







 本文详细介绍了YOLOv5的网络模型,包括四种不同规模的版本(YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x)。在输入端,YOLOv5采用了Mosaic数据增强、自适应锚框计算和自适应图片缩放。Backbone部分引入了Focus结构和CSP结构,Neck部分增加了PAN结构。输出端使用GIoU损失函数和加权NMS。此外,通过depth_multiple和width_multiple参数调整网络深度和宽度,以实现不同性能和速度的平衡。
本文详细介绍了YOLOv5的网络模型,包括四种不同规模的版本(YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x)。在输入端,YOLOv5采用了Mosaic数据增强、自适应锚框计算和自适应图片缩放。Backbone部分引入了Focus结构和CSP结构,Neck部分增加了PAN结构。输出端使用GIoU损失函数和加权NMS。此外,通过depth_multiple和width_multiple参数调整网络深度和宽度,以实现不同性能和速度的平衡。
文章参考自江大白知乎文章,作为yoloV5的学习记录笔记。
知乎链接:https://zhuanlan.zhihu.com/p/172121380
目录
一、Yolov5四种网络模型
Yolov5一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。下面给出网络结构图这样更加直观。

Yolov5与Yolov3的一些主要的不同点:
(1)输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构
(4)Prediction:GIOU_Loss
Yolov5的算法性能测试图:

上图可以看出,Yolov5s网络最小,速度最少,AP精度也最低。但如果检测的以大目标为主,追求速度,倒也是个不错的选择。其他的三种网络,在此基础上,不断加深加宽网络,AP精度也不断提升,但速度的消耗也在不断增加。
二、yolo_v5改进点详解
1 输入端改进
1)Mosaic数据增强
Yolov5的输入端采用了和Yolov4一样的Mosaic数据增强的方式。Mosaic数据增强提出的作者也是来自Yolov5团队的成员,不过,随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果还是很不错的。

2) 自适应锚框计算
在网络训练中,先设定一个初始的先验框。网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。Yolov5在Coco数据集上初始设定的锚框:

在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。但Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。当然,如果觉得计算的锚框效果不是很好,也可以在代码中将自动计算锚框功能关闭。

控制的代码即train.py中上面一行代码,设置成False,每次训练时,不会自动计算。
3)自适应图片缩放
目标检测算法常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。例如Yolo算法中常用416*416,608*608等尺寸。对下面800*600的图像直接缩放到416*416。

作者认为,在项目实际使用时,很多图片的长宽比不同,因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。因此在Yolov5的代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。
操作步骤:
第一步:计算宽高的缩放比例
原始缩放尺寸是416*416,都除以原始图像的尺寸后,可以得到0.52,和0.69两个缩放系数,选择小的缩放系数。

第二步:计算缩放后的尺寸(以长边为基准)
原始图片的长宽都乘以最小的缩放系数0.52,宽变成了416,而高变成了312。

第三步:☆计算黑边填充数值(这里是重点)

将416-312=104,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式(32是网络下采样的步长),得到8个像素,再除以2,即得到图片高度两端需要填充的数值。
此外,需要注意的是:
- a. 这里大白填充的是黑色,即(0,0,0),而Yolov5中填充的是灰色,即(114,114,114),都是一样的效果。
- b. 训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
- c. 为什么np.mod函数的后面用32?因为Yolov5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,再进行取余。
- 个人见解:一张800*600的图片,如果训练和测试使用的填充方式不一样,感觉会导致物体的形变不一致,对检测的效果是有影响的。理论上训练和测试的填充方式应该一致,但是作者应该是考虑到训练时一个batch内的尺寸必须一致,所有训练时没有采用这种填充方式。
2 Backbone的改进点
1)Focus结构
Focus结构,在Yolov3&Yolov4中并没有这个结构,其中比较关键是切片操作。比如右图的切片示意图,4*4*3的图像切片后变成2*2*12的特征图。注意:切片不是像切蛋糕那样直接十字切成四份,是通过采样的方式,在四个区域分别采样。
以Yolov5s的结构为例,原始608*608*3的图像输入Focus结构,采用切片操作,先变成304*304*12的特征图,再经过一次32个卷积核的卷积操作,最终变成304*304*32的特征图。
需要注意的是:Yolov5s的Focus结构最后使用了32个卷积核,而其他三种结构,使用的数量有所增加,先注意下,后面会讲解到四种结构的不同点。

