







来源:驭势未来
视觉定位与导航技术是智能体具备的基础能力之一,随着无人驾驶的发展,基于低成本摄像头及人工智能算法的视觉定位与导航技术成为了无人驾驶的主流技术路线之一。在传统工作方式中,视觉定位与导航技术通常采用SLAM(Simultaneous Localization And Mapping,同步定位与建图)的方式构建一个几何地图,然后在地图中进行路径规划和导航。在每一个时刻,无人车可以通过使用当前图像和地图比对的方式,或者采用视觉里程计的方式,估计当前相机的位姿进行无人车定位。
但在开放、复杂的无人驾驶场景中,视觉定位与导航技术在传统工作方式下还存在一些明显的挑战:
Part 1
视觉定位的挑战
一、摄像头视角有限
有限的摄像头视角,限制了无人车在停车场等拥堵场景中做到实时鲁棒的位姿估计。一方面,当相机发生旋转,偏移建图路线的时候,有限的可视角度会导致特征点丢失。另一方面,当场景中动态物体较多的时候,可能导致相机的视野中被动态的车辆和行人占满,导致位姿估计错误。
基于此,我们采用了鱼眼相机、多相机等作为传感器,显著扩大了视觉定位中的摄像头视角。
鱼眼相机:应用鱼眼相机可以为视觉定位创造一个超大范围的场景视角,但同时鱼眼相机也存在较大的畸变这一挑战,大畸变使得普通的相机模型无法适配,并且普通的描述子也不能适用。另外目前常见的开源SLAM系统,如ORB-SLAM等并不能很好地支持鱼眼SLAM模型。针对这个问题,我们提出了一种基于立方体展开相机模型的SLAM系统(CubemapSLAM,图1),该模型既可以有效去除鱼眼相机图像中存在的较大畸变,又能够保留原始图像所有的场景视角。目前,在公开数据集和驭势科技自主采集的数据集中,我们的算法均优于已有的鱼眼SLAM方法。

图1
我们的方法已于去年发表在ACCV2018,同时对我们的CubemapSLAM算法进行了开源,欢迎大家使用并反馈。
链接:
https://github.com/nkwangyh/CubemapSLAM
此外更重要的是,我们研究的算法并没有停留在论文阶段,而是更进一步,落地于公司商业化运营项目,在真实的自主代客泊车(AVP)场景中进行了运用(图2)。
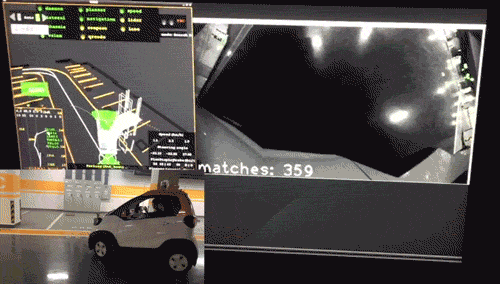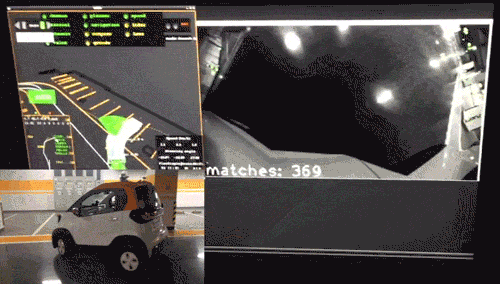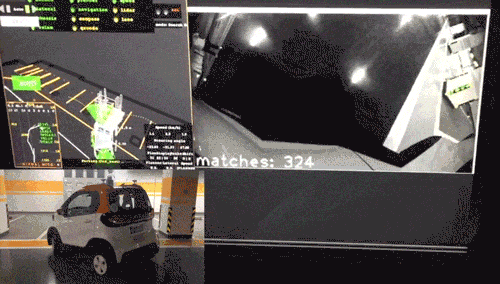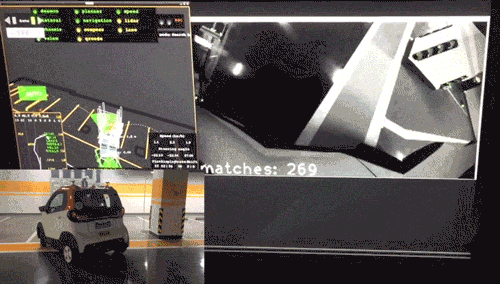
图2
多相机系统:我们研发了紧耦合多相机的SLAM定位系统(图3)。在多相机系统中,由于每个相机的光心位置不同,因此,我们采用了一种叫做General Camera的模型来表达多相机系统。同时,多相机系统的精度受相机之间的外参影响比较大,因此标定的质量非常关键。除了常规静态标定之外,我们还将多相机的外参纳入到SLAM系统的优化框架中。

