。不能与MB_PRECOMPOSED值一起使用。
MB_ERR_INVALID_CHARS:如果函数遇到无效的输入字符,它将运行失败,且GetLastErro返回ERROR_NO_UNICODE_TRANSLATION值。
MB_USEGLYPHCHARS:使用象形文字替代控制字符。
组合字符由一个基础字符和一个非空字符构成,每一个都有不同的字符值。每个预作字符都有单一的字符值给基础/非空字符的组成。在字符è中,e就是基础字符,而重音符标记就是非空字符。
标记MB_PRECOMPOSED和MB_COMPOSITE是互斥的,而标记MB_USEGLYPHCHARS和MB_ERR_INVALID_CHARS则不管其它标记如何都可以设置。
一般不使用这些标志,故取值为0时。
**3> lpMultiByteStr:**指向待转换的字符串的缓冲区。
**4> cchMultiByte:**指定由参数lpMultiByteStr指向的字符串中字节的个数。可以设置为-1,会自动判断lpMultiByteStr指定的字符串的长度
(如果字符串不是以空字符中止,设置为-1可能失败,可能成功),此参数设置为0函数将失败。
**5> lpWideCharStr:**指向接收被转换字符串的缓冲区。
**6> cchWideChar:**指定由参数lpWideCharStr指向的缓冲区的宽字节数。若此值为0,函数不会执行转换,而是返回目标缓存lpWideChatStr所需的宽字符数。
返回值:
如果函数运行成功,并且cchWideChar不为0,返回值是由lpWideCharStr指向的缓冲区中写入的宽字符数;
如果函数运行成功,并且cchMultiByte为0,返回值是待转换字符串的缓冲区所需求的宽字符数大小。(此种情况用来获取转换所需的wchar_t的个数)
如果函数运行失败,返回值为零。
若想获得更多错误信息,请调用GetLastError()函数。它可以返回下面所列错误代码:
ERROR_INSUFFICIENT_BUFFER; ERROR_INVALID_FLAGS;
ERROR_INVALID_PARAMETER; ERROR_NO_UNICODE_TRANSLATION。
使用方法
1>调用MultiByteToWideChar()函数,设置cchWideChar参数为0(用以获取所需要的接收缓冲区的大小)
2>获取输入缓存的大小,作为cchMultiByte的值(这样做是为了节省空间,也可以给cchMultiByte取值为-1(字符串需要以空字符串结尾,否则会出错))
3>分配足够的内存块,用以存放转换后的Unicode字符串:
该内存块的大小由前面对cchWideChar()函数的返回值来决定;(也可以用别的方法,但该方法更节省内存)
4>再次调用MultiByteToWideChar()函数,这次将缓存的地址作为lpWideCharStr参数来传递,并传递第一次调用MultiByteToWideChar()函数时的返回值作为cchWideChar参数的值;
5>使用转换后的字符串
6>释放接收缓冲区占用的内存块;
示例代码:
wstring ANSIToUnicode(const string& str)
{
int len = 0;
len = str.length();
int unicodeLen = MultiByteToWideChar(CP_ACP,
0,
str.c_str(),
-1,
NULL,
0);
wchar_t * pUnicode;
pUnicode = new wchar_t[unicodeLen + 1];
memset(pUnicode, 0, (unicodeLen + 1)*sizeof(wchar_t));
MultiByteToWideChar(CP_ACP,
0,
str.c_str(),
-1,
(LPWSTR)pUnicode,
unicodeLen);
wstring rt;
rt = (wchar_t*)pUnicode;
delete pUnicode;
return rt;
}
WideCharToMultiByte()
函数功能:该函数映射一个unicode字符串到一个多字节字符串
函数原型:
int WideCharToMultiByte(
UINT CodePage,
DWORD dwFlags,
LPCWSTR lpWideCharStr,
int cchWideChar,
LPSTR lpMultiByteStr,
int cchMultiByte,
LPCSTR lpDefaultChar,
LPBOOL pfUsedDefaultChar
);
参数:
与MultiByteToWideChar()函数中的参数类似,但是多了两个参数;
lpDefaultChar和pfUsedDefaultChar:只有当WideCharToMultiByte函数遇到一个宽字节字符,而该字符在uCodePage参数标识的代码页中并没有它的表示法时,WideCharToMultiByte函数才使用这两个参数。(通常都取值为NULL)
1> 如果宽字节字符不能被转换,该函数便使用lpDefaultChar参数指向的字符。如果该参数是NULL(这是大多数情况下的参数值),那么该函数使用系统的默认字符。该默认字符通常是个问号。这对于文件名来说是危险的,因为问号是个通配符。
