







写在前面的碎碎念
开始决定写读书笔记的原因是上周二去实地开了一次组会,听师兄们汇报了一下去年的工作,在佩服老师和师兄们水平的同时也感受到了差距。见贤思齐,因此给自己立了个flag:坚持读文献。
另外,在网上做笔记的原因是想给自己一个隐形的激励,毕竟以我这种半途而废的性格可能私底下读个一两篇就放弃了。
俗话说万事开头难,这第一篇文章也是耗了我几个下午才搞懂里面的大多数细节,所以笔记也应该算是比较详细了,之后应该会读几篇snn相关的文章,希望自己保持干劲,坚持下去。
正文
文章为:Z. Yuan et al., “STICKER: An Energy-Efficient Multi-Sparsity Compatible Accelerator for Convolutional Neural Networks in 65-nm CMOS,” in IEEE Journal of Solid-State Circuits, vol. 55, no. 2, pp. 465-477, Feb. 2020, doi: 10.1109/JSSC.2019.2946771.
引言&背景
文章主要介绍了清华的最新的sticker芯片。
第一章引言
首先指出了CNN的权重(weight)矩阵很多情况下是非常稀疏(sparse)的,因此可通过神经网络剪枝(pruning)的方法对网络进行裁剪,降低weight的参数数目,使得网络在CPU/GPU上得到加速。
但是这种剪枝方法在权重矩阵不规则的情况下,加速效果非常有限,因此很多人提出用专用集成电路(ASIC)的方法来做加速。然而,此前的各种ASIC芯片往往只针对一类特定的网络,泛用性比较差,而这篇文章提出的sticker芯片可以在各种网络稀疏模式下都得到较好的加速效果:

如图,作者根据输入的激活值(activation) 以及 权重(weight)矩阵的稀疏程度划分了9种工作模式,其中,activation与weight各有三种状态:稀疏(S,Sparsity),中等(M,Medium),以及稠密(D,Dense),这些状态两两组合构成了9种工作模式:SD,MD,DD,SM,MM,DM,SS,MS,DS。
上图可以看到不同的ASIC芯片在不同工作模式下的性能对比,sticker在各种模式下都有较好的效果。
Sticker是基于以下三点来取得如此均衡的性能的:
(1)通过online sparsity adaptor检测激活值activation的稀疏程度,并因此改变芯片的工作模式。(注意只在线监测avtivation的稀疏度,这是由于weight的稀疏程度可以轻松的离线得到,而activation的值无法预知,在文章后面也有提到这点)
