







在上篇文章中梳理了数据读取的三种方式,但是在实际项目当中,由于数据量一般会比较大,所以更多的会使用第三种方法(即直接从文件中读取)。但是对于不同的文件类型,需要不同的文件处理API,有时候比较容易弄混淆,接下来就来梳理一下。
一.文件读取流程
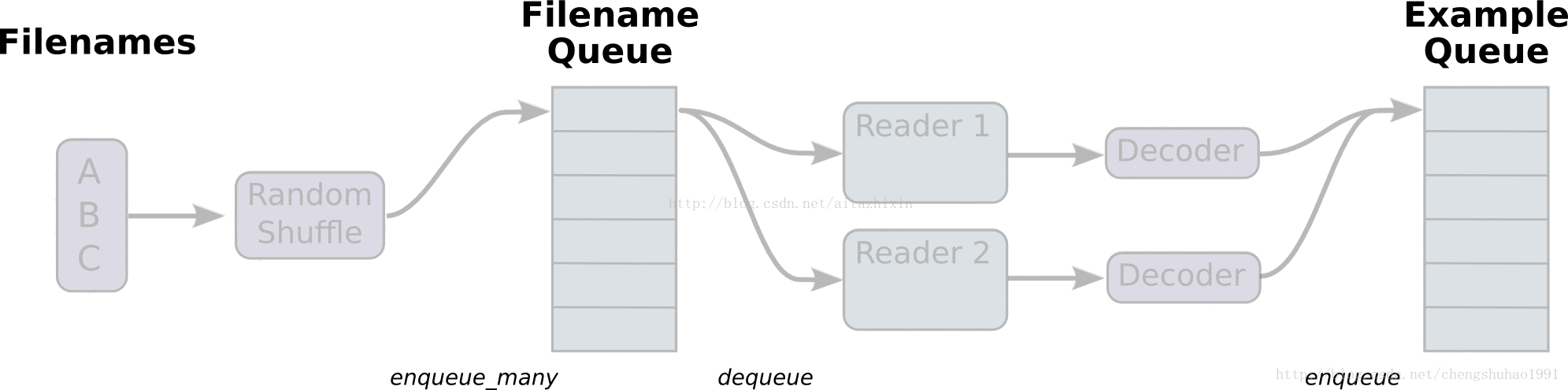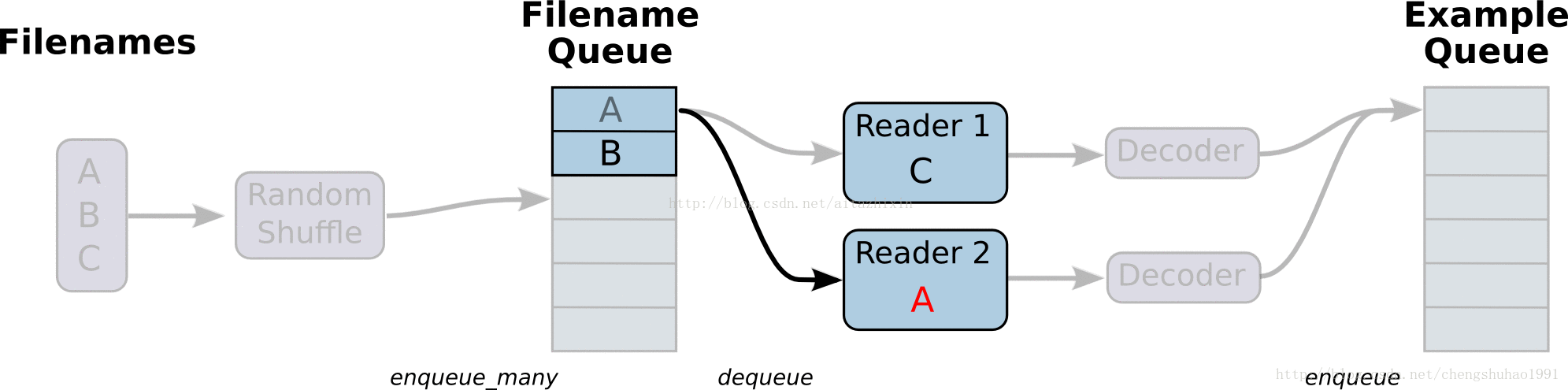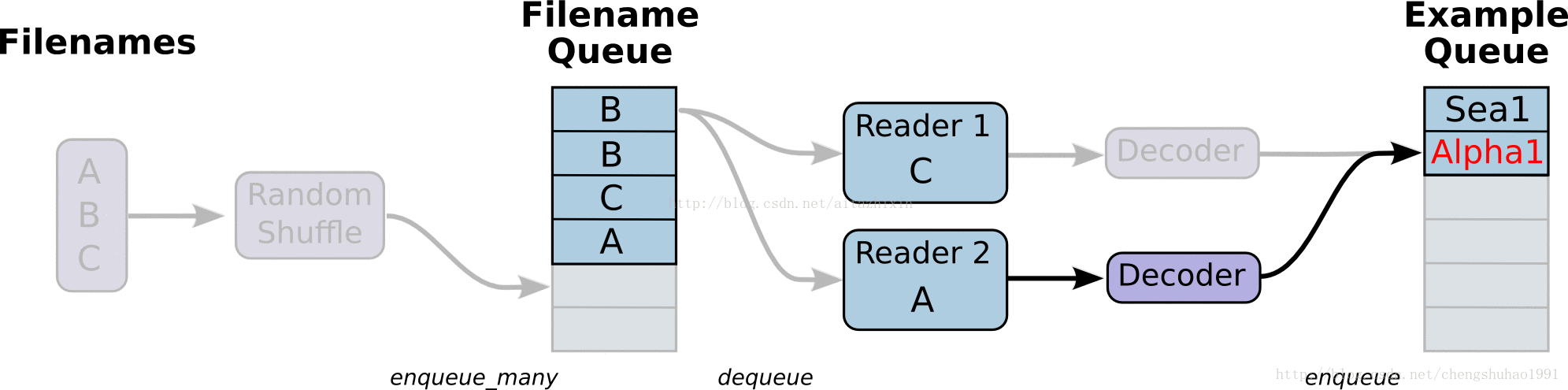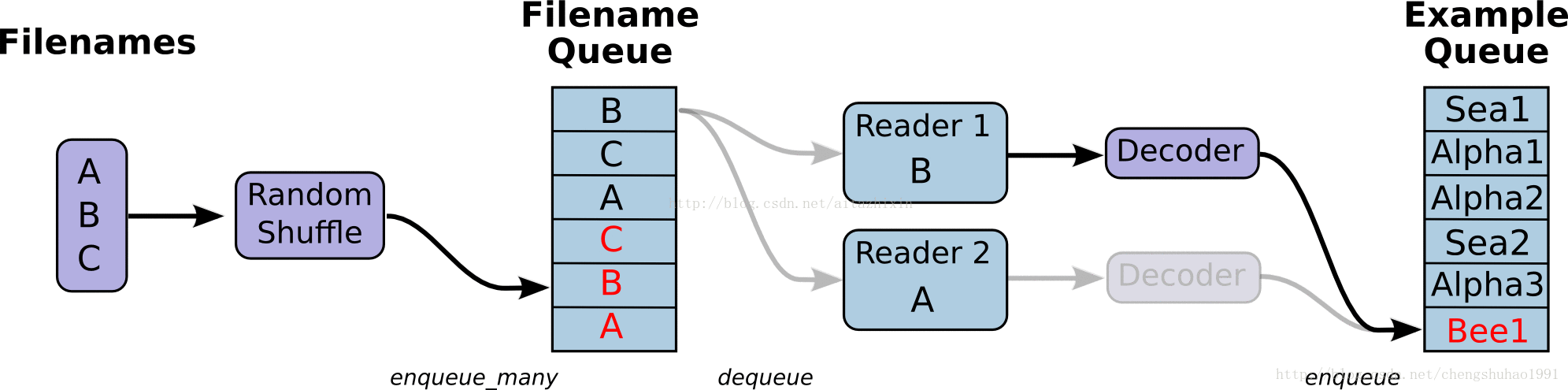
如上图所示,展示了文件读取的大致流程。
最左边的A、B、C是存储于磁盘中文件,经过打乱文件之后(这里是默认的乱序读取,只是文件的顺序乱,但是文件内容不受影响),进入到文件队列中(Filename Queue)。文件队列当中的文件经过阅读器(Reader)处理,存储到内存当中。接下来对文件进行解码(Decode),解码之后进入样本队列当中进行批处理,此时经过批处理之后就可以用于模型训练了。
现在举例,对于读取CSV文件,大致要经历一下几步:
1. 找到文件,并构造文件的列表(一阶张量)
2. 构造文件队列
3. 读取文件内容
4. 解码CSV并读取内容
5. 开启会话运行,得出训练结果
二.文件读取的API
1.文件队列构造
tf.train.string_inout_producer(string_tensor,num_epochs,shuffle=True)
- 将输出字符串(例如文件名)输入到管道队列
string_tensor:含有文件名的一阶张量,需要指定文件路径num_epochs:将全部数据循环的次数return:具有输出字符串的队列
2.文件阅读器
此时需要根据文件的格式,选择对应的文件阅读器