图3
二、Long-Term Visual Localization
自动驾驶视觉定位的另一个重大挑战是光照和环境的变化。同样的一个场景,如果建图的时间是白天,定位的时间是晚上,我们也需要无人车能够稳定工作。夏天建的图,到了冬天,定位系统也要能识别出来。因此,我们需要实现自动驾驶在不同光照与环境变化中的“Long-Term Visual Localization”任务,而这一任务,我们一般又划分为位置识别(Place Recognition)和位姿估计(Metric Localization)两项子任务。
位置识别任务旨在找到相机在地图中的大致位置,即找到地图数据库中跟当前图片最相近的一张图。最常见的传统做法一般是采用Bag-of-Words(BoW)技术,把图片中的SIFT,ORB等特征点转化成向量表示。在这个向量空间上最接近的图片,即认为是当前图片所在的位置。
但通过位置识别任务得到的只是当前相机的大致位置,在无人驾驶中,为了得到相机和车辆的精确位置,我们还需要接着做位姿估计。一般在这一步,算法会把当前图像上的特征点和地图中的特征点进行特征匹配(Feature Matching), 根据成功匹配的特征点计算中相机的最终精确位置。
位置识别和位姿估计这两项任务还存在很多挑战,面对其中最主要的挑战:光照和环境的变化,我们采取了深度学习(Deep Learning)的方法。目前,深度学习已经在计算机视觉多个领域得到广泛验证,具备超越传统方法的应用能力。
位置识别(Place Recognition):对于位置识别任务而言,如果我们把每一个位置当做一个类别(Class),那么我们有很容易获取的Label : GPS作为监督信号。GPS的坐标值本身是连续的,两个坐标之间的欧式距离可以反应出两张图之间的远近。因此可以把这个问题当做度量学习(Metric Learning)来训练。通过这样训练出来的Feature,可以做到大幅超过BoW的位置识别效果。我们在这种网络基础之上,提出了Landmark Localization Network (LLN,图4),帮助挑选出图像中最有显著性的部分。从结果中我们看到,仅仅使用GPS这个弱监督信号,我们却学习出了跟Place Recognition这个任务最相关的特征,如图6所示,我们对LLN网络的Feature Map进行了可视化,在第二行中我们看到垃圾桶部分的响应比后面的红墙要高很多,而在第三行中旅馆的招牌也得到较高的响应。我们的结果已发表在ICRA19。
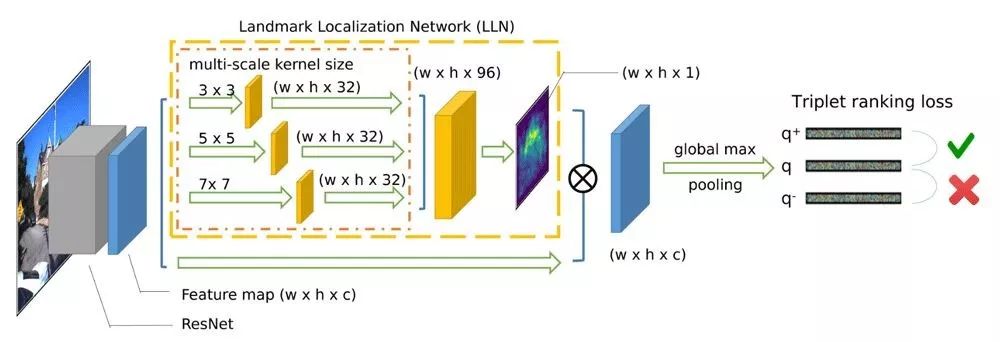
图4

