






levelDB是BigTable的单机版实现,是目前非常流行的存储引擎。用一句话概括levelDB:简约而不简单。简约体现在他的设计思想清楚明了,它的实现简洁,代码量较少。他的设计思想同时也是不简单的,值得仔细研究,实现细节,有很多值得深思的地方。本篇文章作为解析levelDB源码的初版,会有不完善、甚至不正确的地方,敬请谅解。java版本的源码,参见https://github.com/dain/leveldb。
共分为3部分:写操作、读操作、compact。
一、写操作
ldb的单机写操作性能好,100byte为value tps可以达到7w左右。ldb在一定程度上可以说是牺牲了读的性能,保证了写的性能。很快就会知道为什么写更快。
DBImpl.java 是引擎的实现,put接口中的option对象可以自定义字段和方法,扩展引擎。
首先进入方法makeRoomForWrite(boolean force),默认force参数为false。接着判断makeRoom的条件:
if (allowDelay && versions.numberOfFilesInLevel(0) > L0_SLOWDOWN_WRITES_TRIGGER) {
// We are getting close to hitting a hard limit on the number of
// L0 files. Rather than delaying a single write by several
// seconds when we hit the hard limit, start delaying each
// individual write by 1ms to reduce latency variance. Also,
// this delay hands over some CPU to the compaction thread in
// case it is sharing the same core as the writer.
try {
mutex.unlock();
Thread.sleep(1);
}
catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException(e);
}
finally {
mutex.lock();
}
// Do not delay a single write more than once
allowDelay = false;
}默认的level0层文件数是4,缓冲写的触发条件是level0文件数>8。会将CPU资源交给compaction操作,因为在backgroundCall()时获取了重入锁。接着,如果memTable还有空间,则跳过makeRoom,如果此时正在执行Compaction或者level0文件数超过12个,则执行backgroundCondition.awaitUninterruptibly();暂停当前线程。 如果memTable没有足够空间,其他条件又正常,则执行如下过程,关闭当前log日志,创建新log日志,memTable赋值给ImmutableTable,创建新memTable,非常好理解:
// Attempt to switch to a new memtable and trigger compaction of old
Preconditions.checkState(versions.getPrevLogNumber() == 0);
// close the existing log
try {
log.close();
}
catch (IOException e) {
throw new RuntimeException("Unable to close log file " + log.getFile(), e);
}
// open a new log
long logNumber = versions.getNextFileNumber();
try {
this.log = Logs.createLogWriter(new File(databaseDir, Filename.logFileName(logNumber)), logNumber);
}
catch (IOException e) {
throw new RuntimeException("Unable to open new log file " +
new File(databaseDir, Filename.logFileName(logNumber)).getAbsoluteFile(), e);
}
// create a new mem table
immutableMemTable = memTable;
memTable = new MemTable(internalKeyComparator);
// Do not force another compaction there is space available
force = false;
maybeScheduleCompaction();需要深层次看的是log日志的类型。如果是64操作系统架构,则为MMapLogWriter,否则为FileChannelLogWriter。其实虽然是先将更新操作写入log日志,拿MMapLogWriter为例,但还是将record写入log日志映射的mappedByteBuffer中,也是写入内存,如果mmap空间不足,会调unmap()刷盘,mmap堆外内存,每一块对外内存多有对应的cleaner,执行刷盘操作。所以如果发生掉电等异常情况,(直接)内存中的所有record也是无法恢复的,对于日志的操作,后面还会有详细说明。
接着调maybeScheduleCompaction(),写操作会触发compact操作,读操作同样也会触发,对于Compaction请直接参考第三节。
f7出来,,每次对DB的更新都会更新version的LastSequence。这些更新操作会先写入日志文件。写入之前对更新操作执行一些包装操作。其实要记录数据,往往将数据的元数据,例如suquence、某些字段的长度写入‘header’中,将值写入‘body’。record也包含这两个部分,header中依次保存sequence、updates size、updates length。ldb在record中写入一个int或long型数字,都是变长存储的。原本int 4个字节,long 8个字节,但ldb不会将前面全零的byte存下来。让我们来仔细看看,先看int:
public static void writeVariableLengthInt(int value, SliceOutput sliceOutput)
{
int highBitMask = 0x80;
if (value < (1 << 7) && value >= 0) {
sliceOutput.writeByte(value);
}
else if (value < (1 << 14) && value > 0) {
sliceOutput.writeByte(value | highBitMask);
sliceOutput.writeByte(value >>> 7);
}
else if (value < (1 << 21) && value > 0) {
sliceOutput.writeByte(value | highBitMask);
sliceOutput.writeByte((value >>> 7) | highBitMask);
sliceOutput.writeByte(value >>> 14);
}
else if (value < (1 << 28) && value > 0) {
sliceOutput.writeByte(value | highBitMask);
sliceOutput.writeByte((value >>> 7) | highBitMask);
sliceOutput.writeByte((value >>> 14) | highBitMask);
sliceOutput.writeByte(value >>> 21);
}
else {
sliceOutput.writeByte(value | highBitMask);
sliceOutput.writeByte((value >>> 7) | highBitMask);
sliceOutput.writeByte((value >>> 14) | highBitMask);
sliceOutput.writeByte((value >>> 21) | highBitMask);
sliceOutput.writeByte(value >>> 28);
}
}如果value < pow(2, 7),那么直接将低位byte写入,高位舍弃。如果pow(2, 7) < value < pow(2, 14),先或掩码将低位byte最高位置1,再将剩余的高位byte继续写入output,舍弃更高位,以此类推。其核心思想就是用最高位0还是1决定一个变长数字的实际长度,如果为0,则是一个新数字的开始。因此可以理解读变长int的过程。接下来是写变长long型:
public static void writeVariableLengthLong(long value, SliceOutput sliceOutput)
{
// while value more than the first 7 bits set
while ((value & (~0x7f)) != 0) {
sliceOutput.writeByte((int) ((value & 0x7f) | 0x80));
value >>>= 7;
}
sliceOutput.writeByte((int) value);
}这个算法使显然的,value & 0x7f 取后7位,再 | 0x80 将最高位置为1,接着将value右移7位,高位补0。看的时候,,我再想两个很愚蠢的问题- -、第一为什么是& (~0x7f)),而不是& 0x80...这个问题简直是傻逼,我完全忽略了位操作的位数要对齐。第二个问题,,为什么int和long要用两种本质相同,而形式不同的实现呢,还是不理解,明显第二种更简洁,而且效率更高。
包装好record,将record写入log。这里仔细要仔细看。我们可以看到,log日志的默认块大小是32K。算出剩余的块的空间,如果剩余空间不足,会尝试扩容。每当向mappedByteBuffer中写入一块数据,这些数据会落在一个或多个块上。那么根据数据落在块的不同位置,抽象出4中块状态,分别是FULL/FIRST/LAST/MIDDLE。我记得网上有图说明,且算法简单,就是根据每一次写数据的开始和结束位置判断是哪种状态,addRecord实现如下:
public synchronized void addRecord(Slice record, boolean force)
throws IOException
{
Preconditions.checkState(!closed.get(), "Log has been closed");
SliceInput sliceInput = record.input();
// used to track first, middle and last blocks
boolean begin = true;
// Fragment the record int chunks as necessary and write it. Note that if record
// is empty, we still want to iterate once to write a single
// zero-length chunk.