(1) 文本文件:tf.TextLineReader()
- 读取文本文件,逗号分隔值(CSV)格式,默认按行读取
- return:读取器实例
(2)二进制文件:tf.FixedLengthRecordReader(record_bytes)
- 读取每个记录是固定数量字节的二进制文件
- record_bytes:整型,指定每次读取的字节数
- return:读取器实例
(3)图片文件:tf.WholeReader()
- 将文件的全部内容作为值输出,即一次读取一整个文件
- return:读取器实例
(4)TFRecords文件:tf.TFRecordReader()
- 读取 TFRecords文件
- return:读取器实例
注:这几种文件格式都有一个共同的读取方法:read(file_queue)
- 从队列中指定内容数量
- file_name : 文件队列
- ruturn : 返回一个Tensor元组(key,value)
- key : 文件名
- value : 每次读取的值(一行文本、一张图片或指定字节的值)
3.文件内容解码器
由于从文件中读取的是字符串,需要函数去解析这些字符串,最后变换成张量
(1)CSV文件:
tf.decode_csv(records,record_defaults=None,field_delim=None,name=None)
- 将CSV文件转换成张量,需要
tf.TextLineReader()搭配使用 - records : tensor型字符串,每个字符串是CSV中的记录行(即value值)
- record_de
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1247
1247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









