








一、项目展示
在这里,主要展示大数据图表分析的几个页面。更多精彩由您自己发掘!
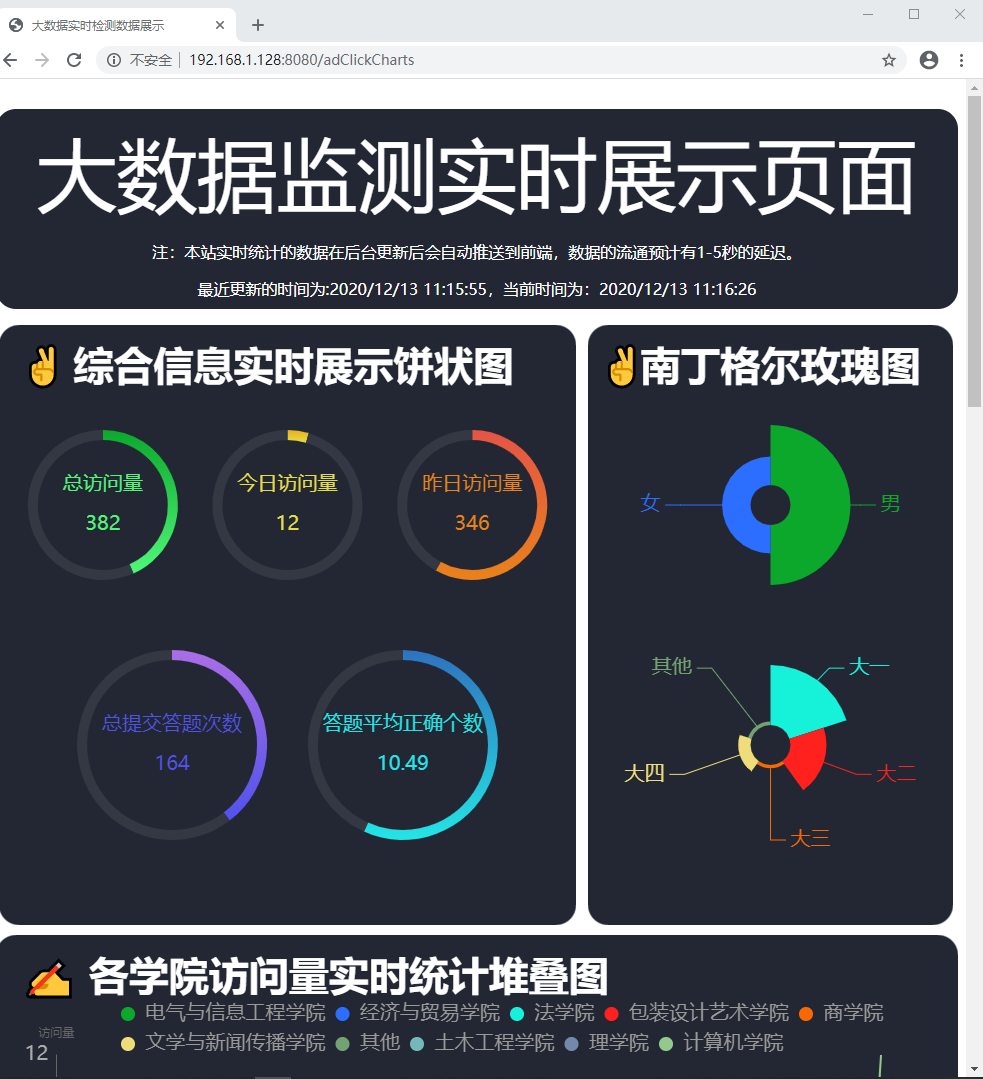 图1 饼状图 图1 饼状图
|
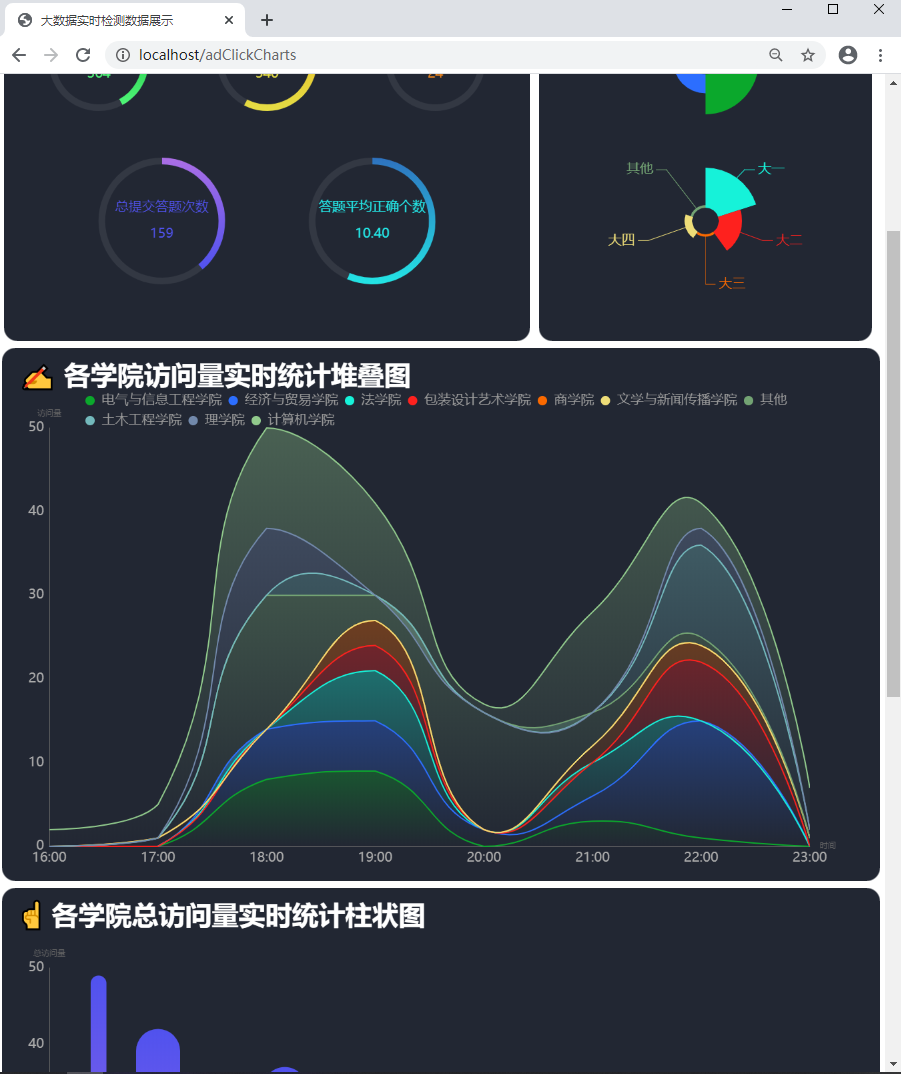 图2 堆叠图 图2 堆叠图
|
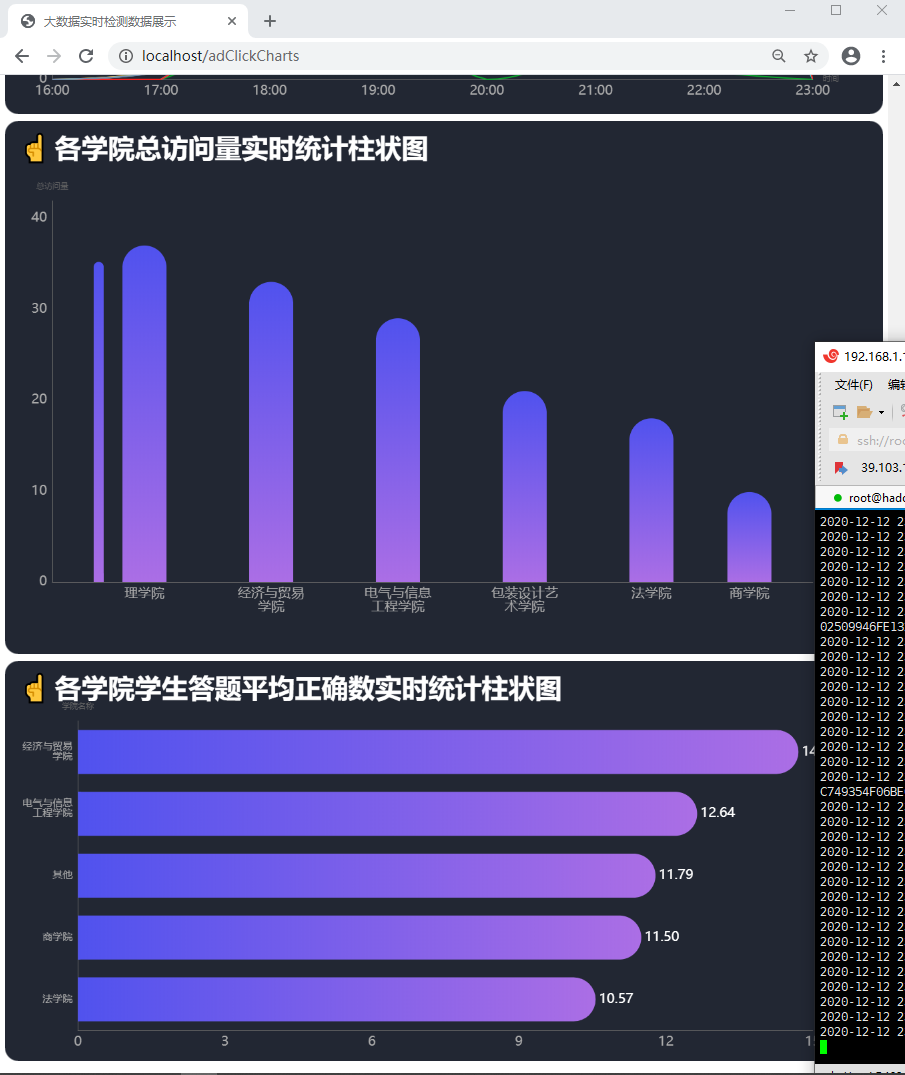 图3 柱状图 图3 柱状图
|
二、项目介绍
本项目分为两个模块,第一个为java语言基于springboot实现的答题模块,另一个为scala语言基于spark开发的日志分析模块。
1、答题模块
基于SSM框架实现,具体使用的技术有:spring,springMVC,mybatis,redis等,使用的数据库为:mysql数据库。
用户输入学号、姓名等相关信息即可完成登陆(未注册自动注册),然后进入答题界面参与答题,答题结束后显示成绩,然后引导跳转到大数据实时展示页面。上述这些操作都将被日志文件记录下来,保存在日志文件内。
当有新的数据插入或者更新mysql的时候,本模块的websocket能在100ms内把最新的数据广播给当前左右在线的浏览器,反之如果数据库没有新数据插入,那么短时间内则不会自动广播。
2、scala数据分析模块
基于spark实现,具体使用的技术由,kafka,flume,spark,redis,zookeeper等,使用的数据库为mysql。
首先flume负责采集日志文件中的日志信息,转交给kafka,再由spark程序来消费,清洗、分类、分析聚合后写入数据库。
当有新数据写入mysql的时候,本模块会利用redis引导答题模块用websocket技术实时往当前在线浏览器推送最新数据。从访问到浏览器刷新,整个流程延迟在1-2秒左右。
三、项目说明
1、源代码下载地址
下载链接:https://pan.baidu.com/s/188VaxHtI7eFsIbJHnrrvbA 提取码:5jsp
2、开发环境
虚拟机版本:centos8
编译器:idea 2020.1.3
数据库:mysql 5.7
答题模块:见pom.xml文件
kafka版本:kafka_2.12-2.5.0.tgz