do {
int bytesRemainingInBlock = BLOCK_SIZE - blockOffset;
Preconditions.checkState(bytesRemainingInBlock >= 0);
// Switch to a new block if necessary
if (bytesRemainingInBlock < HEADER_SIZE) {
if (bytesRemainingInBlock > 0) {
// Fill the rest of the block with zeros
// todo lame... need a better way to write zeros
ensureCapacity(bytesRemainingInBlock);
mappedByteBuffer.put(new byte[bytesRemainingInBlock]);
}
blockOffset = 0;
bytesRemainingInBlock = BLOCK_SIZE - blockOffset;
}
// Invariant: we never leave less than HEADER_SIZE bytes available in a block
int bytesAvailableInBlock = bytesRemainingInBlock - HEADER_SIZE;
Preconditions.checkState(bytesAvailableInBlock >= 0);
// if there are more bytes in the record then there are available in the block,
// fragment the record; otherwise write to the end of the record
boolean end;
int fragmentLength;
if (sliceInput.available() > bytesAvailableInBlock) {
end = false;
fragmentLength = bytesAvailableInBlock;
}
else {
end = true;
fragmentLength = sliceInput.available();
}
// determine block type
LogChunkType type;
if (begin && end) {
type = LogChunkType.FULL;
}
else if (begin) {
type = LogChunkType.FIRST;
}
else if (end) {
type = LogChunkType.LAST;
}
else {
type = LogChunkType.MIDDLE;
}ldb先写文件,后写内存。接着执行更新memTable的操作:
updates.forEach(new InsertIntoHandler(memTable, sequenceBegin));memTable在java版本中的类型是ConcurrentSkipListMap。跳表是典型的用空间换时间的数据结构。插入、删除、修改、查询的时间复杂度平均可以达到O(logn)。个人觉得是一个很有想象力的数据结构。点进去可以看到,不管是add还是delete,都调memTable的add方法。只是valueType不同。
最后会返回最新的sequence。写操作返回。我们可以清晰的看到,ldb的写操作是直接写内存,只要Compaction不出现问题,保证level 0层文件保持稳定,就不会影响写。
但还是有几个遗留的问题:1.log日志适用于recover的,但什么时候废弃 2.恢复过程是如何读log日志的 3.变长int和long为什么形式不同,这些问题我们慢慢研究,带着问题看源码,效果更好。??
第一个疑问,,log文件什么时候废弃。当执行deleteObsoleteFiles时,只保留当前和前一次的日志文件。
case LOG:
keep = ((number >= versions.getLogNumber()) ||
(number == versions.getPrevLogNumber()));
break;第三个疑问,,还没找到合理的解释。测试过,long的效率要略优于int。
二、读操作
作为引擎,ldb中提供完整的读操作。所谓完整的读操作是指,先从memTable中读,如果没读到则读immutableTable,还没读到则读level0,进而读level L。参见DBImpl的get方法。
读、写内存中的memTable或immutableTable都要先获取重入锁mutex,读、写结束之后,释放锁。memTable和immutableTable本质是相同的,感觉跳表也挺奇怪的,调table.ceilingEntry(key)找key,跳表的实现有待研究。?
接着调versions.get(lookupKey);点进去看看。readStats用于记录记录查找特定层级文件时第一个遍历的文件,和层数。与compaction相关,频繁的读某个一文件会导致compaction,但ldb的compact的策略是“文件数量多引起的conpact优先于seek过多导致的compact”,这个结论第三章会看到。下面的代码通俗易懂,先从l0中get,否则遍历各个层次:
public LookupResult get(LookupKey key)
{
// We can search level-by-level since entries never hop across
// levels. Therefore we are guaranteed that if we find data
// in an smaller level, later levels are irrelevant.
ReadStats readStats = new ReadStats();
LookupResult lookupResult = level0.get(key, readStats);
if (lookupResult == null) {
for (Level level : levels) {
lookupResult = level.get(key, readStats);
if (lookupResult != null) {
break;
}
}
}
updateStats(readStats.getSeekFileLevel(), readStats.getSeekFile());
return lookupResult;
}点进去,level0.get()。我们知道level0的文件是overlapping的,所以先遍历所有文件,找到包含指定key的文件。然后对其按照时间进行排序 Collections.sort(fileMetaDataList, NEWEST_FIRST);接着遍历所有包含key的文件,为每个文件创建iterator,这个iterator是蛮关键的,所以点进去看BlockIterator:
/**
* Reads the entry at the current data readIndex.
* After this method, data readIndex is positioned at the beginning of the next entry
* or at the end of data if there was not a next entry.
*
* @return true if an entry was read
*/
private static BlockEntry readEntry(SliceInput data, BlockEntry previousEntry)
{
Preconditions.checkNotNull(data, "data is null");
// read entry header
int sharedKeyLength = VariableLengthQuantity.readVariableLengthInt(data);
int nonSharedKeyLength = VariableLengthQuantity.readVariableLengthInt(data);
int valueLength = VariableLengthQuantity.readVariableLengthInt(data);
// read key
Slice key = Slices.allocate(sharedKeyLength + nonSharedKeyLength);
SliceOutput sliceOutput = key.output();
if (sharedKeyLength > 0) {
Preconditions.checkState(previousEntry != null, "Entry has a shared key but no previous entry was provided");
sliceOutput.writeBytes(previousEntry.getKey(), 0, sharedKeyLength);
}
sliceOutput.writeBytes(data, nonSharedKeyLength);
// read value
Slice value = data.readSlice(valueLength);
return new BlockEntry(key, value);
}首先read header,读取三个长度。因为在level >= 1 文件中key都是有序的,所以ldb对key进行优化存储,如果两个可以有相同的前缀(此处,仅描述成相同的前缀,详见compaction),ldb不会将重复的部分重复存储,而是通过记录长度的方式,压缩空间。sharedKeyLength顾名思义是key共享部分的长度,nonSharedKeyLength显而易见。很显然,这些数字也是变长的,前面说过写变长变量的方法,读取则很好理解了。每次都会传入前一个key,是为了获取共享部分。后面的写操作更显然,分两次拼接key,读取value,返回entry。
f7出去,,iterator.seek(key.getInternalKey());ldb对key进行了很多不同类型的包装,用户也可以包装自己的key,实现功能扩展,比如增加过期时间或逻辑桶号等等。seek过程是要仔细看看的,因为我们看到,seek调用之后,就已经定位到了对应KV的位置,通过再次对比key就可以返回结果了。所以核心就是如何seek:
/**
* Repositions the iterator so the key of the next BlockElement returned greater than or equal to the specified targetKey.