(2)根据不同的稀疏模式可以重配置memory的工作模式。
(3)带有冲突(collision)避免机制的脉动阵列(PE)。
整体架构
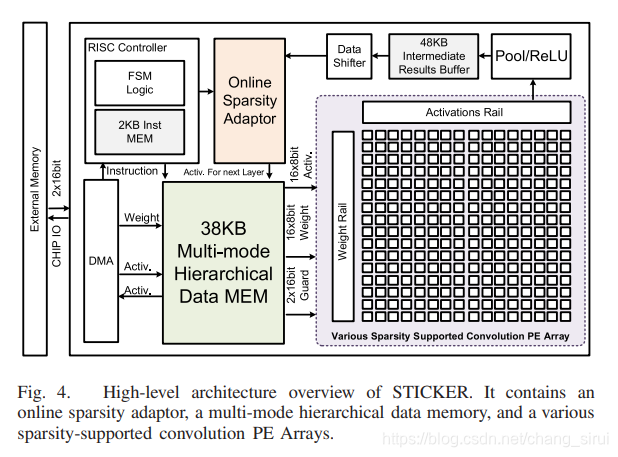
如图,片内的多工作模式片内memory(绿色部分)可以通过DMA方式直接与片外memory通信,紧接着,片内的PE阵列(紫色)从片内memroy读取weight、activation等数据送入PE阵列进行卷积,卷积的结果送入pool/Relu模块进行池化/激活,产生输出激活值,输出激活值通过buffer缓存后送入上面提到的sparsity adaptor中,判断工作模式,再写回片内memory。
上述所有过程由一个RISC Controller控制(左上角)。
下面逐个介绍上述几个模块。
芯片模式切换及Adaptor
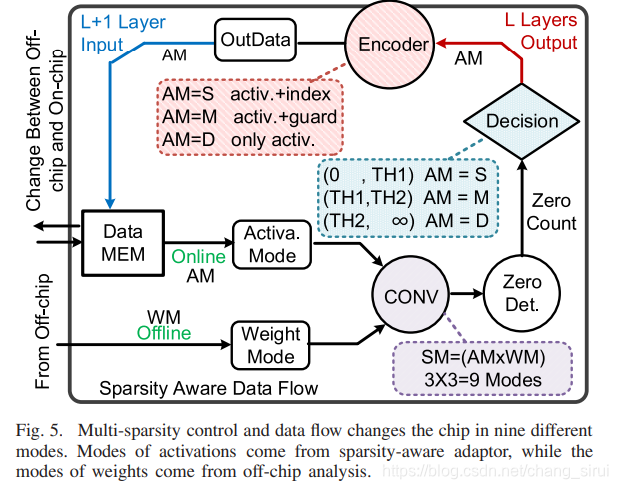
上图是整个Chip的data flow示意图,从上图中可以了解芯片是如何切换工作模式的。
Activation的值从Data Mem中读取,并与从片外存储读取的weight做卷积(PE阵列中完成),产生前文所述的9种模式下的卷积。卷积将会产生新的激活值,该激活值会被送入一个sparsity detector中,作用是计该输出激活值中非0的个数。在这里,用户将定义两个门限值:TH1和TH2(TH1<TH2),如果非0值个数小于TH1,则activation mode (AM)= S (sparse),若非0值个数在TH1与TH2之间,则为Medium,否则为Dense。在判断完成后,输出激活值将根据不同的模式(S,M,D)进行不同方式,通过encoder进行编码,从而进行数据压缩。
编码规则如下:
(1)若输出激活值稀疏,则以activation+索引index的形式存储,0值不存。
(2)若输出激活值稀疏程度中等,则存储activation+guard(guard不知道怎么翻译比较好,这个gurad的作用文章后面有提到,是来控制PE单元的开启从而节省功耗)。
(3)若输出激活值稠密,则以正常形式存储。
顺便一提,为什么要采用三种不同的存储编码方式呢?文中其实也有提到。
此前的一些研究往往只采用(1)这一种数据格式,这样做的一大缺点就是当矩阵稠密时,索引index将会占用大量的存储空间(达到数据量的40%左右)。
文中的这种编码方式可以在不同的工作状态下都取得较好的压缩效果
