






有时开发人员只关心速度。忽略消息传递的所有其他优势,他们会问我们以下问题:RPC 不是比消息传递更快吗?
RPC可能会有其他不同的术语或技术,如 REST、微服务、gRPC、WCF、Java RMI 等。但是,无论使用哪个特定词,其含义都是相同的:通过 HTTP 进行远程方法调用。所以我们将简称为“RPC”。
有些人会声称任何类型的 RPC 通信最终都比使用异步消息传递的任何等效调用更快(意味着它具有更低的延迟)。但答案并没有那么简单。这不是苹果与橙子的比较,更像是苹果与橙子的果子露。
为什么 RPC “更快”
简单地编写一个微基准测试很诱人,我们通过 HTTP 向服务器发出 1000 个请求,然后用异步消息重复相同的测试。但公平地说,我们还必须在服务器上处理消息,然后才能认为消息传递案例是完整的。
如果您进行了这样的基准测试:最初,消息传递解决方案需要比 RPC 更长的时间才能完成。这是有道理的!毕竟,在 HTTP 的情况下,我们打开一个从客户端到服务器的直接套接字连接,服务器执行其代码,然后在已经打开的套接字上返回响应。在消息传递的情况下,我们需要发送一条消息,将该消息写入磁盘,然后另一个进程需要接收并处理它。有更多的步骤,所以很容易解释增加的延迟。
但这只是一个微基准,并不能告诉你整个故事。
线程和内存
您实战中通常使用的RPC不是单个RPC调用,而是一个服务调用另一个服务,另一个服务调用另一个服务,依此类推。即使是一个不转过来调用另一个服务的服务,通常也必须做一些事情,比如与数据库对话,这是另一种形式的 RPC。
当您进行这些远程调用时,线程和内存会发生什么?
当您开始远程调用时,您分配的任何内存都需要保留,直到您得到响应。您在编码时甚至可能不会考虑这一点,但是您在 RPC 调用之前声明的任何变量都必须保留它们的值。否则,一旦收到回复,您将无法使用它们。
同时,垃圾收集器(或任何在运行时环境中管理内存的东西)试图通过清理不再使用的内存来提高效率。
垃圾收集器的设计假设内存应该被合理地快速清理。因此,在相对较短的时间内,垃圾收集器将执行第 0 代 (Gen0) 收集,在此期间它会询问您的线程:“您完成了那块内存吗?” 不,事实证明,您仍在等待来自 RPC 调用的响应。“没问题,”垃圾收集器会说,“我稍后回来和你核实。” 并且它将该内存标记为第 1 代 (Gen1),因此它知道不要过早地再次打扰您的线程。
大约 50,000 次 CPU 操作之后,垃圾收集器将进行 Gen1 内存收集。就 CPU 周期而言,这是一个很长的时间,但对我们人类来说可能大约是 50 微秒,这根本不算什么。就远程调用而言,时间也不长,这比本地函数执行慢得多。“你现在处理完那个 内存了吗?” 你的线程被震惊了——垃圾收集器难道不知道远程调用需要多长时间?“没问题,”收集器说,“我晚点再来。” 它将您的记忆内存为 Gen2。
垃圾收集器活动的实际时间在很多方面都会有所不同,但关键是您的内存可以在您的 RPC 调用完成之前放入 Gen2。这很重要,因为垃圾收集器不会主动清理 Gen2 内存。因此,即使您从服务器获得响应并且您的方法完成,您的 Gen2 内存可能不会被清除,但IDisposable对象除外。
常规内存仅位于 Gen2 中。如果这些调用需要足够的时间来返回,则在调用远程调用时,您本质上会出现轻微的内存泄漏。该内存会一直累积,直到系统负载足够大以至于无法再分配额外的内存。
然后垃圾收集器说,“哦,哦,我想我最好对这个 Gen2 内存做点什么。”
按下核按钮停止世界
这是 RPC 系统的吞吐量开始偏离轨道的地方。
垃圾收集器已经两次尝试清理 Gen2 内存,并且显然正在被线程主动使用。所以垃圾收集器唯一的选择就是挂起进程中所有当前正在执行的线程来清理Gen2内存。
