










原文链接:http://www.hellodb.net/2009/12/hash_partition.html
在面试时经常会问一个问题,请列举出hash在数据库内部的应用,hash的原理虽然简单,但是它在数据库中可以说是无处不在。其中hash partition是hash在数据库中一个简单的应用,虽然它没有range partition那么常用,但是我们在做数据库水平拆分时,其实就是利用了hash partition的原理,利用hash函数对某个key进行运算,然后将其分布到不同的主机上,原理很简单。
我们在设计时遇到了一个问题,当分区的数量需要变化时,基于hash的原理,数据可能会从一个分区移动到另外一个分区,因为某个key在4个分区时,可能被分布在分区3,而在8个分区时,可能被分布在分区5。这样每当分区数量变化时,就需要全部重新分布数据,代价很高。
那么Oracle是怎么做的?首先可以肯定的是Oracle的hash partition在分区增加时,不需要做全部数据的重新分布。有人告诉我Oracle的hash函数比较牛,可以保证分区数量增加时,这个hash函数可以让原来的数据还在旧的分区中,而新的数据可以分布在新的分区。Oracle的函数无非就是get_hash_value或ora_hash(10g),从hash的原理上来说,这也是不可能做到的。
我们对hash partition都有一个常识,就是partition的数量最好是2的次方,也就是2,4,8,16……,否则分区会出现不分区均衡的现象,按照hash的原理,不管是几个分区,都可以做到完全均衡的,为什么会不均衡,其实答案已经出来了,Oracle为了能够增加分区,为你预留了几个看不到的分区。
假设我们有6个分区,一共8000条数据,数据的分布如下图:
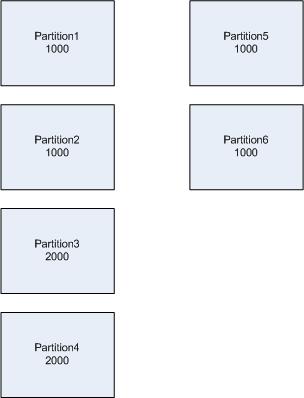
hash partition不能直接增加分区,而是split当前分区,当需要增加到8个分区时,实际上是分区3和分区4分别split产生新的分区7和分区8,如下图:
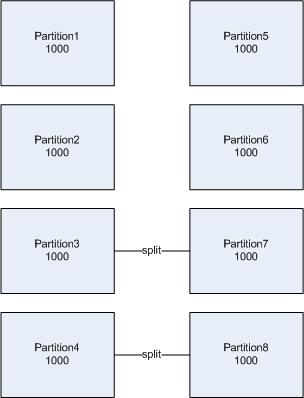
Oracle如何做到分区数量增加后,其他分区的数据不受影响呢,其实很简单,Oracle在做hash运算时,预留了分区,比如6个分区,实际上是用8个分区的hash来运算的,只不过把缺少的分区的数据合并到其他分区,这样就会出现数据不均衡的情况。Oracle的公式是这样的,用等于或者大于当前分区数量的最小的一个2的N次方,比如6个分区做8个hash bucket。我们再来考虑一下2,4,8,16(2的N次方)的情况,比如要把4个分区加为5个分区,因为已经是2的N次方,所以数据会均匀分布,而且Oracle还是使用4个hash bucket。这时新增的分区5实际上把分区1 split后产生的,这时因为有5个分区了,所以会使用8个hash bucket。这时Oracle的hash函数就比较牛了,它可以保证2,4,8,16个分区时,同一个键值分布在相同的分区或者是对应可以合并的分区,看下面的SQL:
select ora_hash('hellodba',1)+1 par2,
ora_hash('hellodba',3)+1 par4,
ora_hash('hellodba',7)+1 par8,
ora_hash('hellodba',15)+1 par16
from dual;
PAR2 PAR4 PAR8 PAR16
---------- ---------- ---------- ----------
2 4 4 12再回到我们的项目中,我们为了解决这个问题,采用了更简单的处理方案,直接就做了1024个分区,我们有8个物理数据库,每个数据库中有128个表,以后再分拆时,只要移动这些表,并修改应用中的对应关系就可以了。其实和Oracle合并再拆分的思路是一样的。(链接:http://www.hellodb.net/2010/05/virtual-partition-hash.html)
这个问题其实在大牛lewis的Practical Oracle8i中讲过,当时我并没有仔细想清楚,现在想清楚了,特此记录。有些东西,明白了就觉得它挺简单的,希望对大家有帮助。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









