









1. start() 会调用 run() 方法,为什么我们还选择使用start()方法开启线程
start()方法最总调用的是start0() 的native方法,能够正确的开启一个线程的生命周期。
run()方法只是一个普通方法
2. 一个线程两次调用start()方法会出现什么情况?为什么
- 会抛出异常
原因是当Thread t = new Thread()时 线程的状态为NEW
执行了start()后,线程会检查当前的线程状态,如果为NEW就运行线程,线程状态改为Runnable,当第二次执行start()时发现线程的状态不为NEW 就会抛出异常
3. 有多少种实现线程的方法?
- 摆明立场
从不同的角度看,会有不同的答案
我认为本质上都是实现Runnable 和继承Thread - 举出例子
线程池的Worker 本质上是一个线程安全的Runnable
线程池的核心线程 是使用Thread.start() 开启的
支持返回值的 FutureTask 是使用Future接口拓展的一个Runnable
定时任务 TimerTask 也是一个Runnable
4. 如何停止线程
-
用
interrupt来请求
interrupt 并不是强制响应方立即响应,它能参与响应方的业务逻辑,不会打断响应方原本的业务逻辑,保证数据安全 -
使用interrupt 需要合作进行 -> 使用api或者响应异常
2.1 普通场景
Thread.interrupt+Thread.currentThread().isInterrupted()public static void main(String[] args) { Runnable runnable = new Runnable() { @Override public void run() { int i = 0; while (!Thread.currentThread().isInterrupted() && i < Integer.MAX_VALUE / 2) { if (i % 10000 == 0) { System.out.println(i); } i++; } } }; Thread thread = new Thread(runnable); thread.start(); try { Thread.sleep(2000); // zhege sleep 只是让线程运行到循环中 } catch (InterruptedException e) { e.printStackTrace(); } thread.interrupt(); }2.2 带有sleep()的情况
捕获异常try { int i = 0; while (!Thread.currentThread().isInterrupted() && i <= 300) { if (i % 100 == 0) { System.out.println(i); } i++; } Thread.sleep(1000); // sleep在循环外面 } catch (InterruptedException e) { e.printStackTrace(); }2.3 每次循环都sleep()
注意中断标记位会抛出异常后自动清除,注意try catch的处理范围try { int i = 0; while (!Thread.currentThread().isInterrupted() && i <= 300) { if (i % 100 == 0) { System.out.println(i); } i++; Thread.sleep(1000); // sleep在循环内部 /* 如果try-catch放在内部,只会响应一次中断,下次循环会重置中断标记位 ,如果要使用try-catch,并让程序响应中断并退出循环,需要把用一个大try 包住循环。 */ } } catch (InterruptedException e) { e.printStackTrace(); }2.4 多层调用中的中断的最佳实践
- 优先选择抛出中断异常, 强制在run 方法中处理
- volite 无法处理长时间阻塞的情况,容易掉进坑
- 无法传递中断的时候,防止中断被复位,再设置一次中断
catch中再次中断 +isInterrupted()
@Override public void run() { while (true) { if (Thread.currentThread().isInterrupted()) { System.out.println("内层方法已经被中断,外层方法同样需要中断,跳出循环"); break; } System.out.println("go"); reInterrupt(); } } /** * 在子线程中的sleep()被中断后,再手动把中断标志位置为true * */ private void reInterrupt() { try { Thread.sleep(2000); } catch (InterruptedException e) { System.out.println("打印日志"); Thread.currentThread().interrupt(); e.printStackTrace(); } }- 其他能被中断的阻塞

