







本文转自:http://blog.csdn.net/daliaojie/article/details/17965939
多并行度下Spout和Blot实体间Tuple的定向传输
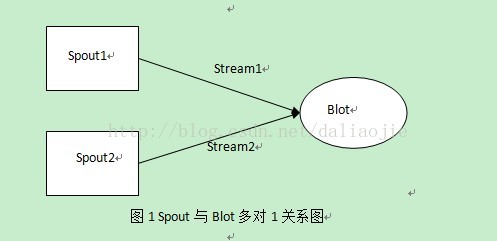
图1 Spout与Blot多对1关系图
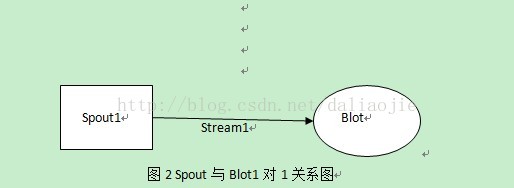
图2 Spout与Blot1对1关系图
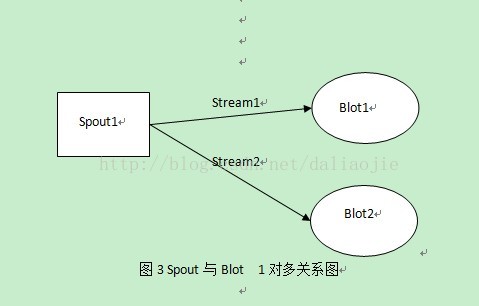
图3 Spout与Blot 1对多关系图
Topology中可以有多个Spout、Blot实体。若Spout和Blot为点,Stream为边,整个Topology可以看做是由Spout、 Blot和Stream组成的有向无环图。
图中Spout与Blot或者两个Blot之间有Stream维系的关系可以为一对一、多对一、一对多三种情况。
这三种情况中,只有在一对多这种情况需要,Tuple的传输方向不明确,所以进说明该情况下,Spout、Blot实体关系的建立方法。
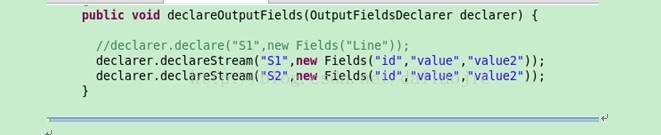
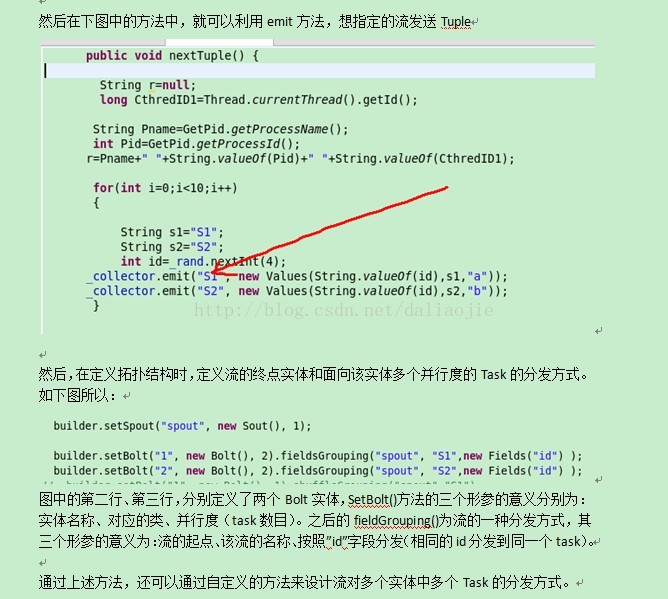
在Spout的类中,可以在下图方法中定义由该实体发出的流的名称和流中记录的结构。下图中,定义两个流,分别命名为S1和S2。














 3989
3989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