下面这幅图片就是整个adaptor的架构,包含了上面所述的sparsity detector, encoder,以及一个buffer和一个controller。
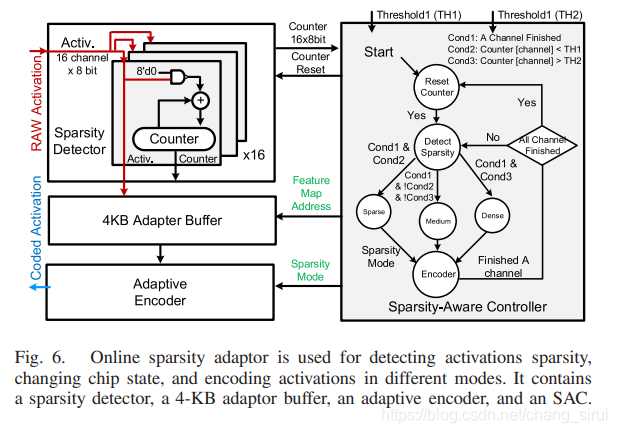
Detector和encoder的作用上面介绍过,就是计非0个数和进行不同模式的编码,Adapter buffer的作用是暂存计数的结果。SAC的作用是对上面的整个过程进行控制(控制过程与上一段的过程类似,不再赘述)。
这一段中由两点需要注意
1.并不是所有数据都要用压缩格式存储。如,卷积结果就是以一般的数据格式存储,这是由于output feature map的稀疏性主要是由激活函数Relu带来的,由于卷积结果还没有通过relu进行激活,所以这个矩阵通常不具有稀疏性,因此以一般格式存储。weight、input和output feature map(即activation)以压缩形式存储。
2.模式的控制与切换不必消耗额外的时钟周期,因为卷积运算通常耗时较长,这些操作都在卷积运算的同时就完成了。
指令集(instruction set)
sticker的指令分为两种,分别是静态指令和动态指令。
静态指令:当控制信号变化不频繁时,使用静态指令,静态指令可被动态指令调用;
动态指令:当控制信号变化频繁时,使用动态指令。
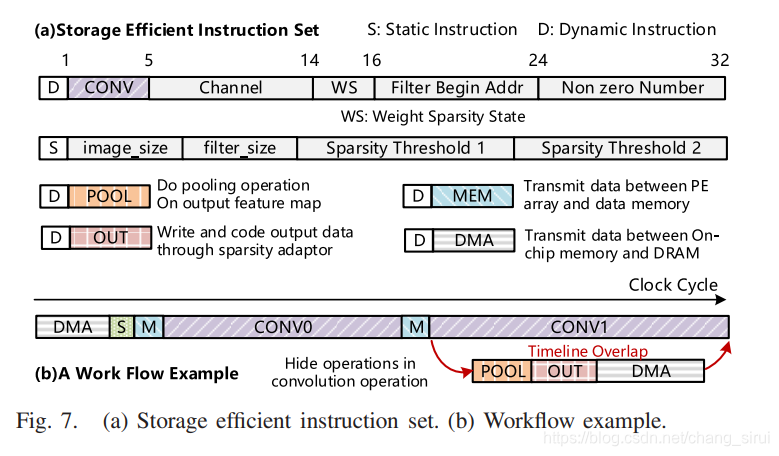
上图(a)就是几种指令的示意。(b)中描述了流水线操作,在conv1卷积时,conv0进行池化等操作。
适应多模式下工作的memory
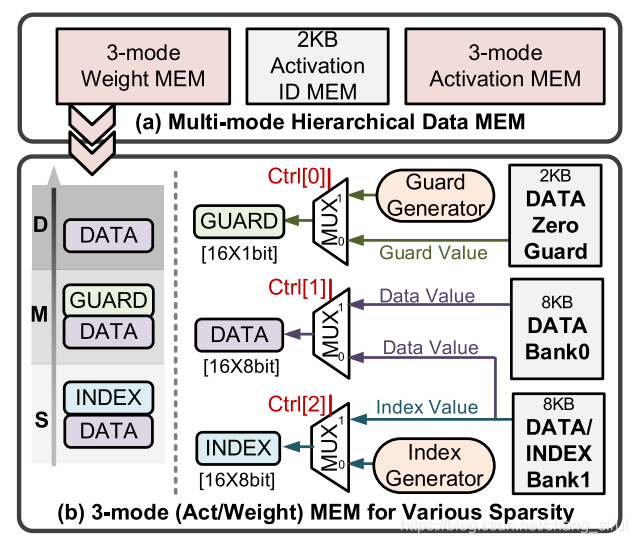
上图就是整个memory的示意图,不得不说设计的非常巧妙。在存储前,整个feature map会被分割为许多小的blocks(小于16x16),这是由于index只有八个bit。
整个memory主要由三个模块构成:
2KB Activation ID MEM:存储block ID,首地址,以及非0元素的个数。
3-mode Weight MEM与3-mode Activation MEM,这两者结构相同,用于存储不同格式的weight与activation。
weight/activ MEM的结构如上图所示,包含三个不同的bank: Data Zero Guard Bank (DGB), Data Bank 0(DB0),与Data/Index Bank(DB1),其中,DGB用于存储Guard,DB0只用来存储数据,DB1可用于存储数据或者index。存储方式根据block的类型不同而改变,block分为四种,除了前面介绍的S,M,D三种外还有一种empty block,即全空block。
