







数据库的优化设计对以后web项目能否承担高并发所带来的巨大负担是个非常好的解决方案。主从同步和读写分离就是个常用的方法,主数据库用来写入数据,从数据库用来查询,分担了主数据库的一大部分工作,这样做的好处是当主服务器崩了之后,还是在从服务器上获取到数据,起到的备份的作用。
接下来说说如何实现数据库的主从同步和读写分离
看个人情况,可有三四台主机都没问题。本人现在是用2台服务器,实现2台服务器数据库的主从同步。
我把阿里云主机的数据库作为主数据库,腾讯云主机的数据库作为从数据库,两台主机的系统都是centos7,mariadb的版本为5.5.52
配置主数据库:
1.用vim打开my.cnf:
vim /etc/my.cnf2.在[mysqld]标签下面增加以下代码:
server-id=1 #主数据库的id
log-bin=master-bin #日志路径,作用是从数据库是根据这个日志来复制主数据库的数据的
3.停止mariadb服务
systemctl stop mariadb.service
grant replication slave on *.* to 'slaveuser'@'127.0.0.1' identified by 'slaveuser';flush privileges;
5.重启mariadb服务
systemctl restart mariadb.service配置从数据库
1.用vim打开my.cnf:
vim /etc/my.cnf2.在[mysqld]标签下面增加以下代码:
server-id=2 #这个id必须不能和主数据库相同
read-only=on #设置该数据库是只读状态
relay-log=relay-bin #日志
3.重启mariadb服务
systemctl restart mariadb.service
SHOW MASTER STATUS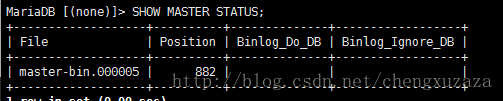
5.进入从服务器的数据库:master_host需改为自己的主服务器地址
change master to master_host='127.0.0.1',master_user='slaveuser',master_password='slaveuser', master_log_file='master-bin.000005',master_log_pos=882;6.启动slave同步(在数据库中)
START SLAVE;7. 在slave服务器上查看slave同步的状态
show slave status\G
8.查看Slave_IO_Running和Slave_SQL_Running是否都为yes(一定要全部为yes。否则就是你配置错了,再重新配置一遍从数据库)
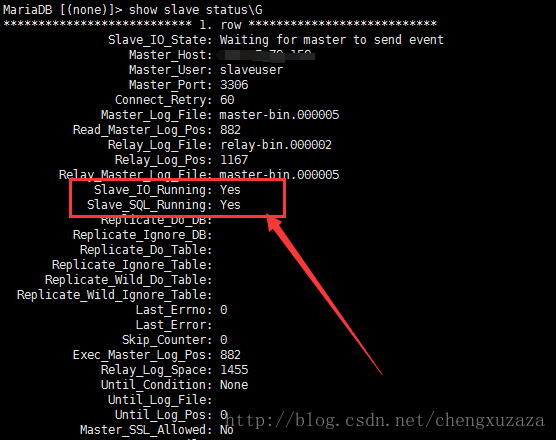
就这样,你可以在主数据库里创一个数据。然后再在从数据库里查看是否也有这个数据库。经本人测试是成功的。而且从数据库是不能够创建和插入数据的,因为设置成只读状态了。这样就实现了读写分离。在实际项目中,可以利用主数据库插入,更新数据,从数据用来查询数据。这样极大的减轻了数据库的负担。保障web项目的高可用性














 658
658











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