flume版本:apache-flume-1.9.0-bin.tar.gz
spark版本:spark-3.0.0-bin-hadoop3.2.tgz
zookeeper版本:apache-zookeeper-3.6.1-bin.tar.gz
3、项目运行流程
准备工作:
①导入mysql.sql文件,将数据库和表建好。
②修改两个模块的数据库连接四要素,以及redis的连接密码等信息。
③将两个模块的代码打包发到linux操作系统。
④启动zookeeper集群和kafka集群
启动项目:
①进入kafka根目录创建kafka主题(需对中间参数做必要修改)
bin/kafka-topics.sh --create --zookeeper hadoop1:2181 --replication-factor 1 --partitions 1 --topic solvingProblem
注意:若要修改topic,记得整个项目都全部改。
②启动kafka消费数据
bin/kafka-console-consumer.sh --bootstrap-server hadoop:9092 --topic solvingProblem
③进入flume根目录启动flume采集日志文件
bin/flume-ng agent -n a1 -c conf/ -f ./flume.conf
④启动答题模块的springboot项目
nohup java -jar solvingProblem.jar >/root/log/run.log 2>/root/log/error.log &
日志文件保存在/root/log/run.log内,错误日志保存在/root/log/error.log内。若要改路径,记得把flume.conf中的路径也一起改了。
⑤进入spark根目录启动spark,对日志文件进行实时分析
bin/spark-submit --class com.hut.anli.Solving --master local[*] /root/Anli.jar
项目预览:
当你成功的完成了上述步骤之后,你就可以在浏览器输入你虚拟机的IP加8080端口,即可访问该项目了。