empty block:直接丢弃(discard);
Sparse block(前面提到,稀疏矩阵存储为data+index):非零元素存进DB0,index存进DB1;
Medium block(medium元素存储为data+guard):非零元素存进DB0,DB1, guard存进DGB;
Dense block(一般格式,只有data):存DB0和DB1。
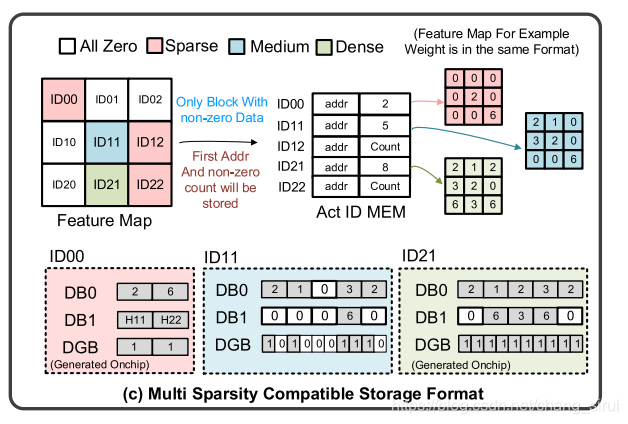
这幅图表示的就是以上四种block下DB与ID MEM的存储状态,其中,ID00为sparse,ID11为medium,ID21为Dense。文中提到,guard可以控制PE的开启,从而节约能量,guard= 0时PE开启,guard=1时PE关闭,以图中蓝色部分的ID11为例,DB0中存储的数据为(2,1,0,3,2),其对应的guard应为(1,1,0,1,1)。dense模式下,guard全部置1,而sparse模式下,DGB全部置1(shut down),但不表示guard全为1,此时guard由前面(b)图中的guard generator产生。当工作在dense或者medium模式下,index会由index generator产生(这个是在下一章提到的,第一次读的时候找了半天也没找到这个index generator是干嘛的。。)
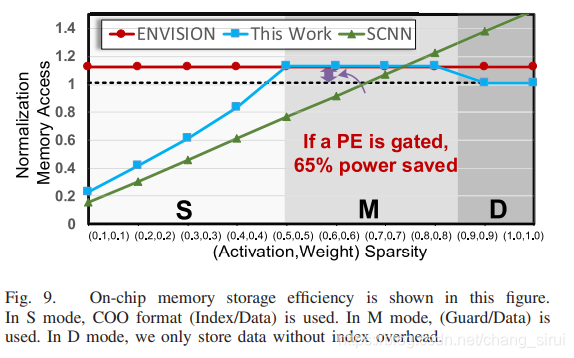
这张图是ENVISION和SCNN的访存性能对比,ENVISION采用非压缩格式存储,所以再各种模式下访存性能都一致(都很高),而SCNN采用的是data+index的存储方式,在Dense模式下表现很差(由于index占用了大量空间)。而sticker可以在各种情况下都取得较好的性能。
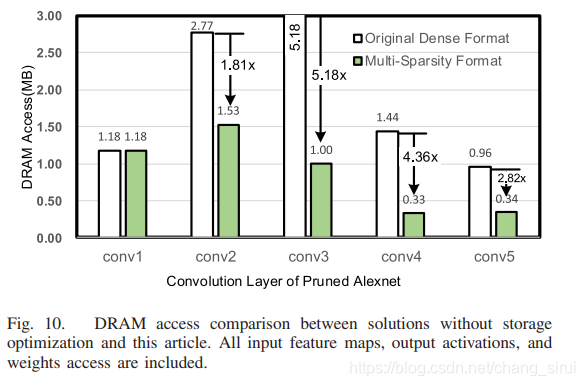
这张图是在alexnet上的对比。注意网络的第一层通常比较dense,无法有效剪枝,所以性能没有明显改善。
脉动阵列(PE)
这里我个人感觉是正片文章里最难懂的一块,主要是要对PE阵列要有比较清晰的了解(其实我对这篇文章里PE的工作过程还是似懂非懂,欢迎大佬交流)。有关PE阵列的相关知识可以参考另外一位博主的这篇博文:脉动阵列在二维矩阵乘法及卷积运算中的应用.
