







目标:
乌云网是国内最大最权威的安全平台,所以乌云网的注册厂商都是业较有影响力的厂商,我们的最终目的是通过乌云网拿到所有厂商的url,即主站域名,随后调用subDomainsBrute能批量暴力扫描子域名,最后将所有得到的子域名通过AWVS漏扫接口批量扫描,从而达到了批量、全面扫描国内网站巨头站点的目标。
本次目标:
乌云网的厂商列表有43页、844条厂商记录,页面为http://www.wooyun.org/corps/page/1到http://www.wooyun.org/corps/page/43,。本次写一个爬虫扫描这些网页将得到的url存储到本地。
代码
# -*-coding:UTF-8 -*-
from urllib import urlretrieve
import re
def getWooyunUrl():
L = []
for i in range(1, 44):
url = "http://www.wooyun.org/corps/page/" + str(i)
try:
revtal = urlretrieve(url)[0]
except IOError:
revtal = None
f = open(revtal)
lines = ''.join(f.readlines())
regex = '_blank">(.*)</a'
for m in re.findall(regex, lines):
if(m[0] == 'h'):
L.append(m)
L = [line + '\n' for line in L]
f = open("wooyun.txt", 'w')
f.writelines(L)
f.close()
if __name__ == '__main__':
getWooyunUrl()
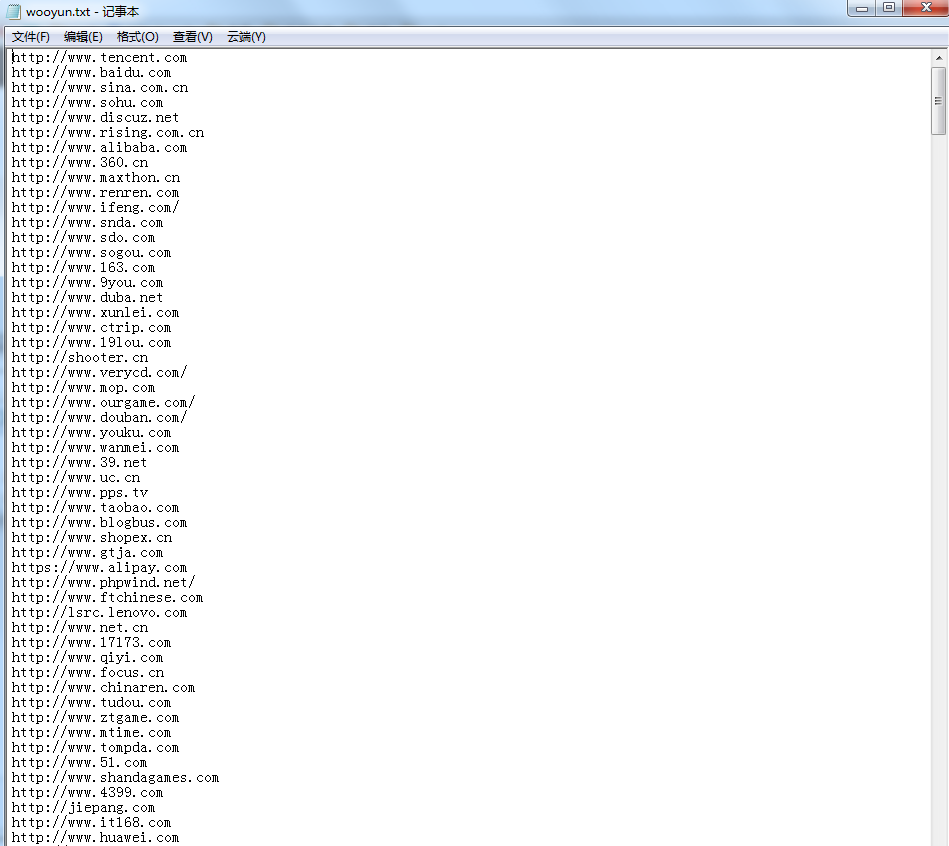
大约200秒之后,本地会生成wooyun.txt文件里面包含所有url。

文件内容:














 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