2> pfUsedDefaultChar参数指向一个布尔变量,如果Unicode字符串中至少有一个字符不能转换成等价多字节字符,那么函数就将该变量置为TRUE。如果所有字符均被成功地转换,那么该函数就将该变量置为FALSE。当函数返回以便检查宽字节字符串是否被成功地转换后,可以测试该变量。
返回值:
如果函数运行成功,并且cchMultiByte不为零,返回值是由 lpMultiByteStr指向的缓冲区中写入的字节数;
如果函数运行成功,并且cchMultiByte为零,返回值是接收到待转换字符串的缓冲区所必需的字节数。(此种情况用来获取转换所需Char的个数)
如果函数运行失败,返回值为零。
若想获得更多错误信息,请调用GetLastError函数。它可以返回下面所列错误代码:
ERROR_INSUFFICIENT_BJFFER;ERROR_INVALID_FLAGS;
ERROR_INVALID_PARAMETER;ERROR_NO_UNICODE_TRANSLATION。
示例代码:
string UnicodeToANSI(const wstring& str)
{
char* pElementText;
int iTextLen;
// wide char to multi char
iTextLen = WideCharToMultiByte(CP_ACP,
0,
str.c_str(),
-1,
NULL,
0,
NULL,
NULL);
pElementText = new char[iTextLen + 1];
memset((void*)pElementText, 0, sizeof(char) * (iTextLen + 1));
WideCharToMultiByte(CP_ACP,
0,
str.c_str(),
-1,
pElementText,
iTextLen,
NULL,
NULL);
string strText;
strText = pElementText;
delete[] pElementText;
return strText;
}
Unicode to UTF-8
string UnicodeToUTF8( const wstring& str )
{
char* pElementText;
int iTextLen;
// wide char to multi char
iTextLen = WideCharToMultiByte( CP_UTF8,
0,
str.c_str(),
-1,
NULL,
0,
NULL,
NULL );
pElementText = new char[iTextLen + 1];
memset( ( void* )pElementText, 0, sizeof( char ) * ( iTextLen + 1 ) );
::WideCharToMultiByte( CP_UTF8,
0,
str.c_str(),
-1,
pElementText,
iTextLen,
NULL,
NULL );
string strText;
strText = pElementText;
delete[] pElementText;
return strText;
}
UTF-8 to Unicode
wstring UTF8ToUnicode( const string& str )
{
int len = 0;
len = str.length();
int unicodeLen = ::MultiByteToWideChar( CP_UTF8,
0,
str.c_str(),
-1,
NULL,
0 );
wchar_t * pUnicode;
pUnicode = new wchar_t[unicodeLen+1];
memset(pUnicode,0,(unicodeLen+1)*sizeof(wchar_t));
::MultiByteToWideChar( CP_UTF8,
0,
str.c_str(),
-1,
(LPWSTR)pUnicode,
unicodeLen );
wstring rt;
rt = ( wchar_t* )pUnicode;
delete pUnicode;
return rt;
}
char 转换成 LPCTSTR*
char ch[1024] = "hello world";
int num = MultiByteToWideChar(0,0,ch,-1,NULL,0);
wchar_t *wide = new wchar_t[num];
MultiByteToWideChar(0,0,ch,-1,wide,num);
解析:
num 获得长字节所需的空间
MultiByteToWideChar()表示将s中的字符传递到ps指向的内存中。-1表示传输至s中的’\0’处,num表示传递的字节个数。
LPCTSTR 转换成 char *
wchar_t widestr[1024] = L"hello world";
int num = WideCharToMultiByte(CP_OEMCP,NULL,widestr,-1,NULL,0,NULL,FALSE);
char *pchar = new char[num];
WideCharToMultiByte (CP_OEMCP,NULL,widestr,-1,pchar,num,NULL,FALSE);
LPCTSTR等价于wchar_t














 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