*/
@Override
public void seek(Slice targetKey)
{
if (restartCount == 0) {
return;
}
int left = 0;
int right = restartCount - 1;
// binary search restart positions to find the restart position immediately before the targetKey
while (left < right) {
int mid = (left + right + 1) / 2;
seekToRestartPosition(mid);
if (comparator.compare(nextEntry.getKey(), targetKey) < 0) {
// key at mid is smaller than targetKey. Therefore all restart
// blocks before mid are uninteresting.
left = mid;
}
else {
// key at mid is greater than or equal to targetKey. Therefore
// all restart blocks at or after mid are uninteresting.
right = mid - 1;
}
}
// linear search (within restart block) for first key greater than or equal to targetKey
for (seekToRestartPosition(left); nextEntry != null; next()) {
if (comparator.compare(peek().getKey(), targetKey) >= 0) {
break;
}
}
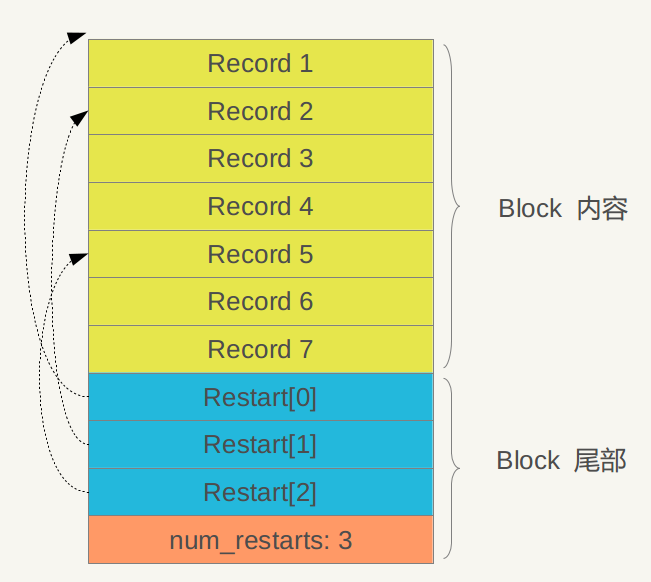
}restartCount是一个Block中检查点的数量,它是如何算出来的,暂时放一放。所谓检查点,因为ldb存储key的时候不存重复的部分,检查点就是记录所有完整key的下标位置,如下图所示,图是盗用网上的。这样就非常好理解了。用二分法先找到包含key所在的一段区域,比如是record4,会先找到record2,再从record2开始遍历。看过这张图,检查点数量的计算方法就显而易见了,源码如下:
// key restart count is the last int of the block
int restartCount = block.getInt(block.length() - SIZE_OF_INT);
if (restartCount > 0) {
// restarts are written at the end of the block
int restartOffset = block.length() - (1 + restartCount) * SIZE_OF_INT;
Preconditions.checkArgument(restartOffset < block.length() - SIZE_OF_INT, "Block is corrupt: restart offset count is greater than block size");
restartPositions = block.slice(restartOffset, restartCount * SIZE_OF_INT);
// data starts at 0 and extends to the restart index
data = block.slice(0, restartOffset);
}restartCount直接读取最后int,restartOffset显然就是restart[0]的偏移量,restartPositions就是上图蓝色这段byte数组,表示所有的重启点。在构造BlockIterator,传入了restartPositions。seek中的重启点的数量也是显然的,除以4即可。Block的结构和二分查找等细节,是ldb中值得思考和掌握的。当然不要误解,restart部分和num_restarts都是int,其他的record长度不限。块的元数据往往存在块的尾部。
@Override
public BlockIterator iterator()
{
return new BlockIterator(data, restartPositions, comparator);
}因为写操作,只将所有的记录写入内存,而文件则是由compaction产生的,所以在读操作这一章,出现了很多陌生的东西,当然如果你已经理解读的过程,那么compaction就更容易理解了。当然如果你已经开始看ldb源码解析,那么你对ldb的结构应该是有了解的。下面的compaction解析会逐步解答上面遗留的问题。
三、Compaction
compaction是压缩归档。是LSM树结构的具体实现。
在DBImpl.get()、makeRoomForWrite()中都会调用maybeScheduleCompaction();看看DBImpl.get() :
// schedule compaction if necessary
mutex.lock();
try {
if (versions.needsCompaction()) {
maybeScheduleCompaction();
}
}
finally {
mutex.unlock();
}什么时候才需要compaction操作呢,进入needsCompaction(),两个条件满足其一即可:
public boolean needsCompaction()
{
return current.getCompactionScore() >= 1 || current.getFileToCompact() != null;
}第一个条件是分数>=1,出现了分数这个概念,第二个条件是否有fileToCompact。下面看分数是如何计算出来的,以及toCompact的file是如何筛选出来的:
private void finalizeVersion(Version version)
{
// Precomputed best level for next compaction
int bestLevel = -1;
double bestScore = -1;
for (int level = 0; level < version.numberOfLevels() - 1; level++) {
double score;
if (level == 0) {
// We treat level-0 specially by bounding the number of files
// instead of number of bytes for two reasons:
//
// (1) With larger write-buffer sizes, it is nice not to do too
// many level-0 compactions.
//
// (2) The files in level-0 are merged on every read and
// therefore we wish to avoid too many files when the individual
// file size is small (perhaps because of a small write-buffer
// setting, or very high compression ratios, or lots of
// overwrites/deletions).
score = 1.0 * version.numberOfFilesInLevel(level) / L0_COMPACTION_TRIGGER;
}
else {
// Compute the ratio of current size to size limit.
