







总结:
上文中,KMP算法和BM算法,这两个算法在最坏情况下均具有线性的查找时间。但实际上,KMP算法并不比最简单的c库函数strstr()快多少,而BM算法虽然通常比KMP算法快,但BM算法也还不是现有字符串查找算法中最快的算法,比BM算法更快的查找算法即Sunday算法。
这篇文章已经详细描述:http://blog.csdn.net/v_july_v/article/details/7041827
什么是字符串最长公共前缀后缀长度?(详解:http://www.cnblogs.com/NYNU-ACM/p/4236872.html)
当模式匹配字符串遇到 j 不匹配的字符,调转到next[j]的模式匹配字符串位置,继续匹配。如果next [j] 等于0或-1,则跳到模式串的开头字符。
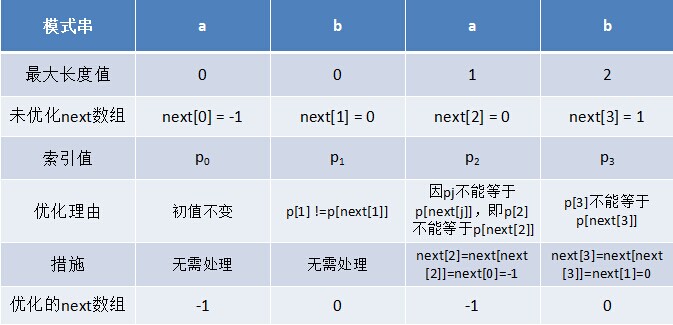
代码实现:
//next 数组求法
void GetNext(char* p,int next[])
{
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1)
{
//p[k]表示前缀,p[j]表示后缀
if (k == -1 || p[j] == p[k])
{
++k;
++j;
next[j] = k;
}
else
{
k = next[k];
}
}
}
//优化过后的next 数组求法
void GetNextval(char* p, int * next)
{
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1)
{
//p[k]表示前缀,p[j]表示后缀
if (k == -1 || p[j] == p[k])
{
++j;
++k;
//较之前next数组求法,改动在下面4行
if (p[j] != p[k])
next[j] = k; //之前只有这一行
else
//因为不能出现p[j] = p[ next[j ]],所以当出现时需要继续递归,k = next[k] = next[next[k]]
next[j] = next[k];
}
else
{
k = next[k];
}
}
}
int KmpSearch(char* s, int sLen, char* p, int pLen, int * next)
{
int i = 0;
int j = 0;
while (i < sLen && j < pLen)
{
//①如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++
if (j == -1 || s[i] == p[j])
{
i++;
j++;
}
else
{
//②如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]
//next[j]即为j所对应的next值
j = next[j];
}
}
if (j == pLen)
return i - j;
else
return -1;
}扩展1:BM算法(最顶端链接有详解)
坏字符规则:当文本串中的某个字符跟模式串的某个字符不匹配时,我们称文本串中的这个失配字符为坏字符,此时模式串需要向右移动,移动的位数 =
坏字符在模式串中的位置 - 坏字符在模式串中最右出现的位置。好后缀规则:当字符失配时,后移位数 = 好后缀在模式串中的位置 - 好后缀在模式串上一次出现的位置,且如果好后缀在模式串中没有再次出现,则为-1。
扩展2:Sunday算法(最顶端链接有详解)
只不过Sunday算法是从前往后匹配,在匹配失败时关注的是文本串中参加匹配的最末位字符的下一位字符。
如果该字符没有在模式串中出现则直接跳过,即移动位数 = 匹配串长度 + 1;
- 否则,其移动位数 = 模式串中最右端的该字符到末尾的距离+1。















 3820
3820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