2)CSP结构
Yolov5中设计了两种CSP结构,以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
CSPNet全称是Cross Stage Paritial Network(跨阶段的平行网络),主要从网络结构设计的角度解决推理中从计算量很大的问题。CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。


注意!!!更新于2024.12.24。
yolov5网络的结构持续在升级,上面的CSP模块是早期版本的,最新的CSP(改称C3)模块略微有些区别。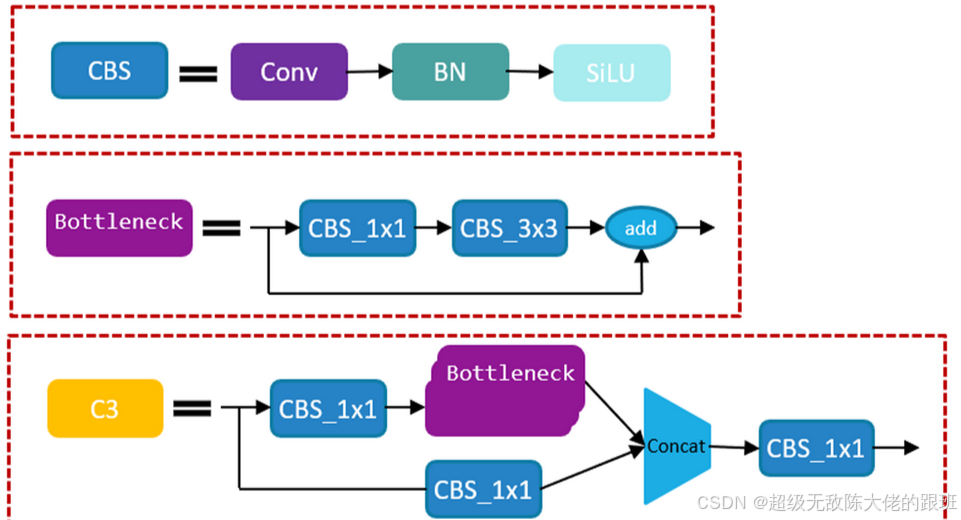
3 Neck部分的改进点
1)FPN处增加PAN结构

Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。

4 输出端改进点
1)Bounding box损失函数:GIoU
Yolov5中采用其中的GIOU_Loss做Bounding box的损失函数。而Yolov4中采用CIOU_Loss作为目标Bounding box的损失。

2)nms非极大值抑制
Yolov5中采用加权nms的方式。参看yolov4的nms部分。
三、Yolov5四种网络结构的不同点
Yolov5代码中的四种网络,和之前的Yolov3,Yolov4中的cfg文件不同,都是以yaml的形式来呈现。而且四个文件的内容基本上都是一样的,只有最上方的depth_multiple和width_multiple两个参数不同。

四种结构就是通过上面的两个参数,来进行控制网络的深度和宽度。其中depth_multiple控制网络的深度,width_multiple控制网络的宽度。
深度和宽度简单解释:
- 深度depth_multiple:指的是CSP结构中残差块的数量,残差块的数量越多,网络就越深。
- 宽度width_multiple:指的是卷积核的维度,卷积核的维度越大,网络越厚,yolov5这是用宽度来表示。
1)depth_multiple控制网络深度

在上图中两种CSP结构,CSP1和CSP2,其中CSP1结构主要应用于Backbone中,CSP2结构主要应用于Neck中。
需要注意的是,四种网络结构中每个CSP结构的深度都是不同的。a.以yolov5s为例,第一个CSP1中,使用了1个残差组件,因此是CSP1_1。而在Yolov5m中,则增加了网络的深度,在第一个CSP1中,使用了2个残差组件,因此是CSP1_2。Yolov5l中使用了3组,Yolov5x中使用了4组。
Yolov5中,网络的不断加深,也在不断增加网络特征提取和特征融合的能力。
2)width_multiple控制网络宽度(厚度)

如上图表格中所示,四种yolov5结构在不同阶段的卷积核的数量都是不一样的,因此也直接影响卷积后特征图的第三维度,即厚度。
a.以Yolov5s结构为例,第一个Focus结构中,最后卷积操作时,卷积核的数量是32个,因此经过Focus结构,特征图的大小变成304*304*32。而yolov5m的Focus结构中的卷积操作使用了48个卷积核,因此Focus结构后的特征图变成304*304*48。yolov5l,yolov5x也是同样的原理。
当然卷积核的数量越多,特征图的厚度,即宽度越宽,网络提取特征的学习能力也越强。


















 8500
8500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