long levelBytes = 0;
for (FileMetaData fileMetaData : version.getFiles(level)) {
levelBytes += fileMetaData.getFileSize();
}
score = 1.0 * levelBytes / maxBytesForLevel(level);
}
if (score > bestScore) {
bestLevel = level;
bestScore = score;
}
}
version.setCompactionLevel(bestLevel);
version.setCompactionScore(bestScore);
}level-0和其他层次的分数计算方法是不同的,注释中写的很清楚,level-0采用文件数的原因是1.写缓冲越大,越不适合做level-0层的归档;2.level-0层文件每次读都会执行归档,所以会避免过多的小的level-0层文件。其他level的算法是计算层内文件的总的大小,maxBytesForLevel的算法是单个文件大小为10MB,leve L层,最多允许容纳pow(10, L)个文件,很好算出结果。
private boolean updateStats(int seekFileLevel, FileMetaData seekFile)
{
if (seekFile == null) {
return false;
}
seekFile.decrementAllowedSeeks();
if (seekFile.getAllowedSeeks() <= 0 && fileToCompact == null) {
fileToCompact = seekFile;
fileToCompactLevel = seekFileLevel;
return true;
}
return false;
}这个函数在读操作过程中掉用过,传进来的是特定层次读到的第一个文件。接着该seekFile的seek次数减一,如果已经<0则将该seekFile赋值给fileToCompact。一个文件的初始allowedSeeks值是多少呢:
int allowedSeeks = (int) (fileMetaData.getFileSize() / 16384);
if (allowedSeeks < 100) {
allowedSeeks = 100;
}
fileMetaData.setAllowedSeeks(allowedSeeks);这段代码在后面还会出现。经过上面的分析,needsCompaction就很清晰了。接下来进入maybeScheduleCompaction:
protected void maybeScheduleCompaction()
{
Preconditions.checkState(mutex.isHeldByCurrentThread());
if (backgroundCompaction != null) {
// Already scheduled
}
else if (shuttingDown.get()) {
// DB is being shutdown; no more background compactions
}
else if (immutableMemTable == null &&
manualCompaction == null &&
!versions.needsCompaction()) {
// No work to be done
}
else {
backgroundCompaction = compactionExecutor.submit(new Callable<Void>()
{
@Override
public Void call()
throws Exception
{
try {
backgroundCall();
}
catch (DatabaseShutdownException ignored) {
} catch (Throwable e) {
e.printStackTrace();
backgroundException = e;
}
return null;
}
});
}
} compactionExecutor = Executors.newSingleThreadExecutor(compactionThreadFactory);一次只对一个层次进行归档操作,如果有规定操作正在执行,则直接返回。compaction也会获取重入锁。进入backgroundCompaction():
protected void backgroundCompaction()
throws IOException
{
Preconditions.checkState(mutex.isHeldByCurrentThread());
compactMemTableInternal();
Compaction compaction;
if (manualCompaction != null) {
compaction = versions.compactRange(manualCompaction.level,
new InternalKey(manualCompaction.begin, MAX_SEQUENCE_NUMBER, ValueType.VALUE),
new InternalKey(manualCompaction.end, 0, ValueType.DELETION));
} else {
compaction = versions.pickCompaction();
}
if (compaction == null) {
// no compaction
} else if (manualCompaction == null && compaction.isTrivialMove()) {
// Move file to next level
Preconditions.checkState(compaction.getLevelInputs().size() == 1);
FileMetaData fileMetaData = compaction.getLevelInputs().get(0);
compaction.getEdit().deleteFile(compaction.getLevel(), fileMetaData.getNumber());
compaction.getEdit().addFile(compaction.getLevel() + 1, fileMetaData);
versions.logAndApply(compaction.getEdit());
// log
} else {
CompactionState compactionState = new CompactionState(compaction);
doCompactionWork(compactionState);
cleanupCompaction(compactionState);
}
// manual compaction complete
if (manualCompaction != null) {
manualCompaction = null;
}
}首先归档内存,再计算归档的层次和文件,然后执行compaction。一步一步分析,首先是compactMemTableInternal();compactMemTableInternal先将immutableTable写入level-0。看meta = buildTable(mem, fileNumber); 创建FIleChannel,遍历所有KV,这里需要仔细看看,tableBuilder中做了一些细节逻辑的封装,进入add()、finish()看看。
private FileMetaData buildTable(SeekingIterable<InternalKey, Slice> data, long fileNumber)
throws IOException
{
File file = new File(databaseDir, Filename.tableFileName(fileNumber));
try {
InternalKey smallest = null;
InternalKey largest = null;
FileChannel channel = new FileOutputStream(file).getChannel();
try {
TableBuilder tableBuilder = new TableBuilder(options, channel, new InternalUserComparator(internalKeyComparator));
for (Entry<InternalKey, Slice> entry : data) {
// update keys
InternalKey key = entry.getKey();
if (smallest == null) {
smallest = key;
}
largest = key;
tableBuilder.add(key.encode(), entry.getValue());
}
tableBuilder.finish();
}
finally {
try {
channel.force(true);
}
finally {
channel.close();
}
}
if (smallest == null) {
return null;
}
FileMetaData fileMetaData = new FileMetaData(fileNumber, file.length(), smallest, largest);
// verify table can be opened
tableCache.newIterator(fileMetaData);
pendingOutputs.remove(fileNumber);
return fileMetaData;
}
catch (IOException e) {
file.delete();
throw e;
}
}进入tableBuilder.add(k ,v): userComparator默认使用BytewiseComparator。
public void add(Slice key, Slice value)
throws IOException
{
Preconditions.checkNotNull(key, "key is null");
Preconditions.checkNotNull(value, "value is null");
Preconditions.checkState(!closed, "table is finished");
if (entryCount > 0) {
assert (userComparator.compare(key, lastKey) > 0) : "key must be greater than last key";
}
// If we just wrote a block, we can now add the handle to index block
if (pendingIndexEntry) {
Preconditions.checkState(dataBlockBuilder.isEmpty(), "Internal error: Table has a pending index entry but data block builder is empty");
Slice shortestSeparator = userComparator.findShortestSeparator(lastKey, key);
Slice handleEncoding = BlockHandle.writeBlockHandle(pendingHandle);
indexBlockBuilder.add(shortestSeparator, handleEncoding);
pendingIndexEntry = false;
}
lastKey = key;
entryCount++;
dataBlockBuilder.add(key, value);
int estimatedBlockSize = dataBlockBuilder.currentSizeEstimate();
if (estimatedBlockSize >= blockSize) {
flush();
}
}Slice shortestSeparator = userComparator.findShortestSeparator(lastKey, key); 点进去:
@Override
public Slice findShortestSeparator(
Slice start,
Slice limit)
{
// Find length of common prefix
int sharedBytes = BlockBuilder.calculateSharedBytes(start, limit);
// Do not shorten if one string is a prefix of the other
if (sharedBytes < Math.min(start.length(), limit.length())) {
// if we can add one to the last shared byte without overflow and the two keys differ by more than
// one increment at this location.