和这篇综述文章: Efficient Processing of Deep Neural Networks: A Tutorial and Survey
简单来说,PE分为权重固定(weight stationary, WS),output固定,无本地重用等多种工作模式,sticker中用到的是第一种:权重固定式(固定权重在PE中,广播Act,流动部分和psum)。
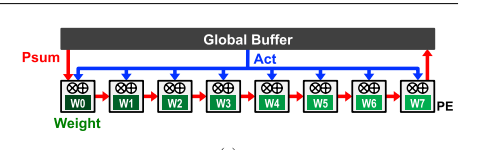
整个PE的工作过程如下图:
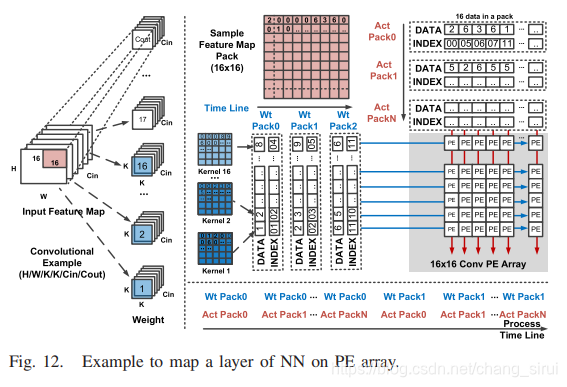
神经网络的各个层会逐层送入PE中进行处理,input feature map会被分割成许多小于16x16的blocks(上文中也提到了),与16个weight kernal做卷积。在PE中,以(Wt pack0/Act Pack0),(Wt pack0/Act pack1)……的顺序进行处理。
这里会遇到一个问题,就是在weight和activation都为sparse类型的时候,输出的location是未知的,此前的一些研究用哈希(hash)方法来解决这个问题,但是代价是两倍的存储空间(如下图)。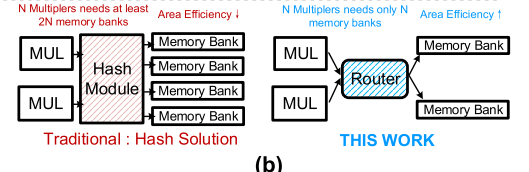