图5
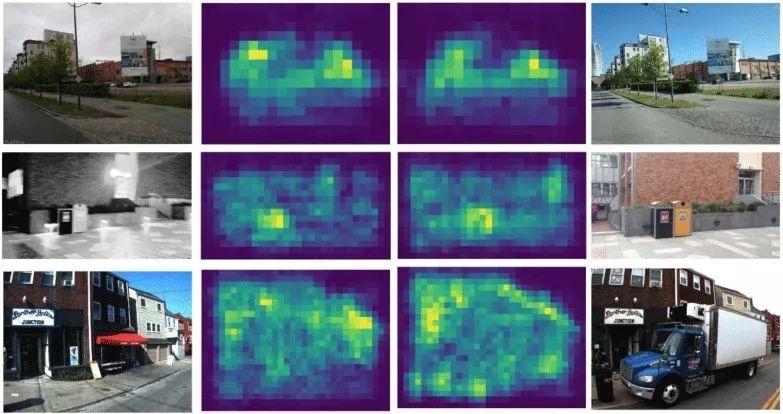
图6
我们也尝试了使用GAN的方法来进行不同光照之间的变换。跟以往做法不同的是,我们可以做到在连续时间域上对图像进行连续变换(图7)。从图8可以看到,当把当前图像变换到和地图中的时刻后,特征匹配的数量会大幅提高。

图7

图8
位姿估计(Metric Localization):在位姿估计这一任务中,传统的方法会使用ORB,SIFT等特征进行匹配和解算位姿。目前也有很多使用CNN进行特征点提取(Detection)和描述(Description)的方法,比如Superpoint是其中效果比较好的一种。我们在Superpoint的基础上进行了改进,加入了Saliency Ranking机制(图9),在特征点提取数量较少的情况下,可以达到比Superpoint更高的重复率(Repeatability,图10)。我们用这个方法参与了今年CVPR19的Local Feature Challenge,并最终进入了前三名。
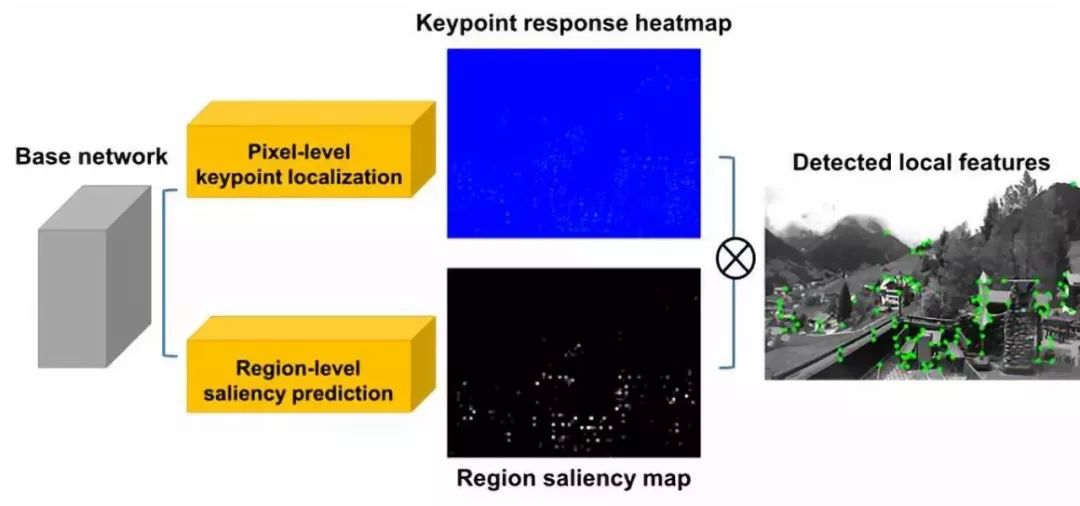
图9