int lastSharedByte = start.getUnsignedByte(sharedBytes);
if (lastSharedByte < 0xff && lastSharedByte + 1 < limit.getUnsignedByte(sharedBytes)) {
Slice result = start.copySlice(0, sharedBytes + 1);
result.setByte(sharedBytes, lastSharedByte + 1);
assert (compare(result, limit) < 0) : "start must be less than last limit";
return result;
}
}
return start;
}通过依次对比byte,算出sharedBytes,这个数字也对应的第一个不相同的byte的下标。接着,判断一个key是否为另一个key的前缀,如果是的不压缩。并且要求第一个key的第一个不同byte+1 < 第二个key的第一个不同byte。举例:如果start是"abc123",limit是"abc456",则符合压缩的要求,返回的result为"abc2"。前面说过的“前缀”其实是不完整的。
这段逻辑是在pendingIndexEntry == true的前提下执行的,看pendingIndexEntry的引用,发现在TableBuilder的flush()中将其置为true,意味着,当向一个新的block中写入记录时,才会触发这段逻辑,将该block起始的可以写入indexBlockBuilder。这里的lastKey指的是上一个块最后一个key,findShortestSuccessor的逻辑很简单,找到最后这个key第一个不等于0xff的byte,并返回前面所有的bytes。这样做的目的是,节省空间!!这是ldb的一个优化策略。举例:如果lastKey是"aqq",则shortSuccessor是"b"。且pendingHandle也只是在flush()时被重新赋值的。先看finish()和flush():
public void finish()
throws IOException
{
Preconditions.checkState(!closed, "table is finished");
// flush current data block
flush();
// mark table as closed
closed = true;
// write (empty) meta index block
BlockBuilder metaIndexBlockBuilder = new BlockBuilder(256, blockRestartInterval, new BytewiseComparator());
// TODO(postrelease): Add stats and other meta blocks
BlockHandle metaindexBlockHandle = writeBlock(metaIndexBlockBuilder);
// add last handle to index block
if (pendingIndexEntry) {
Slice shortSuccessor = userComparator.findShortSuccessor(lastKey);
Slice handleEncoding = BlockHandle.writeBlockHandle(pendingHandle);
indexBlockBuilder.add(shortSuccessor, handleEncoding);
pendingIndexEntry = false;
}
// write index block
BlockHandle indexBlockHandle = writeBlock(indexBlockBuilder);
// write footer
Footer footer = new Footer(metaindexBlockHandle, indexBlockHandle);
Slice footerEncoding = Footer.writeFooter(footer);
position += fileChannel.write(footerEncoding.toByteBuffer());
} private void flush()
throws IOException
{
Preconditions.checkState(!closed, "table is finished");
if (dataBlockBuilder.isEmpty()) {
return;
}
Preconditions.checkState(!pendingIndexEntry, "Internal error: Table already has a pending index entry to flush");
pendingHandle = writeBlock(dataBlockBuilder);
pendingIndexEntry = true;
}进到 private BlockHandle writeBlock(BlockBuilder blockBuilder) :
private BlockHandle writeBlock(BlockBuilder blockBuilder)
throws IOException
{
// close the block
Slice raw = blockBuilder.finish();
// attempt to compress the block
Slice blockContents = raw;
CompressionType blockCompressionType = CompressionType.NONE;
if (compressionType == CompressionType.SNAPPY) {
ensureCompressedOutputCapacity(maxCompressedLength(raw.length()));
try {
int compressedSize = Snappy.compress(raw.getRawArray(), raw.getRawOffset(), raw.length(), compressedOutput.getRawArray(), 0);
// Don't use the compressed data if compressed less than 12.5%,
if (compressedSize < raw.length() - (raw.length() / 8)) {
blockContents = compressedOutput.slice(0, compressedSize);
blockCompressionType = CompressionType.SNAPPY;
}
}
catch (IOException ignored) {
// compression failed, so just store uncompressed form
}
}
// create block trailer
BlockTrailer blockTrailer = new BlockTrailer(blockCompressionType, crc32c(blockContents, blockCompressionType));
Slice trailer = BlockTrailer.writeBlockTrailer(blockTrailer);
// create a handle to this block
BlockHandle blockHandle = new BlockHandle(position, blockContents.length());
// write data and trailer
position += fileChannel.write(new ByteBuffer[]{blockContents.toByteBuffer(), trailer.toByteBuffer()});
// clean up state
blockBuilder.reset();
return blockHandle;
}blockBuilder.finish(),将重启点依次写入dataBlockBuilder,并写入检查点的数量:
if (entryCount > 0) {
restartPositions.write(block);
block.writeInt(restartPositions.size());
}
else {
block.writeInt(0);
}接着将content压缩,如果压缩率<12.5%则不用压缩。压缩好后,创建blockTrailer,并写在Block后面。Block之间的结构如下图,图也是盗用的,type是压缩算法,接着讲content和trailer写入channel,并返回这段block的偏移量position和长度length。
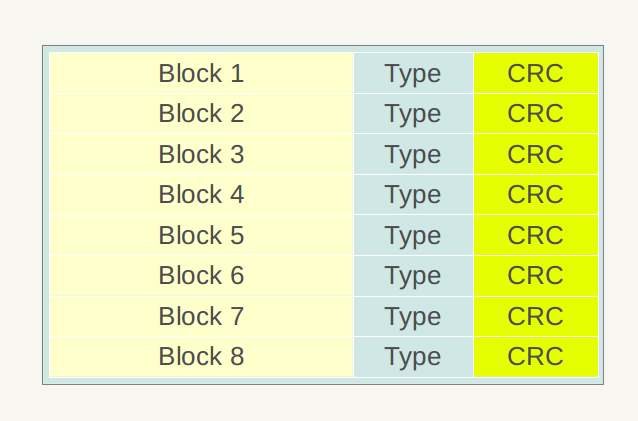
从writeBlock出来,将pendingIndexEntry赋值为true,标志开始写新的Block。从flush() f7出来,感觉进度快多了,开心。当然Snappy和crc的算法是跳过了。。这两个算法都不是ldb特有的,暂时放一放。接着写metaIndexBlockBuilder,metaIndexBlockBuilder是空的。接着写indexBlockBuilder,将lastKey、block的真实的offset和length写入文件底部。在block的最后写入metaIndexBlockBuilder和indexBlockBuilder的索引,即他们的开始位置和长度,封装成footer写入。
再回头看TableBuilder的add方法。它的核心是dataBlockBuilder.add(key, value);blockRestartInterval指的是两个重启点的间距,即能容纳多少个不完整的key。blockRestartInterval默认是16。这个过程就非常好理解了,迭代存储KV,判断是否超过了间隔。存文件的格式,在读操作已经详细分析过了。对于一条记录,依次写入共享长度、非共享长度、value长度、非共享key、value。再更新状态信息:
public void add(Slice key, Slice value)
{
Preconditions.checkNotNull(key, "key is null");
Preconditions.checkNotNull(value, "value is null");
Preconditions.checkState(!finished, "block is finished");
Preconditions.checkPositionIndex(restartBlockEntryCount, blockRestartInterval);
Preconditions.checkArgument(lastKey == null || comparator.compare(key, lastKey) > 0, "key must be greater than last key");
int sharedKeyBytes = 0;
if (restartBlockEntryCount < blockRestartInterval) {
sharedKeyBytes = calculateSharedBytes(key, lastKey);
}
else {
// restart prefix compression
restartPositions.add(block.size());
restartBlockEntryCount = 0;
}
int nonSharedKeyBytes = key.length() - sharedKeyBytes;
// write "<shared><non_shared><value_size>"
VariableLengthQuantity.writeVariableLengthInt(sharedKeyBytes, block);
VariableLengthQuantity.writeVariableLengthInt(nonSharedKeyBytes, block);
VariableLengthQuantity.writeVariableLengthInt(value.length(), block);
// write non-shared key bytes
block.writeBytes(key, sharedKeyBytes, nonSharedKeyBytes);
// write value bytes
block.writeBytes(value, 0, value.length());
// update last key
lastKey = key;
// update state
entryCount++;
restartBlockEntryCount++;
