







本博客(http://blog.csdn.net/livelylittlefish )贴出作者(阿波)相关研究、学习内容所做的笔记,欢迎广大朋友指正!
Content
1. trie基础
(1) 是什么?
(2) 性质
(3) 应用
(4) 优点
2. 一个例子
(1) 功能
(2) 代码
(3) 运行结果
(4) 分析
3. 一点点修改
(1) 分析
(2) 修改
(3) 代码
(4) 运行结果
(5) 分析
(6) 一个稍微复杂点的结果
4. 小结
1. trie基础
(1) 是什么?
Trie,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。
(2) 性质
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符都不相同
例如,单词序列a, to, tea, ted, ten, i, in, inn,对应的trie。
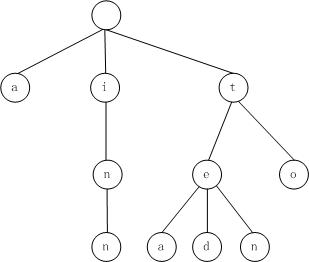
(3) 应用
用于统计和排序大量的字符串,但不仅限于字符串,所以经常被搜索引擎系统用于文本词频统计。
(4) 优点
- 最大限度地减少无谓的字符串比较
- 查询效率比哈希表高
2. 一个例子
该列子从中文wiki百科而来。
(1) 功能
从控制台输入字符串,每个字符串以回车结束,所有字符串的输入以'#'结束。程序统计输入的所有字符串中每种字符串的出现次数。
(2) 代码
一个实现了该功能的例子代码如下。
- /**
- * trie tree test
- * descriptioin: make statistics on every word for its frequency
- * usage: input some strings, each followed by a 'enter' character, and end with '#'
- */
- #include <stdio.h>
- #include <stdlib.h>
- #include <string.h>
- #define Max_Char_Number 256
- #define Max_Word_Len 128
- struct Trie_Node
- {
- int count_;
- struct Trie_Node *next_[Max_Char_Number];
- };
- static struct Trie_Node root= {0, {NULL}};
- static char *spaces=" /t/n/./"/'()";
- static int insert(const char *word)
- {
- int loop;
- struct Trie_Node *cur, *newnode;
- if (word[0] == '/0')
- return 0;
- cur = &root;
- for (loop=0; ; ++loop)
- {
- if (cur->next_[word[loop]] == NULL)
- {
- newnode=(struct Trie_Node*)malloc(sizeof(struct Trie_Node));
- memset(newnode, 0, sizeof(struct Trie_Node));
- cur->next_[word[loop]] = newnode;
- }
- if (word[loop] == '/0')
- break;
- cur = cur->next_[word[loop]];
- }
- cur->count_++;
- return 0;
- }
- void input()
- {
- char *linebuf = NULL, *line = NULL, *word = NULL;
- size_t bufsize=0;
- int ret;
- while (1)
- {
- ret=getline(&linebuf, &bufsize, stdin);
- if (ret==-1)
- break;
- line=linebuf;
- word = strsep(&line, spaces);
- /* input '#' will terminate this input */
- if (strcmp(word, "#") == 0)
- break;
- if (word[0]=='/0')
- continue;
- insert(word);
- }
- }
- static void printword(const char *str, int n)
- {
- printf("%s/t%d/n", str, n);
- }
- static int traverse(struct Trie_Node *rootp)
- {
- static char worddump[Max_Word_Len+1];
- static int pos=0;
- int i;
- if (rootp == NULL)
- return 0;
- if (rootp->count_)
- {
- worddump[pos]='/0';
- printword(worddump, rootp->count_);
- }
- for (i=0; i<Max_Char_Number; ++i)
- {
- worddump[pos++]=i;
- traverse(rootp->next_[i]); /* recursive call */
- pos--;
- }
- return 0;
- }
- void dump(struct Trie_Node* node)
- {
- static int depth = 0;
- static const char prefix[] = " ";
- int loop = 0;
- if (node == NULL)
- return;
- for (loop = 0; loop < Max_Char_Number; loop++)
- {
- if (node->next_[loop])
- {
- printf ("%.*s", (int) depth++, prefix);
- printf("next['%c'] = 0x%x, count = %d/n", loop, (unsigned int)(node->next_[loop]), node->next_[loop]->count_);
- dump(node->next_[loop]); /* recursive call */
- depth--;
- }
- }
- }
- int main(void)
- {
- input();
- printf("/n");
- traverse(&root);
- printf("/n");
- dump(&root);
- return 0;
- }
(3) 运行结果
# ./trie
a
to
tea
ted
ten
i
in
inn
#
a 1
i 1
in 1
inn 1
tea 1
ted 1
ten 1
to 1
next['a'] =0x88c1088, count = 1
next[''] = 0x88c1490, count = 0
next['i'] =0x88c40e8, count = 1
next[''] = 0x88c44f0, count = 0
next['n'] = 0x88c48f8, count = 1
next[''] = 0x88c4d00, count = 0
next['n'] = 0x88c5108, count = 1
next[''] = 0x88c5510, count = 0
next['t'] =0x88c1898, count = 0
next['e'] = 0x88c24b0, count = 0
next['a'] = 0x88c28b8, count = 1
next[''] = 0x88c2cc0, count = 0
next['d'] = 0x88c30c8, count = 1
next[''] = 0x88c34d0, count = 0
next['n'] = 0x88c38d8, count = 1
next[''] = 0x88c3ce0, count = 0
next['o'] = 0x88c1ca0, count = 1
next[''] = 0x88c20a8, count = 0
(4) 分析
在该程序中,笔者加入了dump函数,递归地打印出next数组中不为空的值,如下图所示。