5. 如何处理不可中断的阻塞
很遗憾,没有一个通用的解决方案,
但是可以举出两个场景的例子:
ReentrantLock.lockInterruptibly()可以响应中断- 继承
Thread 重写interrupt()
处理IO读写的中断
6. 线程的六种状态
- 状态的扭转
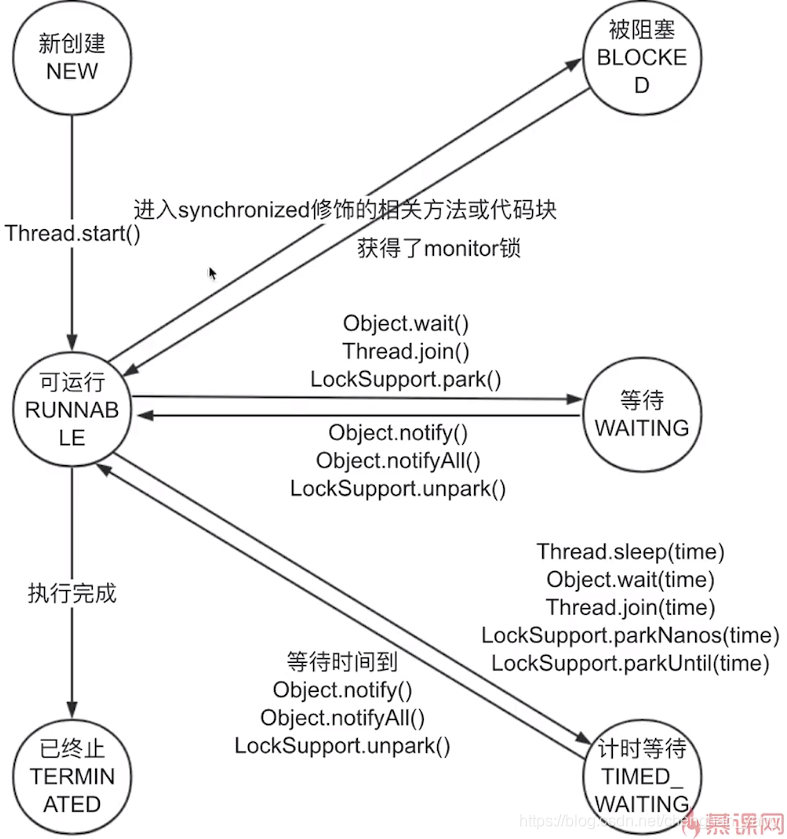
- 特殊情况