}最后finally,执行channal.force(true); 再验证该文件是否可以被打开,最后返回。buildTable过程结束。pendingOutputs变量应该是存储正在刷盘的文件名,如果成功写入文件,则将其删除。在读写和conpact过程中都有计算最小最大值,虽然这个逻辑简单,但我觉得,,写的还是蛮好的。。:
if (smallest == null) {
smallest = key;
}
largest = key;buildTable的过程解析过了。。出栈出栈,buildTable是在compaction的writeLevel0时调用的。我们继续解析,,完成buildTable,会返回新文件的元数据fileMetaData。接着:
if (meta != null && meta.getFileSize() > 0) {
Slice minUserKey = meta.getSmallest().getUserKey();
Slice maxUserKey = meta.getLargest().getUserKey();
if (base != null) {
level = base.pickLevelForMemTableOutput(minUserKey, maxUserKey);
}
edit.addFile(level, meta);
}貌似这个文件也可能记录在其他level中,进pickLevelForMemTableOutput看下。其目的是为了将文件放入level x,且与level x+1有交集,但重叠的部分不要太大。这是为了避免,如果低层次某个文件与它下一层的所有文件没有交集,则无法达到归档删除无效数据的作用,直接将文件从低层次移动到高层次而已。其实如果真的发生了这种情况,compact也会避免这种无效的读写文件的。pickLevelForMemTableOutput的前提是这个文件跟level0层文件没有交集,原因是,在归档level0层文件时,会先找出所有相互覆盖的文件,作为input,ldb的策略是,低层次的input越多越好,这样一次compaction的效率更高。后面也会有合理增加低层次input的算法,请留意。
从writeLevel0Table中出来。终于出来了,,writeLevel0Table的过程在某个层次下增加了一个文件,并修改了log日志。所以需要对各个层级的文件进行整理,保证它的有序性。接着执行versions.logAndApply(edit);这个过程的调用深度也是蛮深的,点进去看看:
Version version = new Version(this);
Builder builder = new Builder(this, current);
builder.apply(edit);
builder.saveTo(version);
finalizeVersion(version);
...
appendVersion(version);经过排序整理,会形成新的version,代替当前version。先进入builder.apply(edit);再看builder.saveTo(version);哇感觉解析起来好累啊,每一步都要尽可能的明白,希望你也能理解作者的想法。Builder是VersionSet的一个内部类:
public void apply(VersionEdit edit)
{
// Update compaction pointers
for (Entry<Integer, InternalKey> entry : edit.getCompactPointers().entrySet()) {
Integer level = entry.getKey();
InternalKey internalKey = entry.getValue();
versionSet.compactPointers.put(level, internalKey);
}
// Delete files
for (Entry<Integer, Long> entry : edit.getDeletedFiles().entries()) {
Integer level = entry.getKey();
Long fileNumber = entry.getValue();
levels.get(level).deletedFiles.add(fileNumber);
// todo missing update to addedFiles?
}
// Add new files
for (Entry<Integer, FileMetaData> entry : edit.getNewFiles().entries()) {
Integer level = entry.getKey();
FileMetaData fileMetaData = entry.getValue();
// We arrange to automatically compact this file after
// a certain number of seeks. Let's assume:
// (1) One seek costs 10ms
// (2) Writing or reading 1MB costs 10ms (100MB/s)
// (3) A compaction of 1MB does 25MB of IO:
// 1MB read from this level
// 10-12MB read from next level (boundaries may be misaligned)
// 10-12MB written to next level
// This implies that 25 seeks cost the same as the compaction
// of 1MB of data. I.e., one seek costs approximately the
// same as the compaction of 40KB of data. We are a little
// conservative and allow approximately one seek for every 16KB
// of data before triggering a compaction.
int allowedSeeks = (int) (fileMetaData.getFileSize() / 16384);
if (allowedSeeks < 100) {
allowedSeeks = 100;
}
fileMetaData.setAllowedSeeks(allowedSeeks);
levels.get(level).deletedFiles.remove(fileMetaData.getNumber());
levels.get(level).addedFiles.add(fileMetaData);
}
}每一层都会保留compactPointer作为compaction的指针,即从哪里开始对该层次进行归档,ldb的归档策略是轮询的,即会对低层次的文件按顺序进行归档,如果达到最后,则返回第一个文件。后面会看到这种机制的实现。刚刚在writeLevel0Table中调了edit.addFile(level, meta);所以当遍历getNewFiles时,会设置新文件的allowedSeeks,更新levels,再看saveTo:
/**
* Saves the current state in specified version.
*/
public void saveTo(Version version)
throws IOException
{
FileMetaDataBySmallestKey cmp = new FileMetaDataBySmallestKey(versionSet.internalKeyComparator);
for (int level = 0; level < baseVersion.numberOfLevels(); level++) {
// Merge the set of added files with the set of pre-existing files.
// Drop any deleted files. Store the result in *v.
Collection<FileMetaData> baseFiles = baseVersion.getFiles().asMap().get(level);
if (baseFiles == null) {
baseFiles = ImmutableList.of();
}
SortedSet<FileMetaData> addedFiles = levels.get(level).addedFiles;
if (addedFiles == null) {
addedFiles = ImmutableSortedSet.of();
}
// files must be added in sorted order so assertion check in maybeAddFile works
ArrayList<FileMetaData> sortedFiles = newArrayListWithCapacity(baseFiles.size() + addedFiles.size());
sortedFiles.addAll(baseFiles);
sortedFiles.addAll(addedFiles);
Collections.sort(sortedFiles, cmp);
for (FileMetaData fileMetaData : sortedFiles) {
maybeAddFile(version, level, fileMetaData);
}
//#ifndef NDEBUG todo
// Make sure there is no overlap in levels > 0
version.assertNoOverlappingFiles();
//#endif
}
}所谓saveTo的意思是,将added的文件存入baseFile。在整个解析的过程中,多次看到comparator,一直也没有看过它的compare方法,即依次对比byte大小:
public int compareTo(Slice that)
{
if (this == that) {
return 0;
}
if (this.data == that.data && length == that.length && offset == that.offset) {
return 0;
}
int minLength = Math.min(this.length, that.length);
for (int i = 0; i < minLength; i++) {
int thisByte = 0xFF & this.data[this.offset + i];
int thatByte = 0xFF & that.data[that.offset + i];
if (thisByte != thatByte) {
return (thisByte) - (thatByte);
}
}
return this.length - that.length;
}将文件按照最小key进行排序后,向version中写入排好序的文件。进入maybeAddFile。这里会判断前后两个文件是否有相交。level-0跳过,去version最后一个文件的最大key与新加问价的最小key进行对比,很好理解:
private void maybeAddFile(Version version, int level, FileMetaData fileMetaData)
throws IOException
{
if (levels.get(level).deletedFiles.contains(fileMetaData.getNumber())) {
// File is deleted: do nothing
}
else {
List<FileMetaData> files = version.getFiles(level);
if (level > 0 && !files.isEmpty()) {
// Must not overlap
boolean filesOverlap = versionSet.internalKeyComparator.compare(files.get(files.size() - 1).getLargest(), fileMetaData.getSmallest()) >= 0;
if (filesOverlap) {
// A memory compaction, while this compaction was running, resulted in a a database state that is
// incompatible with the compaction. This is rare and expensive to detect while the compaction is
// running, so we catch here simply discard the work.