图10
在这个基础上,我们也训练了一些检测器去识别高层语义特征,比如道路上的标牌,车道线,路灯杆等等。这些特征在公共道路上面普遍存在,相比较Low-Level特征点,这些语义特征更加稀疏和可靠。
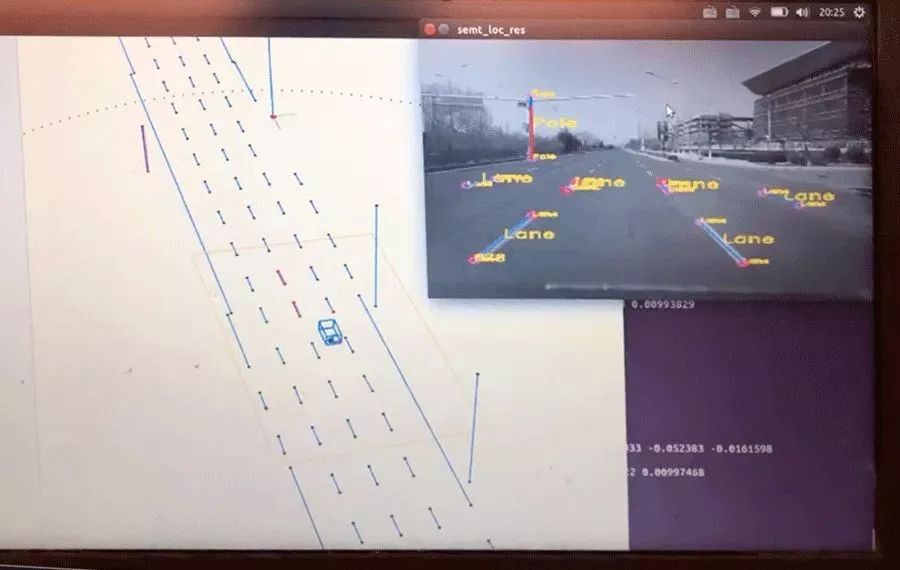
图11

Part 2
Navigation
地图和定位都是最终为了导航而服务。例如上述两点中的位姿估计(Metric Localization),对于人类司机来说并不是必须的,人并不会每时每刻知道自己的位姿。因此,我们也引入了一些相对导航的机制,例如利用车道线、灭点等信号,让车辆学会怎么沿着路开。
2017年,在我们和清华大学合作参与的一个Vizdoom比赛(图12)中,我们率先使用了SLAM和导航结合的技术。这个比赛环境是基于Doom(一款3D系列射击游戏)的第一人称射击游戏,选手的任务是在一个环境中移动和射杀对手,并赚取尽量多的分数。为了能很好地完成这个任务,空间感知能力是一个基础。而一般的深度强化学习方法并不会显式地表达这个空间概念。因此我们把SLAM构建的地图和强化学习网络相结合,通过把周围空间环境的信息加入到网络中提升了强化学习的空间感知能力,并最终在这个比赛中获得了第二名的好成绩。
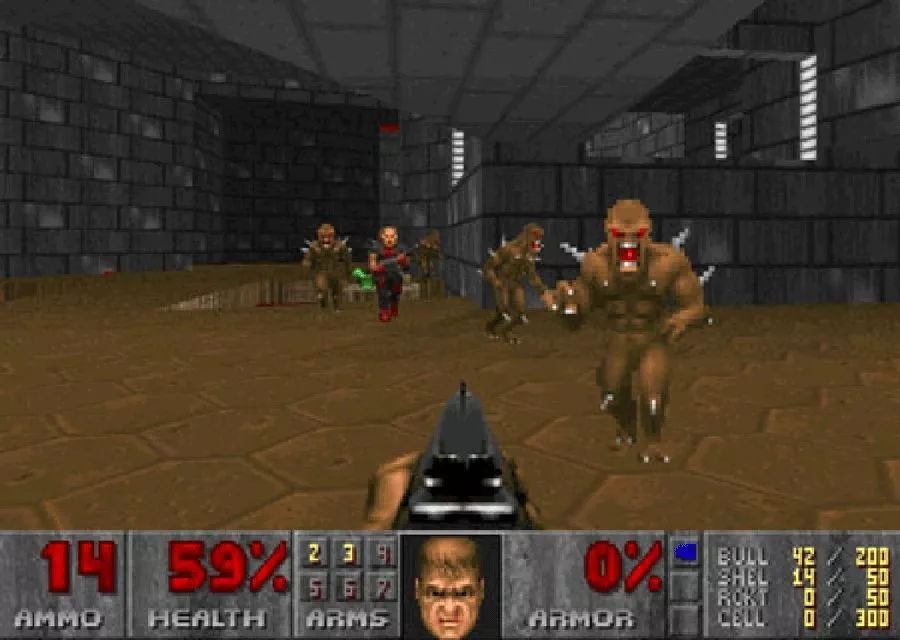
图12
此外,驭势科技自主研发了驭势智能驾驶仿真系统,其场景画面和真实场景高度相似。因此我们可以在仿真平台中训练行车策略, 并且部署到真实场景中。

图13 基于仿真平台的Vanishing Point训练
我们还在Navigation上面做着更多的探索,More To Be Continued, Please Stay In Tune!

未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”















 1702
1702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









