






一个Buffer是固定数量数据的容器,数据可以存入该对象并用于后期检索,NIO针对非boolean类型的所有原始类型都有一个缓存类对应。下面给出buffer类的层次结构图(由于工具原因,没画UML图):
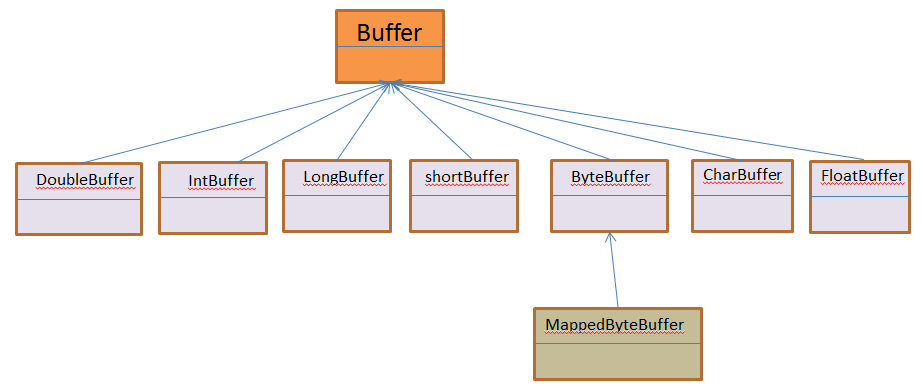
1.缓存区基础
Buffer类包含了一个基本数据类型的数组,除此之外还包含以下四个属性:
容量(capacity): 缓存区能容纳数据元素的最大数,在缓存区创建时指定,后面不能修改。
上界(limit): 缓存区第一个不能被读或写的元素位置。
位置(position): 下一个要被读或写的元素位置。
标记(mark): 一个备忘位置,调用mark()来设置mark = position,调用reset()是指position = mark,标记在为调用mark之前为undefined。
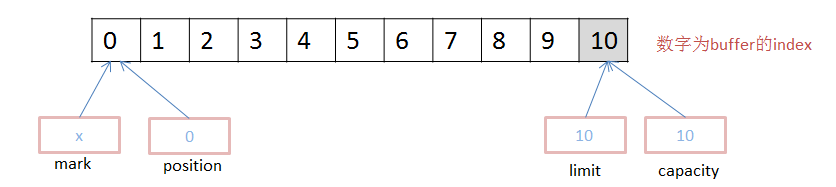
他们之间的关系为: 0 <= mark <= position <= limit <=capacity,来看一个简单的示例,我们新建容量为10的ByteBuffer(图中mark有误,不指向任何内存):
2.缓存区API
我们来看看Buffer类的方法签名,它是所有缓存类的基类:
public abstract class Buffer{
public final int capacity();
public final int position();
public final Buffer position(int newPosition);
public final int limit();
public final Buffer limit(int newLimit);
public final Buffer mark();
public final Buffer reset();
public final Buffer clear();
public final Buffer flip();
public final Buffer rewind();
public final int remaining();
public final boolean hasRemaining();
public abstract boolean isReadOnly();
}可以看到很多方法返回该类引用,因此可以进行级联操作如:buffer.position(5).mark().reset()
2.1 缓存数据的存取
get()和put(),针对这两个方法,因为每个具体的Buffer类返回的对象及参数不同,因此定义在了每个具体的Buffer类中了。以ByteBuffer类为例,看看方法的签名。
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer>{
public abstract byte get();
public abstract byte get(int index);
public abstract ByteBuffer put(byte b);
public abstract ByteBuffer put(int index, byte b);
}
使用get(),put()会导致position++。当position超过limit时,会抛出异常。
看一个例子,将‘hello’字符串存入一个ByteBuffer中。
执行代码:buffer.put((byte)'h').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o');
上面代码执行后,缓存区如下:
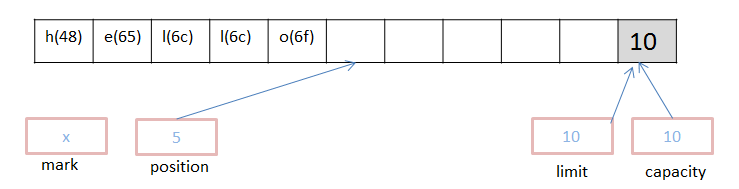
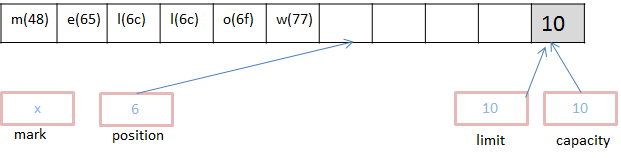
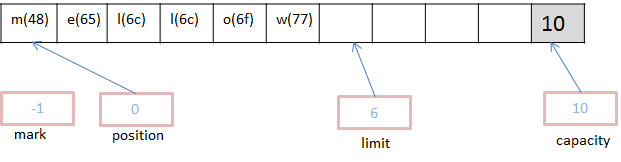
如果我们想更改上图中的‘h’为‘m’,则执行如下代码:
buffer.put(0,(byte)'m').put((byte)'w'),这时缓存区如下:
2.2缓存区翻转
当我们写完数据到缓存区后准备读取时,此时如果调用get()方法,则不会读取到数据,并抛出BufferUnderflowException,那该如何读取呢,这时翻转函数flip()就派上用场了。
调用buffer.flip()后将limit指向position的位置,position指向index为0的数组元素,并将mark置为-1.执行完flip()后如下:
rewind()具有相似的功能,只是不会改变limit的位置。所有可以在读完buffer中的数据后使用rewind()再重读buffer数据。
如果连续两次调用flip(),则limit和position都指向buffer的index为0的元素,当进行读取或写入时都会抛出异常。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









