






https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Indexing
Overview of Hive Indexes
The goal of Hive indexing is to improve the speed of query lookup on certain columns of a table. Without an index, queries with predicates like 'WHERE tab1.col1 = 10' load the entire table or partition and process all the rows. But if an index exists for col1, then only a portion of the file needs to be loaded and processed.
The improvement in query speed that an index can provide comes at the cost of additional processing to create the index and disk space to store the index.
Create/build, show, and drop index:
CREATE INDEX table01_index ON TABLE table01 (column2) AS 'COMPACT'; SHOW INDEX ON table01; DROP INDEX table01_index ON table01;
Create then build, show formatted (with column names), and drop index:
CREATE INDEX table02_index ON TABLE table02 (column3) AS 'COMPACT' WITH DEFERRED REBUILD; ALTER INDEX table02_index ON table2 REBUILD; SHOW FORMATTED INDEX ON table02; DROP INDEX table02_index ON table02;
Create bitmap index, build, show, and drop:
CREATE INDEX table03_index ON TABLE table03 (column4) AS 'BITMAP' WITH DEFERRED REBUILD; ALTER INDEX table03_index ON table03 REBUILD; SHOW FORMATTED INDEX ON table03; DROP INDEX table03_index ON table03;
Create index in a new table:(可以把索引单独放到一个database中)
CREATE INDEX table04_index ON TABLE table04 (column5) AS 'COMPACT' WITH DEFERRED REBUILD IN TABLE table04_index_table;
Create index stored as RCFile:
CREATE INDEX table05_index ON TABLE table05 (column6) AS 'COMPACT' STORED AS RCFILE;
Create index stored as text file:
CREATE INDEX table06_index ON TABLE table06 (column7) AS 'COMPACT' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;
Create index with index properties:
CREATE INDEX table07_index ON TABLE table07 (column8) AS 'COMPACT' IDXPROPERTIES ("prop1"="value1", "prop2"="value2");
Create index with table properties:
CREATE INDEX table08_index ON TABLE table08 (column9) AS 'COMPACT' TBLPROPERTIES ("prop3"="value3", "prop4"="value4");
Drop index if exists:
DROP INDEX IF EXISTS table09_index ON table09;
Rebuild index on a partition:
ALTER INDEX table10_index ON table10 PARTITION (columnX='valueQ', columnY='valueR') REBUILD;
build index的时候会通过mapreduce来实现。
一个stus表(name,age)
k,1
w,4
l,1
对age建立索引,在warehouse中建立了索引目录。
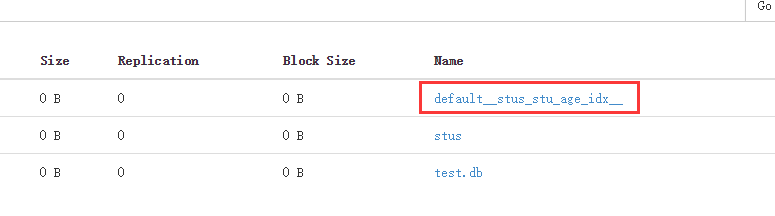
对应里面的目录

就是索引文件,会根据save不同类型,而产生不同的,默认是text的。
打开索引文件可以看到

记录了被索引对象的文件位置。这样就可以读取部分,实现减少map的功能。
随便根据age跑了一个group操作,索引前后对比如下
Map: 1 Reduce: 1 Cumulative CPU: 3.27 sec HDFS Read: 6694 HDFS Write: 8 SUCCESS
Map: 1 Reduce: 1 Cumulative CPU: 3.14 sec HDFS Read: 6715 HDFS Write: 8 SUCCESS
发现,虽然文件读取的更多了,但是时间更快了,数据集太少,效果可能也不是很明显。
索引文件,其实也是一个表,所以ROW FORMAT DELIMITED FIELDS,TORED AS RCFILE; 等都可以使用。
只不过所以索引文件格式是COMPACT还是BITMAP等,
















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