而本文用一个router将两个PE单元连接成一个Set来解决这个问题,没有产生额外的存储开销。
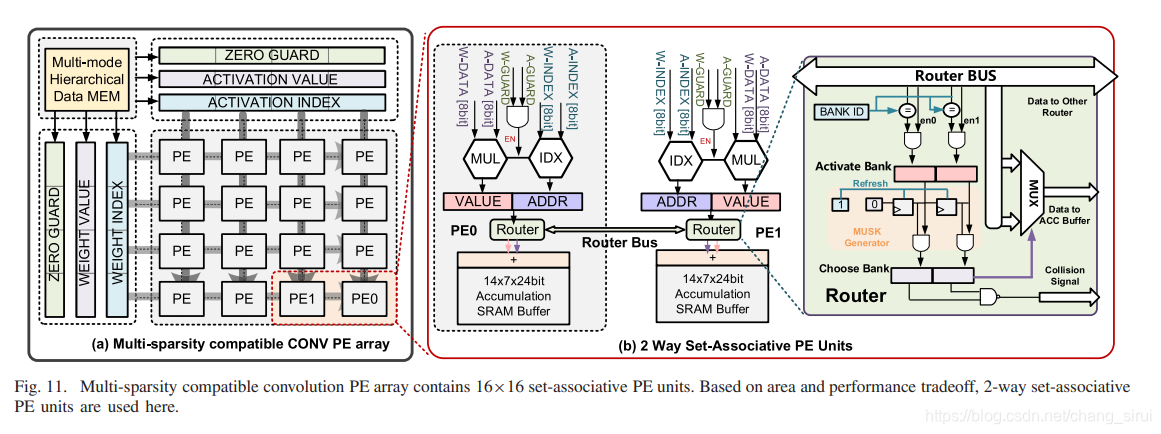
如图,一个set中的两个PE通过总线共享buffer中的数据,每个PE有一个MUL(得到相乘结果),IDX(根据index计算输出地址),ACC buffer(暂存输出数据)由于每个PE set由两个buffer,因此每个buffer存储一半的输出结果。PE阵列中还有前文提到的guard使能模块,用于控制PE的开启。
上面提到,如果act与weight都sparse的话,输出location会未知,也就是说会产生collision,此时就会由router来解决冲突(至于router的原理文章好像并没有细说)。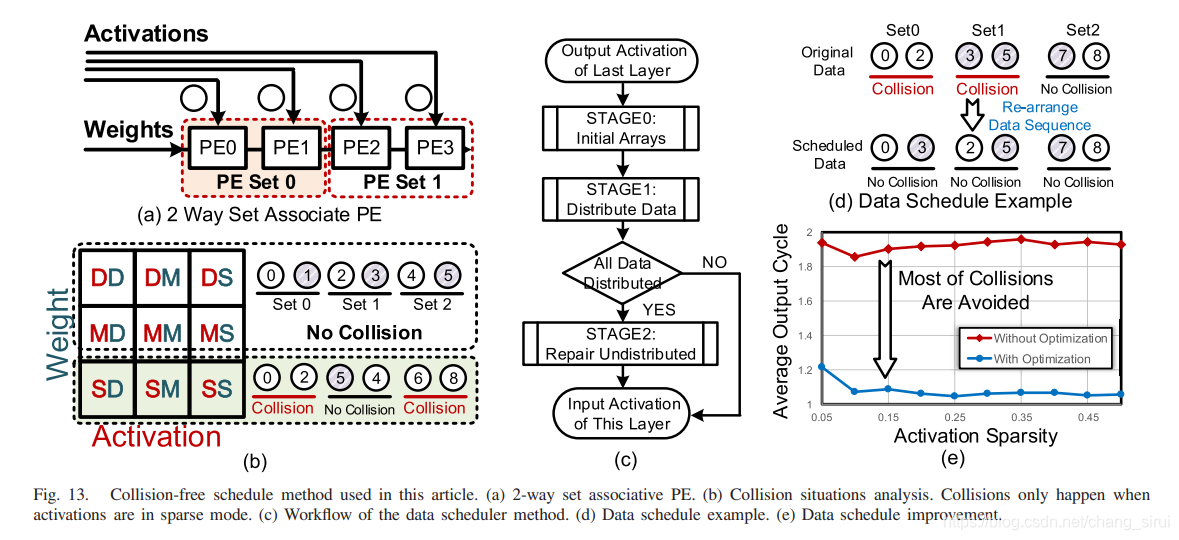
冲突产生的原理如图所示,数据的列index只取决于它的activation index,在dense或者medium模式下,activation的列的奇偶排序是有序的,因此输出的奇偶也是有序的,但activation在sparse模式下,输出将会是无序的,这就会产生冲突,如上图(b)所示。在冲突发生时,router将会消耗两个时钟周期,使得结果正确地写入buffer中。
