






其实栈的顺序存储还是挺方便的,但是因为只允许栈顶进出数据,所以不存在线性表的插入和删除时需要移动元素的问题,不过他有一个很大的缺陷,就是必须事先确定存储的空间大小,万一不够用了,就需要通过编程手段来扩充数组的大小,非常麻烦,对于一个栈我们也只能尽快考虑周全,设计出大小合适的数组来处理,对于两个相同类型的栈,我们可以做到最大限度地利用事先开辟的存储空间来进行操作。---取自《大话数据结构》
为了解决上述的问题,我们可以新设计一个数据结构:
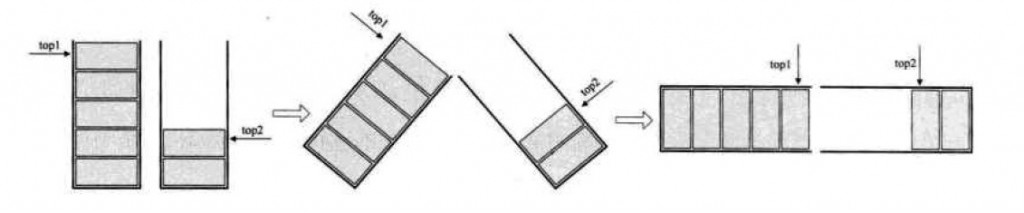
其中top1为第一个栈的栈顶指针,top2是第二个栈的栈顶指针。需要特别注意的是:第一个栈是从数组的最小端开始的(0),第二个栈是从数组的最大端开始(如果一个栈的最大容量是MAXSZIE,那么数组2就是从数组下标为MAXSIZE-1开始),这样的话呢,如果再将栈按照图2所示的方式进行变换成图3所示的话,就等效于对于一个数组(一定注意一点,在真正实现的时候,不是使用两个栈,把他们再合并,而是使用一个数组,只是让top指针按照之前所讲的规则指向而已,这个问题是我一开始学习时困扰了一会的问题,不得不说我的智商还是让人捉急的,相信很少会有人看不到这个问题吧)。
下面要确定一下,为空和满栈的条件。
我们假设top指针是指向栈顶元素,其实指向栈顶的下一个元素的思考方式都是一样的。因为在使用使用时判断满栈的情况,我们是采用的差值的办法,下面我将慢慢道来。
先说空栈:
因为我提前声明过,我们所使用的top指针是指向栈顶元素,在一开始为空栈时,没有元素。所以对于栈的第一部分,其初始值为top1 = -1;对于栈的第二部分,其初始值top2 = MAXSIZE;
上面这两个条件很容易理解,就不多做解释。
对于满栈:
如果第一部分满的话,我们很容易得出top1 = n-1,同理,如果第二部分满的话,top2 = MAXSIZE-n-2,但是如果整个栈都满的话,就是相当于两部分的栈顶元素相接处,即下标关系为top1+1 = top2.
现在我们定义一个两栈共享空间的数据结构代码
typedef struct {
ElementType data[MAXSIZE];
int top1;//栈1的栈顶指针
int top2;//栈2的栈顶指针
}SqlDoubleStack; 对于两栈共享空间的push方法,我们除了要插入元素值参数外,还需要有一个判断是栈1还是栈2的栈号参数stackNumber。插入元素的代码如下:
/*插入e到栈顶元素*/
/*
SqlDoubleStack *stack : 需要插入的共享栈空间
ElementType e :需要添加的元素数据
int stackNumber: 需要添加的栈的编号为1或者2
*/
Status push(SqlDoubleStack *stack, ElementType e, int stackNumber){
//先判断栈是否满了,如果栈满就无法再次压入栈中
if (isFilled(stack)) {
printf("栈满,无法再次添加数据");
return ERROR;
}
if (stackNumber == 1) {//将数据添加到栈1中
stack->data[++stack->top1] = e;
}
else {//否则将添加到栈2中
stack->data[--stack->top2] = e;
}
return TRUE;
}下面给出,判断栈满的代码:
/*判断栈是否满了*/
Status isFilled(SqlDoubleStack *stack){
if (stack->top1 + 1 == stack->top2){
return TRUE;
}
return FALSE;
}因为在之前我们已经判断了栈是否为满的情况,所以在后面的top1+1或者top2-1是不用担心溢出的问题
对于两栈共享空间的pop方法,参数就只是判断栈1和栈2的参数stackNumber,代码如下:
Status pop(SqlDoubleStack *stack, ElementType *e,int stackNumber) {
if (isEmpty(stack)) {
printf("栈为空,无法弹出数据!");
return ERROR;
}
if (stackNumber == 1) {
*e = stack->data[stack->top1--];
}
else {
*e = stack->data[stack->top2++];
}
return TRUE;
}两栈共享空间的存在意义:
如果只是单纯的需要一个栈功能,此时如果再使用两栈共享空间是不过提高任何的效率,因为这只是针对两个具有相同数据结构类型的栈的一个设计上的技巧,如果是不相同数据类型的栈,这种办法不但不能更好地处理问题,,反而会使问题变得更加复杂,大家要注意这个前提.















 2125
2125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