7. 手写生产者消费者
8. 用程序实现交替打印0~100的数
9. 为什么 wait() 需要在同步代码块中,而sleep不需要
- 代码规范的角度:
wait()方法 和notify()需要配合使用,引入同步代码块让 notify() 严格得在 wait() 后执行。
多线程需要这样强制的规范 - wait() 的实现是锁级别的操作
wait()会释放调用者的锁,不显式指定则为this.wait(),
每个对象都维护了一个monitor用来保存锁信息
所以在同步代码块用lock.wait()让所有锁对象都能使用wait(),让代码能使用多个锁调度wait()方法final static Object lock = new Object(); sychronized(lock){ lock.wait() } - 可以用Thread.wait()吗?
不要使用,会造成隐患,Thread在设计的时候就完成了一个实现,线程执行完毕,自动执行Thread.notify(),
线程的执行时间是不可控的,隐式的Thread.notifyj()会造成预期外的结果
10. notify() 和 notifyAll() 的区别
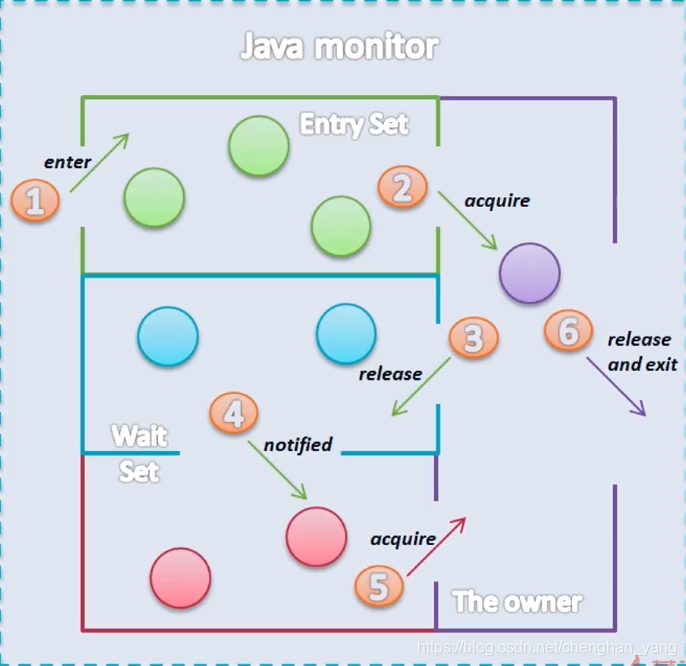
11. join期间,线程处于哪种状态
thread.join() 的等价代码:
synchronized (thread) {
thread.wait(); //
}
由于thread设计的时候实现了,线程一旦完成,执行thead.notifyAll()。
thread.join()也就隐式的实现了主线程等待thread完成后再运行的逻辑
主线程调用thread.join() thread 是 running 状态 main 是 waiting 状态
12. 守护线程和用户线程的区别
守护线程是服务于用户线程的,JVM检测到没有用户线程时就结束程序运行了。
即使存在守护线程,而不存在用户线程,JVM会认为守护线程没有存在的必要
13. 主线程中如何捕获子线程抛出的异常
- 实现
Thread.UncaughtExceptionHandler生成自己的异常捕获器
@Slf4j
public class MyUnCaughtExceptionHandler implements Thread.UncaughtExceptionHandler {
@Override
public void uncaughtException(Thread t, Throwable e) {
log.info("Thread : {}, thrown a Exception : {} ", t.getName(), e.getMessage());
}
}
-
将自己的异常捕获器注册到主线程
Thread.setDefaultUncaughtExceptionHandler(new MyUnCaughtExceptionHandler()); -
补充知识:
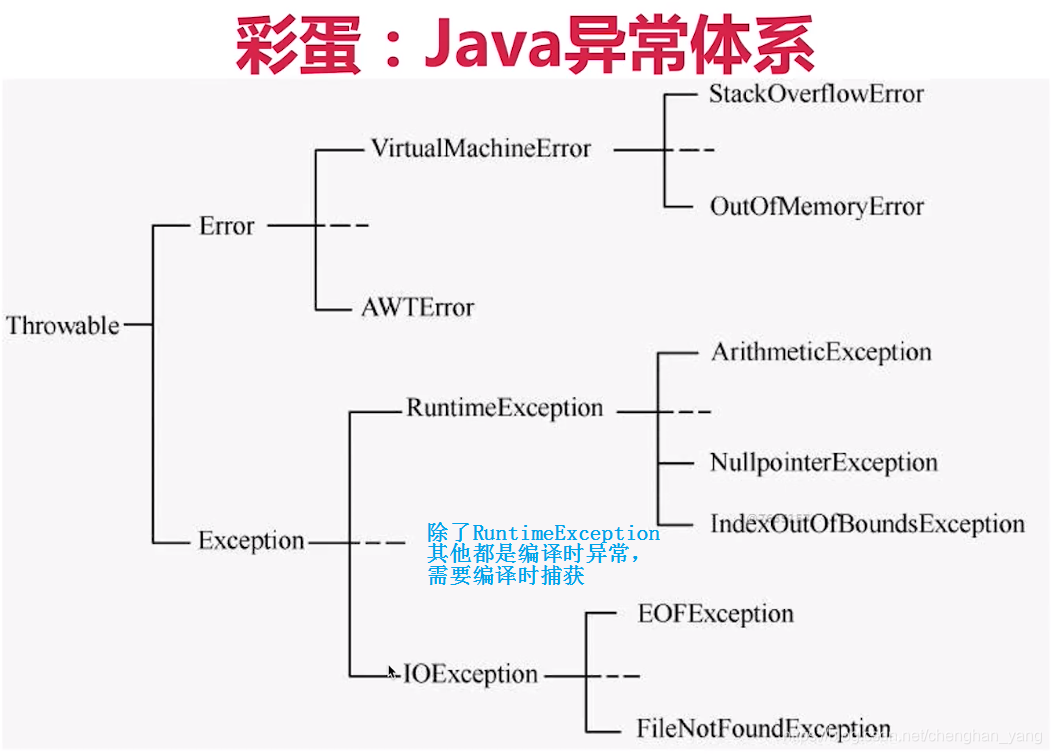
14. 多线程的劣势
线程的调度
- 上下文切换 -> 锁竞争、大量IO操作
什么是上下文切换? 上下文是操作系统的一些寄存器相关的操作,
一次上下文切换主要有以下活动:- 挂起一个线程
- 把一个线程的状态存在内存的某处 ,存储的信息有
- 线程执行到哪个指令,指令的位置在哪
- 程序计数器
- 缓存开销
CPU 和 内存之间有多级缓存来协调速度差,也常使用缓存提高应用程序的执行效率,如for循环
频繁的上下文切换会导致缓存失效
线程的协作
- 内存同步
volatile 禁止指令重排,让优化失效
每个线程可能不再维护自己的缓存,而去同步主内存,造成访问的开销














 70
70











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