同时,一大部分冲突可以在软件层面解决。可以通过CPU,在软件层面重排输出序列,使其能够正确写入,如图中(d)所示,(e)显示,在软件层面可以解决大部分的冲突。
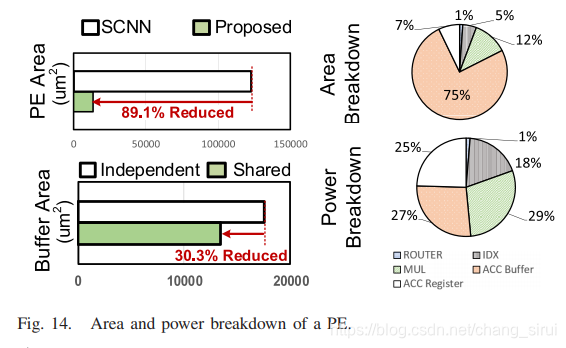
与SCNN在area和power上的对比,由于SCNN采用hash,面积开销很大,由于buffer是共享的,因此也节约了能耗。
性能&结论
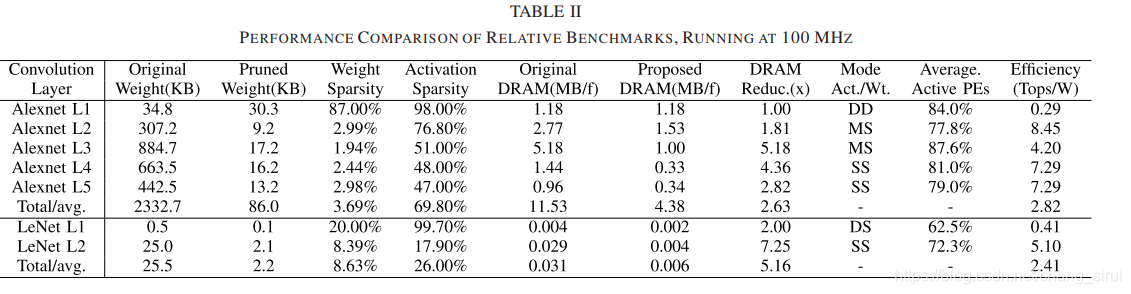
芯片在Alexnet和Lenet-5上的性能。在Alexnet上,性能瓶颈主要体现在第一层,这是由于第一层的网络通常不能被很好的压缩。对于Lenet,由于第一层的input较少,芯片的性能也不能被完全发挥。
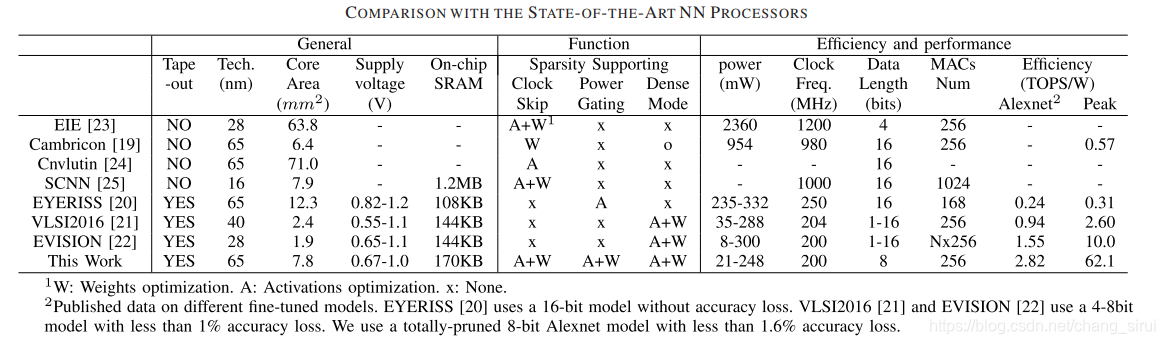
与其他芯片的对比。可以看到在alexnet上效率达到了2.82TOPS/W,远高于其他芯片。
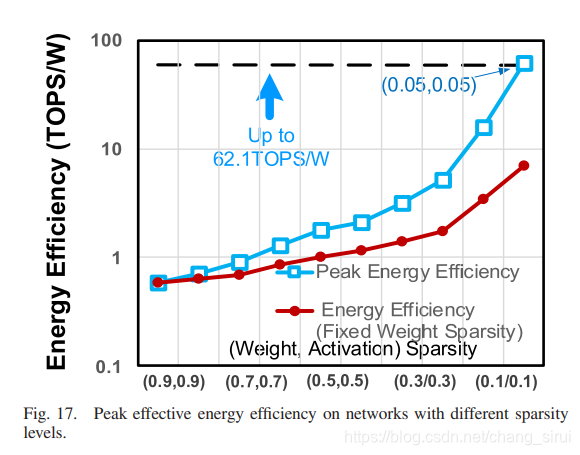
不同稀疏程度下的能效,最高峰值达到62.1TOPS/W。

















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