四、项目后记
学大数据已经有3个来月了,一直没有写过能解决实际问题的项目。直到上周,一个社团的负责人找到我说,让我帮忙写个网页答题系统,用于社团在12月13日国家公祭日,铭记历史告慰亡灵的一次活动。因为上半年我刚好完java后端这一块,这对于我来说基本没啥问题,并且我也曾经是该社团的负责人之一,于是我就答应了。
他只跟我说了要做一个网页答题系统,其他的信息让我自己构思与设计。于是我想了想,网上答题怕是有至少一两千人参加吧,并发量会不会很高啥的,我有想过借用朋友的服务器和我自己的服务器搞一个集群部署,防止服务器扛不住压力而宕机,还有啥校园内网、公网相结合部署的方式顿时出现在了我的脑海中…
一想到这些我还是很慌的,因为我从来都没有做过如此大规模的项目,集群部署我只看过、学过但并没有自己亲手操作过,当时我没顾那么多,走一步看一步的心态写下去了。后面当我写前端页面的时候,我跟他们要了一份活动策划书参考点文案,当我拿到活动策划书的时候,我顿时松了口气,活动人数就300,害,人这么少压根不需要集群部署啊,一台机器就够了,于是我花了两天的时间把答题系统写完,然后进行了基础的bug测试,目测可以上线使用了。
 图4 项目首页图1 图4 项目首页图1
|
 图5 项目首页图2 图5 项目首页图2
|
 图6 答题返回页面 图6 答题返回页面
|
由于我是第一次开发大数据综合项目,然后对前面学的的知识记得不是很清楚,又要对多个组件进行整合,这个模块花了我大概5天的时间才完成,下面详细说说这几天开发的内容。
皮这一下很开心,哈哈哈哈嗝!!!

首先就是配置flume的相关参数,因为从文本中获取数据,所以这里使用sources的类型是exec;然后就是对channel的选择,由于是做实时统计系统,追求低延迟,又加上数据量不是特别大,所以这里我选择的是memory channel;对于最后的sink无意就是kafka sink了。sources、channel和sink,他们三个的类型都特别多,因此根据实际的需求使用相对更合适的类型就显得尤为重要了。
接着是处理kafka,这一步工作量比较少,创建一个solvingProblem的topic,再开启kafka控制台消费即可,其实你不开也没关系,但是你开了,能在控制台看到程序运行的状态,比如报错等信息,你能立马发现。