throw new IOException(String.format("Compaction is obsolete: Overlapping files %s and %s in level %s",
files.get(files.size() - 1).getNumber(),
fileMetaData.getNumber(), level));
}
}
version.addFile(level, fileMetaData);
}
}至此,对内存的归档操作就已经解析结束了。ldb的策略是优先对内存进行归档,后面解析到doCompactionWork()时还有可能对内存进行归档。其实我们刚刚分析了一小部分,后面还有很多逻辑,通过compaction可以辐射到ldb的很多部分的实现。compaction是ldb最关键的实现!!
接着看辣。manualCompaction,搜索它的引用,发现这个其实是ldb为用户预留的一个接口实现,可以让用户对compaction进行功能扩展,实现对指定层次的归档。 compaction = versions.compactRange,点进去看。getOverlappingInputs略过,关键看setupOtherInputs(level, levelInputs); setup的注释也写得非常清楚,在不扩展level+1层的输入文件的同时,尽可能扩大level层的输入文件。expanded0是level+1层范围映射回level的文件范围,expanded1是expanded0再映射回level+1的范围,通过对比expanded1和原来的levelUpInputs,来判断是否增加了level+1的文件数,如果没增加,则将expanded0作为level的输入。同时还会计算grandparents,进入Compaction的构造方法,关于grandparents用法会在后面提到。
public Compaction compactRange(int level, InternalKey begin, InternalKey end)
{
List<FileMetaData> levelInputs = getOverlappingInputs(level, begin, end);
if (levelInputs.isEmpty()) {
return null;
}
return setupOtherInputs(level, levelInputs);
} private Compaction setupOtherInputs(int level, List<FileMetaData> levelInputs)
{
Entry<InternalKey, InternalKey> range = getRange(levelInputs);
InternalKey smallest = range.getKey();
InternalKey largest = range.getValue();
List<FileMetaData> levelUpInputs = getOverlappingInputs(level + 1, smallest, largest);
// Get entire range covered by compaction
range = getRange(levelInputs, levelUpInputs);
InternalKey allStart = range.getKey();
InternalKey allLimit = range.getValue();
// See if we can grow the number of inputs in "level" without
// changing the number of "level+1" files we pick up.
if (!levelUpInputs.isEmpty()) {
List<FileMetaData> expanded0 = getOverlappingInputs(level, allStart, allLimit);
if (expanded0.size() > levelInputs.size()) {
range = getRange(expanded0);
InternalKey newStart = range.getKey();
InternalKey newLimit = range.getValue();
List<FileMetaData> expanded1 = getOverlappingInputs(level + 1, newStart, newLimit);
if (expanded1.size() == levelUpInputs.size()) {
// Log(options_->info_log,
// "Expanding@%d %d+%d to %d+%d\n",
// level,
// int(c->inputs_[0].size()),
// int(c->inputs_[1].size()),
// int(expanded0.size()),
// int(expanded1.size()));
smallest = newStart;
largest = newLimit;
levelInputs = expanded0;
levelUpInputs = expanded1;
range = getRange(levelInputs, levelUpInputs);
allStart = range.getKey();
allLimit = range.getValue();
}
}
}
// Compute the set of grandparent files that overlap this compaction
// (parent == level+1; grandparent == level+2)
List<FileMetaData> grandparents = null;
if (level + 2 < NUM_LEVELS) {
grandparents = getOverlappingInputs(level + 2, allStart, allLimit);
}
// if (false) {
// Log(options_ - > info_log, "Compacting %d '%s' .. '%s'",
// level,
// EscapeString(smallest.Encode()).c_str(),
// EscapeString(largest.Encode()).c_str());
// }
Compaction compaction = new Compaction(current, level, levelInputs, levelUpInputs, grandparents);
// Update the place where we will do the next compaction for this level.
// We update this immediately instead of waiting for the VersionEdit
// to be applied so that if the compaction fails, we will try a different
// key range next time.
compactPointers.put(level, largest);
compaction.getEdit().setCompactPointer(level, largest);
return compaction;
}再进入compaction = versions.pickCompaction();ldb的策略是,文件大小过大而触发归档的优先于读文件过多而触发归档。从level层找到第一个比compact指针大的文件,如果没找到,则说明已经到达最后,则将第一个文件加入输入。如果没有某个层次分数超过1,且触发了seekCompaction,则将getFileToCompactLevel作为输入。同样会执行setupOtherInputs,扩大level层的输入。机制都是相似的。
public Compaction pickCompaction()
{
// We prefer compactions triggered by too much data in a level over
// the compactions triggered by seeks.
boolean sizeCompaction = (current.getCompactionScore() >= 1);
boolean seekCompaction = (current.getFileToCompact() != null);
int level;
List<FileMetaData> levelInputs;
if (sizeCompaction) {
level = current.getCompactionLevel();
Preconditions.checkState(level >= 0);
Preconditions.checkState(level + 1 < NUM_LEVELS);
// Pick the first file that comes after compact_pointer_[level]
levelInputs = newArrayList();
for (FileMetaData fileMetaData : current.getFiles(level)) {
if (!compactPointers.containsKey(level) ||
internalKeyComparator.compare(fileMetaData.getLargest(), compactPointers.get(level)) > 0) {
levelInputs.add(fileMetaData);
break;
}
}
if (levelInputs.isEmpty()) {
// Wrap-around to the beginning of the key space
levelInputs.add(current.getFiles(level).get(0));
}
}
else if (seekCompaction) {
level = current.getFileToCompactLevel();
levelInputs = ImmutableList.of(current.getFileToCompact());
}
else {
return null;
}
// Files in level 0 may overlap each other, so pick up all overlapping ones
if (level == 0) {
Entry<InternalKey, InternalKey> range = getRange(levelInputs);
// Note that the next call will discard the file we placed in
// c->inputs_[0] earlier and replace it with an overlapping set
// which will include the picked file.