那时你的 RPC 系统的吞吐量开始看起来像这样:
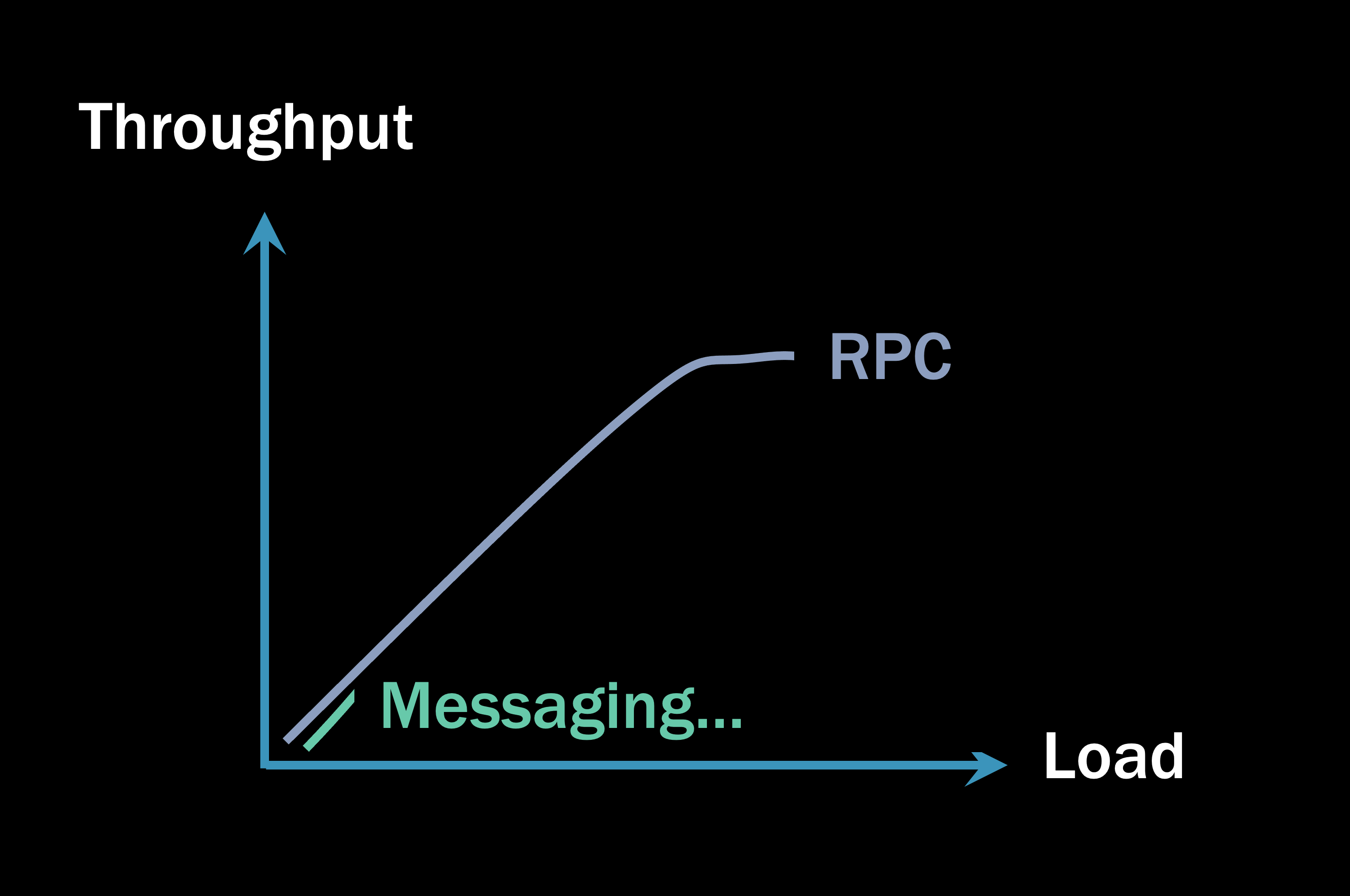
负载轴上的刻度现在扩展到微基准之外。当垃圾收集器开始挂起进程的线程以清理内存时,所有等待您响应的客户端现在必须等待更长时间。
这会产生危险的多米诺骨牌效应。随着系统的一部分变慢,它对其客户端的响应速度变慢,这意味着它们的内存进入 Gen2 的速度更快,这意味着它们的垃圾收集器将更频繁地挂起它们的线程,这意味着它们的客户端必须等待更长时间……你可以看到在哪里这是去。从一个微服务到下一个微服务的 RPC 调用堆栈越深,累积的内存压力就越大。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cQaIsypR-1632792552375)(https://particular.net/images/blog/2021/rpc-vs-messaging/3-rpc-out-of-memory.png)]
进程无法启动更多线程来处理额外的传入请求,因为它耗尽了内存。同时,您,客户端,收到异常“远程主机拒绝连接”。您收到了响应,但服务器说,“看,我太忙了。晚点你还得回来。” 它无法启动更多线程并且正在减载,这是 RPC 系统必须处理超额负载的唯一机制。
如果您只有一个客户端和一个服务器,这通常不会有什么大不了的。但是您拥有的移动部件越多,系统就越脆弱。
消息系统
建立在消息传递上的系统在负载下通常会超过基于 RPC 的系统的吞吐量。
建立在消息队列上的系统不像 RPC 系统那样进行减载,因为它们在磁盘上有存储空间来存储传入的请求。这使得基于队列的系统在更高的负载下比 RPC 系统更具弹性。它不使用线程和内存来保持请求,而是使用持久磁盘。因此,即使在系统以峰值容量处理时,队列中也可能有更多消息。
这就是为什么像本文开头那样使用微基准比较 RPC 和消息传递就像苹果和橙子果子露一样:如果您被允许丢弃您喜欢的任何请求,这不是一个公平的比较。消息传递是不允许这样做的。
在基于消息的系统中,通常不需要等待来自其他微服务的响应。我收到一条消息,我在我的数据库中写了一些东西,也许我会发送额外的消息,然后继续下一个。基于消息的微服务彼此并行运行。无需等待,负载下的消息处理将根据您配置的数量扩展到某个点:并发处理消息的最大数量。
由于所有并行处理且无需等待,消息传递架构通常会在负载下超过 RPC,从而导致更高(更重要的是,稳定)的整体吞吐量。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ebj9jezb-1632792552377)(https://particular.net/images/blog/2021/rpc-vs-messaging/4-final.png)]
吞吐量高多少?这在很大程度上取决于系统、您如何设计它、数据库是否是瓶颈以及其他一百万个因素。但通常,异步处理模型会产生更多的并行处理结果,从而为您的系统带来比同步阻塞 RPC 模型更高的吞吐量。
总结
每当我们使用同步 RPC 模型时,总会有“史诗般的失败”场景的风险。始终存在这样的风险:RPC 系统将开始耗尽线程和内存,垃圾收集器将开始更频繁地挂起线程,系统将做更多的内务而不是业务工作,不久之后,它就会失败。
建立在异步消息传递上的系统不会像那样失败。即使 RPC 系统没有失败,消息系统通常也会超过 RPC 系统的吞吐量。















 4098
4098











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









