







原文地址:http://blog.csdn.net/misterliwei/article/details/976988
一.前言
Windows中有很多像进程对象、线程对象、文件对象等等这样的对象,我们称之为Windows内核对象。内核对象是系统地址空间中的一个内存块,由系统创建并维护。内核对象为内核所拥有,而不为进程所拥有,所以不同进程可以访问同一个内核对象。
二.内核对象结构
每个对象都有对象头和对象体组成。所有类型的对象头结构都是相同的,而结构体部分却各不相同的。下面是内核对象的结构图:
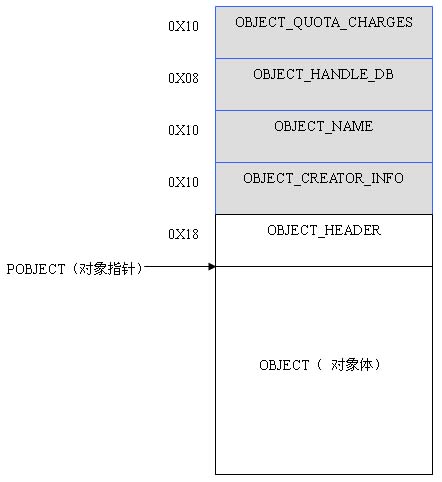
内核对象结构图
图中灰色部分是可能出现的。每个对象中是否存在这些部分主要由OBJECT_HEADER结构中的相关标志来指定。上面的5个结构的格式是固定的;而OBJECT结构体部分却是各个对象各不同的。需要注意的是:指向对象的指针POBJECT是指向对象体部分,而不是指向对象头的。所以,若需要访问OBJECT_HEADER,需要将POBJCECT减去0x18而获得。
下面是OBJECT_HEADER的结构
|
typedef struct _OBJECT_HEADER
|
三.目录对象
WINDOWS中有20几类无数的内核对象,它们都独立地存在于系统地址空间中。系统利用目录对象将所有的这些对象组织起来。目录对象是一个有37个数组元素组成的哈希(HASH)树。数据结构如下:
|
Typedef struct _OBJECT_DIRECTORY_ENTY { Struct _OBJECT_DIRECTORY_ENTRY *NextEntry; POBJECT Object }OBJECT_DIRECTORY_ENTRY, *POBJECT_DIRECTORY_ENTRY,**PPOBJECT_DIRECTORY_ENTRY;
Typedef struct _OBJECT_DIRECTORY { POBJECT_DIRECTORY_ENTRY HashTable[37]; POBJECT_DIRECTORY_ENTRY CurrentEntry; BOOLEAN CurrentEntryValid; BYTE Reserved1; WORD Reserved2; DWORD Reserved3; }OBJECT_DIRECTORY, *POBJECT_DIRECTORY; |
系统将对象名称进行一定的算法得出一个HASH值,算法如下:
| //根据名字计算HASH值。 hash = 0; p = (PSHORT)wStr; //存放名称的一个WCHAR数组 while(*p) { Symb = (CHAR)*p; hash = hash * 3 + (hash >> 1);
if (Symb < 'a') //<a hash= hash + Symb; else if (Symb <= 'z') //即 a~z hash = hash + Symb - 0x20; else // > z hash = hash + (CHAR)RtlUpcaseUnicodeChar((WCHAR)*p);
p ++; } hash = hash % 37; //最终的hash值。 |
系统将所有相同HASH值的对象链接到响应的数组项中,于是系统中所有元素将排列成如下的结构图:
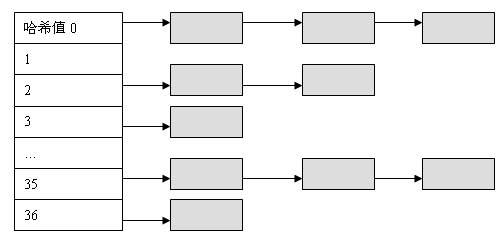
系统根目录的对象的指针由ObpRootDirectoryObject来指定。
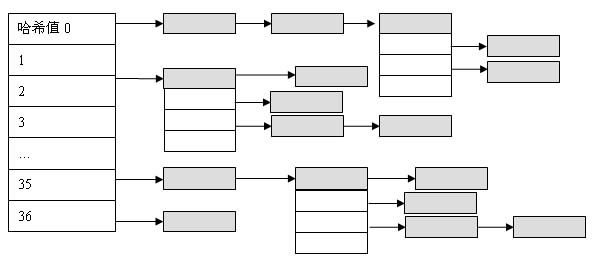
按理说,系统中只需要一个目录对象就够了,系统中所有的内核对象都将链接在这个目录对象上。但是不知什么原因,系统中并不是这样,系统中存在着多个目录对象,它们以根目录对象为根,组成一个“对象树”。每个目录对象中的哈希树的hash值的计算规则都是一样的。
我们可以根据系统中“对象树”的结构来遍历系统中所有的对象。
四.类型对象
内核对象中还有一种比较特殊的对象——类型对象。系统中每种类型对象只有一个类型对象,也就是说,系统中最多只有20几个类型对象。每种类型的对象都在其对象体中存在一个指向其类型对象的指针,因为一种类型对象只有一个实体,所以每种类型对象的指针都是固定的,这样我们就可以通过对象体中的类型对象指针来判断和访问对象的类型了。
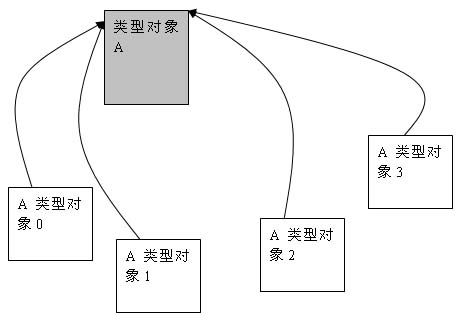
各个类型对象的对象体内并没有链表结构使得它们相互链接起来。但是假如对象头部前面有OBJECT_CREATOR_INFO结构(见下表),则相同类型的对象就可以通过它的成员ObjectList相互链接起来了。但是,不幸的是:缺省情况下,只有Port和WaitPort两中类型的对象有这种结构。所以一般情况下,我们是不能通过类型对象来遍历这个系统中所有对象的。
|