levelInputs = getOverlappingInputs(0, range.getKey(), range.getValue());
Preconditions.checkState(!levelInputs.isEmpty());
}
Compaction compaction = setupOtherInputs(level, levelInputs);
return compaction;
}已经算出对哪一层的哪些文件进行归档,下面的判断是为了避免TrivialMove,即level层的输入文件与level+1层没有交集且与grandparents没有过多的交集,则将该文件直接修改为level+1层文件,而不执行对输入文件的读取,以及归档为新文件的过程。接着看doCompactionWork,如何执行归档的:
遍历输入的kv前,通过versions.makeInputIterator(compactionState.compaction);获取迭代器。发现,level-0和其它层次的迭代器类型不同,分别看两种迭代器的实现:
Level0Iterator.getNextElement():
@Override
protected Entry<InternalKey, Slice> getNextElement()
{
Entry<InternalKey, Slice> result = null;
ComparableIterator nextIterator = priorityQueue.poll();
if (nextIterator != null) {
result = nextIterator.next();
if (nextIterator.hasNext()) {
priorityQueue.add(nextIterator);
}
}
return result;
}priorityQueue里存的是每个文件的迭代器,nextIterator.next()本质调用BlockIterator的next方法,进而调用readEntry,前面有列举过。priorityQueue传入的比较器是按照key排序的,所以可以实现从多个输入文件中按key的顺序找出next。从队列中拿出后还要塞回去。每一次从优先级队列中拿优先级最高的元素,add和poll操作的时间复杂度为O(logn)。在构造priorityQueue时,没有传入comparator,对于priorityQueue的具体实现还是留给读者自己去探索。看priorityQueue的一个方法,也许会使思路明朗一些:
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}再看Level0Iterator.ComparableInterator的compareTo方法,因为level0多个文件是相互覆盖的,所以需要所有文件中最小的key,而LevelIterator则没有用到优先级队列,因为文件是有序的。我们注意到这两个Iterator继承和实现都是相同的,均为extends AbstractSeekingIterator<InternalKey, Slice> implements InternalIterator:
@Override
public int compareTo(ComparableIterator that)
{
int result = comparator.compare(this.nextElement.getKey(), that.nextElement.getKey());
if (result == 0) {
result = Ints.compare(this.ordinal, that.ordinal);
}
return result;
}LevelIterator.getNextElement():
@Override
protected Entry<InternalKey, Slice> getNextElement()
{
// note: it must be here & not where 'current' is assigned,
// because otherwise we'll have called inputs.next() before throwing
// the first NPE, and the next time around we'll call inputs.next()
// again, incorrectly moving beyond the error.
boolean currentHasNext = false;
while (true) {
if (current != null) {
currentHasNext = current.hasNext();
}
if (!(currentHasNext)) {
if (index < files.size()) {
current = openNextFile();
}
else {
break;
}
}
else {
break;
}
}
if (currentHasNext) {
return current.next();
}
else {
// set current to empty iterator to avoid extra calls to user iterators
current = null;
return null;
}
}
private InternalTableIterator openNextFile()
{
FileMetaData fileMetaData = files.get(index);
index++;
return tableCache.newIterator(fileMetaData);
}current.hasNext();指的是当前文件是否还有记录,,而openNextFile则依次打开list files的文件。其实是很好理解的。至此,获取Iterator的过程解析结束,在解析的过程中,也分析了Iterator是如何迭代文件的。继续回到doCompactionWork。ldb还会优先将内存归档,防止在执行更高层次的文件归档之前,还有immutableTable需要归档,因为内存的归档会影响level0的文件数,进而影响后面的归档顺序。
shouldStopBefore(key)为了防止某个key覆盖了太多grandparents的文件,防止后面level+1层的归档耗时过长。接着判断某个key是否应该被舍弃,其实,这段逻辑能看懂60%,还是要详细推敲的,此处留个疑问?如果不舍弃,则执行刷盘操作,刷盘的操作前面都解析过,这里只剩下简单的逻辑,所以跳过。
如果是一个独立的key,不重复,首先会进入First occurrence,将lastSequenceForKey赋值为最大值。执行完一个判断,lastSequenceForKey被置为key的sequence。如果第二个key与前面相同,lastSequenceForKey一定是 <= smallestSnapshot。因为smallestSnapshot是version的当前最大sequence。所以新的key就覆盖了老的相同的key。DELETE标签执行的删除操作也是在这里删除的。
compactionState.compaction.isBaseLevelForKey(key.getUserKey())这里判断DELETE标签是否应该删除。判断条件是,比level+1更高层次的文件中是否可能包含这个key。因此从level+2遍历文件,如果有任何一个文件包含,则返回false。遍历结束返回true。levelPointers的作用是减少遍历文件的次数。其原理是因为key都是逐渐增加的,所以当第二次验证某个key的DELETE标签,那么前面验证过的文件就已经不用在判断一遍了。因此提高了效率。
boolean drop = false;
// todo if key doesn't parse (it is corrupted),
if (false /*!ParseInternalKey(key, &ikey)*/) {
// do not hide error keys
currentUserKey = null;
hasCurrentUserKey = false;
lastSequenceForKey = MAX_SEQUENCE_NUMBER;
}
else {
if (!hasCurrentUserKey || internalKeyComparator.getUserComparator().compare(key.getUserKey(), currentUserKey) != 0) {
// First occurrence of this user key
currentUserKey = key.getUserKey();
hasCurrentUserKey = true;
lastSequenceForKey = MAX_SEQUENCE_NUMBER;
}
if (lastSequenceForKey <= compactionState.smallestSnapshot) {
// Hidden by an newer entry for same user key
drop = true; // (A)
}
else if (key.getValueType() == DELETION &&
key.getSequenceNumber() <= compactionState.smallestSnapshot &&
compactionState.compaction.isBaseLevelForKey(key.getUserKey())) {
// For this user key:
// (1) there is no data in higher levels
// (2) data in lower levels will have larger sequence numbers
// (3) data in layers that are being compacted here and have
// smaller sequence numbers will be dropped in the next
// few iterations of this loop (by rule (A) above).
// Therefore this deletion marker is obsolete and can be dropped.
drop = true;
}
lastSequenceForKey = key.getSequenceNumber();
} // Returns true if the information we have available guarantees that
// the compaction is producing data in "level+1" for which no data exists
// in levels greater than "level+1".
public boolean isBaseLevelForKey(Slice userKey)
{
// Maybe use binary search to find right entry instead of linear search?
UserComparator userComparator = inputVersion.getInternalKeyComparator().getUserComparator();
for (int level = this.level + 2; level < NUM_LEVELS; level++) {
List<FileMetaData> files = inputVersion.getFiles(level);
while (levelPointers[level] < files.size()) {
FileMetaData f = files.get(levelPointers[level]);
if (userComparator.compare(userKey, f.getLargest().getUserKey()) <= 0) {
// We've advanced far enough
if (userComparator.compare(userKey, f.getSmallest().getUserKey()) >= 0) {
// Key falls in this file's range, so definitely not base level
return false;
}
break;
}
levelPointers[level]++;
}
}
return true;
}至此,compaction解析结束。
还有两个问题1.recover 2.cache,以后慢慢补充。??















 7070
7070

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