后面在系统正式交给社团使用的时候,当时是晚上将近23点了,由于我实时盯着kafka在console输出的信息,当我发现了异常后,及时通知正在答题的同学让他们停止答题,将系统下线进行bug调试修改,经过半个小时的紧急修复,才避免了当时正在作答的同学的信息丢失问题。
再然后是编写scala程序,利用kafka的API开发,数据生产在虚拟机上,将获取到的数据进行清洗、分类,这个过程需要非常细心并且如何选择转换算子去转换,在大数据中也大有讲究,这一步骤写的好坏,将直接影响写出来的程序的执行效率问题。写好之后,打成jar包发到Linux备用。在这个过程中,你需要知道转换算子和执行算子的工作方式,以及他们的特性。并且,在什么时候,什么地方,使用哪个算子将分析好的数据插入数据库,以及什么时间点修改redis中的变量的值,好让答题模块直到你改数据了,好及时往前端广播最新的数据,这些都大有讲究!
最后就是对他们进行一连串的整合了,回顾一下,数据的来源以及数据的走向,中间的组件启动命令什么,这些我都要记住,记不住就写在本子上,防止慌慌张张忘了就尴尬了。按照上面的步骤把系统启动之后,系统答题的功能,基本就实现了。但你的项目部署在Linux虚拟机上,想让学校内网中的其他同学访问还是不行的,因此我在我宿主机上装了个nginx请求转发,这里涉及到http和websocket两种请求的转发,把宿主机上nginx启动之后,才真正的把项目做好。
在项目运行之后,我电脑内存已经达到85%左右了,但我还是顶着内存爆炸的风险,使用jmeter做了一次服务器压力测试,结果还算比较乐观,1000个线程在1秒内循环发送5个请求服务器运行正常,到此本系统就算开发完成。并且我也在今天中午14点成功的完成对本系统的维护,将数据库收集到的数据教导社团负责人手中,认真负责的完成了开发人员和维护人员的任务。
最后,谢谢你的浏览。如果你觉得我写的好的话,可以关注一下我,我近期还会更新一些关于大数据分析的开源项目。














 2157
2157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









