






在spark stream程序中的一条关键的语句就是:ssc.start()
1,跟踪进入StreamingContext的start 方法,有一句非常关键的语句scheduler.start(),是个JobScheduler(spark stream用来job调度的)
进行job调度的入口!
2,计入JobScheduler 的start方法。
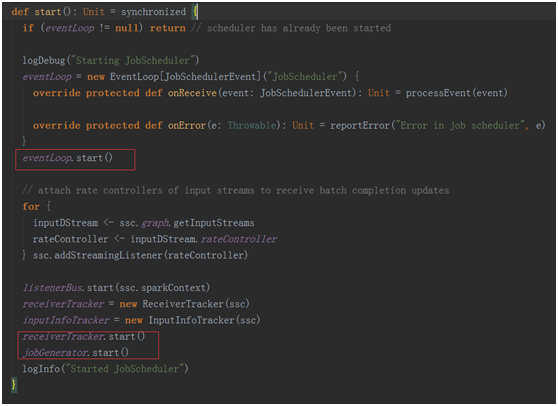
在这个方法中几个关键的点是:
eventLoop.start() 一个事件循环器,用于响应其它组件发来的事件(包括job的启动,完成,以及错误报告)。
 receiverTracker.start() 控制了整个receiver的生成,与数据的接受
receiverTracker.start() 控制了整个receiver的生成,与数据的接受
jobGenerator.start() 真正开始进行job的生成
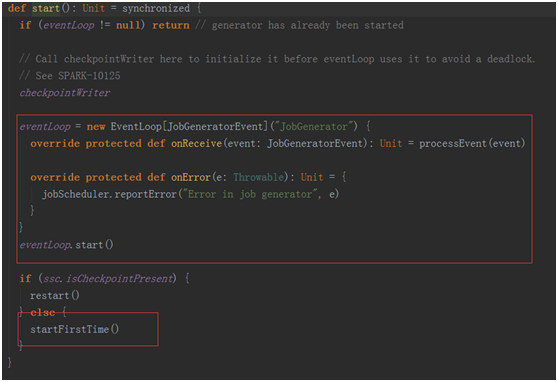 在这个方法中也维护了一个事件处理的循环器eventLoop,用于处理各种事件
在这个方法中也维护了一个事件处理的循环器eventLoop,用于处理各种事件
 其中最为关键的事件是GenerateJobs(time),这个事件是进行生成job的事件!!
其中最为关键的事件是GenerateJobs(time),这个事件是进行生成job的事件!!
跟踪计入generateJobs(time)

jobScheduler.receiverTracker.allocateBlocksToBatch(time) 为当前的bath分发收到的数据Blocks。
graph.generateJobs(time):根据当前编写的程序的output动作生成相应的job并封装进入集合中。

最终通过
![]() 提交作业到executor
提交作业到executor

在回去看看jobGenerator.start()中的startFirstTime()
private def startFirstTime() {
val startTime = new Time(timer.getStartTime())
graph.start(startTime - graph.batchDuration)
timer.start(startTime.milliseconds)
logInfo("Started JobGenerator at " + startTime)
}
第一次启动会启动一个定时器,该定时器会根基duration bath 不断的的给jobGenerator中的消息循环体!
在jobGenerator中的消息循环体就会不断的去除消息进行处理

















 1275
1275

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