加上次数,如下图。其中边(包括实边和虚边)上的数字即为next数组的下标,该数字即为该边所到节点字符的ASCII码。程序中使用字符本身,实际上是该字符的ASCII码,作为next数组下标,这样能够获得o(1)的访问效率,无需查找,直接访问。

由图直接看出,根节点的
next[97]出现的次数为1,即字符串"a"的次数;
next[105]的次数也为1,即字符串"i"的次数;
next[105]->next[110]出现的次数为1,即字符串"in"的次数;
next[105]->next[110]->next[110]出现的次数为1,即字符串"inn"的次数;
...
感觉怎样?是不是很直观呢?
——of course!
3. 一点点修改
(1) 分析
如上述例子,程序已经统计出next[105]->next[110]出现的次数为1,即字符串"in"的次数为1,为什么next[105]->next[110]->next[0]还有值呢?即next[0]这个指针实际上还指向一个节点,虽然该节点的值全为0。
如果被统计的字符串数量庞大,叶子节点数量庞大,或者如上图'i'这样的节点数量庞大,那么,空间的浪费也是很显然的,因为从程序中,我们知道,每个节点的大小sizeof(struct Trie_Node)=1028字节。如果,这样的节点有10000个,则浪费1028*10000字节,大约10M。
(2) 修改
调试上面的代码,发现insert函数,即向tire树中插入一个字符串时,for循环的退出条件可以修改,如下。
static int insert(const char *word)
{
int loop;
struct Trie_Node*cur, *newnode;
if (word[0] == '/0')
return 0;
cur = &root;
for (loop=0; ; ++loop)
{
if (word[loop] == '/0') /* the break condition should be here */
break;
if (cur- >next_[word[loop]] == NULL)
{
newnode=(struct Trie_Node*)malloc(sizeof(struct Trie_Node));
memset(newnode, 0, sizeof(struct Trie_Node));
cur- >next_[word[loop]] = newnode;
}
cur = cur- >next_[word[loop]];
}
cur- >count_++;
return 0;
}
(3) 代码
省略。
(4) 运行结果
# ./trie
a
to
tea
ted
ten
i
in
inn
#
a 1
i 1
in 1
inn 1
tea 1
ted 1
ten 1
to 1
next['a'] =0x8bb8088, count = 1
next['i'] =0x8bb9cc0, count = 1
next['n'] = 0x8bba0c8, count = 1
next['n'] = 0x8bba4d0, count = 1
next['t'] =0x8bb8490, count = 0
next['e'] = 0x8bb8ca0, count = 0
next['a'] = 0x8bb90a8, count = 1
next['d'] = 0x8bb94b0, count = 1
next['n'] = 0x8bb98b8, count = 1
next['o'] = 0x8bb8898, count = 1
(5) 分析
对比修改前后的运行结果发现,修改后的程序中不再含有next[0]的节点。如下图。

由上图也可直接看出,根节点的
next[97]出现的次数为1,即字符串"a"的次数;
next[105]的次数也为1,即字符串"i"的次数;
next[105]->next[110]出现的次数为1,即字符串"in"的次数;
next[105]->next[110]->next[110]出现的次数为1,即字符串"inn"的次数;
...
相比修改前的图,该图没有next[0]的垃圾数据,更直观。
(6) 一个稍微复杂点的结果
# ./trie
a
to
tea
ted
ten
i
in
inn
a
to
tea
ted
ten
i
in
inn
a
i
a
a
#
a 5
i 3
in 2
inn 2
tea 2
ted 2
ten 2
to 2
next['a'] =0x9604088, count = 5
next['i'] =0x9605cc0, count = 3
next['n'] = 0x96060c8, count = 2
next['n'] = 0x96064d0, count = 2
next['t'] =0x9604490, count = 0
next['e'] = 0x9604ca0, count = 0
next['a'] = 0x96050a8, count = 2
next['d'] = 0x96054b0, count = 2
next['n'] = 0x96058b8, count = 2
next['o'] = 0x9604898, count = 2
4. 小结
本文简单介绍了tire树的基本概念,并用一个例子说明其应用。
在设计程序时,可以使用一些小的技巧来提高程序效率,例如本文采用字符本身,即其ASCII码值,作为next数组下标,获得o(1)的访问效率。也要注意使用(循环)边界条件,消除垃圾数据。
reference
http://zh.wikipedia.org/wiki/Trie
http://en.wikipedia.org/wiki/Trie
http://en.wikipedia.org/wiki/Hash_trie
http://en.wikipedia.org/wiki/Hash_array_mapped_trie
http://www.topcoder.com/tc?module=Static&d1=tutorials&d2=usingTries















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