typedef struct _OBJECT_CREATOR_INFO { LIST_ENTRY ObjectList; // OBJECT_CREATOR_INFO HANDLE UniqueProcessId; WORD Reserved1; WORD Reserved2; }OBJECT_CREATOR_INFO, *POBJECT_CREATOR_INFO, **PPOBJECT_CREATOR_INFO;
|
五.对象的遍历
上面分析过了,下面可以目录对象的遍历,来进行系统中所有对象的遍历。
| //写一个递归函数。用来分析树型目录。 void AnalyseDirectory(POBJECT_DIRECTORY pDirectory, ULONG DirectoryType, int Level) { POBJECT_DIRECTORY_ENTRY pDirectoryEntry; POBJECT_HEADER pObjectHeader; POBJECT_NAME pObjectName; PWCHAR wStr[200]; char Space[100]; //为生成空格用的。 int i, j;
for(i = 0; i < 36; i ++) //DIR对象的对象体(BODY)是37个元素的数组。 { pDirectoryEntry = pDirectory->HashTable[i];
while(pDirectoryEntry) { pObjectHeader = (POBJECT_HEADER)((ULONG)pDirectoryEntry->pObject - sizeof(OBJECT_HEADER));
//生成空格 RtlZeroMemory(Space, 100); for(j = 0; j < 5 * Level; j ++) Space[j] = ' ';
if (pObjectHeader->NameOffset) { pObjectName = (POBJECT_NAME)((ULONG)pObjectHeader - pObjectHeader->NameOffset); RtlZeroMemory(wStr, 200 * sizeof(WCHAR)); RtlCopyMemory(wStr, pObjectName->Name.Buffer, pObjectName->Name.Length);
DbgPrint("%s pObject: 0x%08X Name: %S", Space, pDirectoryEntry->pObject, wStr); } else DbgPrint("%s pObject: 0x%08X Name: noname", Space, pDirectoryEntry->pObject);
//pObject对象是属性对象吗 if ((ULONG)pObjectHeader->pObjectType == DirectoryType) AnalyseDirectory(pDirectoryEntry->pObject, DirectoryType, Level + 1);
pDirectoryEntry = pDirectoryEntry->NextEntry; } }//end of 遍历37个记录 } |
六.对象的访问
内核中知道了内核对象的地址就可以直接访问这个内核对象了,但是在用户程序中却不能这样访问。Windows为内核对象的访问提供了一系列的函数。当调用一个用于创建内核对象的函数时,函数调用完便返回一个句柄值。句柄值是进程独立的,一个进程中的句柄值在另一个进程中是无效的。
句柄值是一个进程句柄表的索引。每个进程都有一个进程句柄表,而所有进程的句柄表串成一个句柄表链。这个链的头部地址保存在内核变量HandleTableListHead中。
下面具体看一下句柄表结构。系统将句柄表组织成和线性地址解析一样的结构。句柄表是个三层的表结构,而句柄值也被分成三部分,用来分别索引这三个部分。下面是句柄解析图:
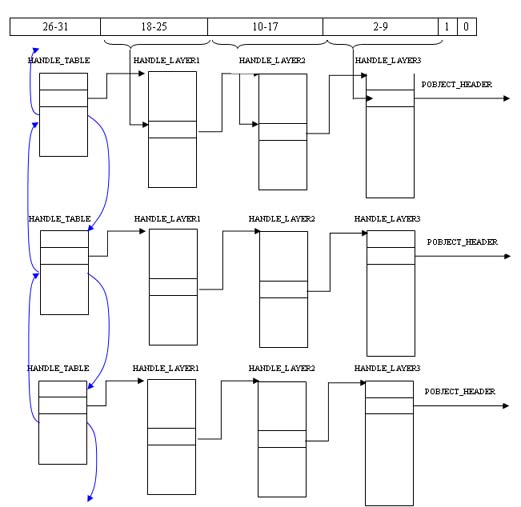
七.总结
本文可以说是一个读书笔记。在参考了很多文章的基础上,然后作一些试验才完成本文的。内核对象是Windows内部的重要数据结构。通过本文可以大致了解Windows是如何组织众多的对象的。
八.参考
1.《Undocumented Windows 2000 Secrets》
2.Anathema《Inside Windows Nt Object Manager》
3.webcrazy《剖析Windows NT/2000内核对象组织》
4.《Inside Windows 2000》
5.《Windows核心编程》
注意:本节描述的句柄是再WIN2K下的句柄.WINXP下句柄表结构已经完全不同.















 1336
1336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









