






HashMap介绍
HashMap是基于hash表的Map接口的实现,使用key-value形式存储键值对的集合。
一、HashMap构造方法
-
HashMap():设置加载因子为默认值(0.75);
- HashMap(int initialCapacity):加载因子仍为默认值(0.75),参数initialCapacity表示自定义期望初始化表空间大小;
对象实例化时不会初始化表空间,初始化表空间在首次增加键值对时进行;
initialCapacity可能不是表空间实例化后的长度,实例化后的长度为大于等于initialCapacity的最小的2的次幂,用tableSizeFor方法实现,具体在下面介绍。
3. HashMap(int initialCapacity, float loadFactor):参数loadFactor表示自定义的加载因子,参数initialCapacity表示自定义期望初始化表空间大小,实际大小同2.;
4.HashMap(Map<? extends K, ? extends V> m):加载因子仍为默认值(0.75),如果比原Map集合大小除以默认加载因子的值的最小整数(>=(Map集合大小/默认加载因子)的最小整数),阈值(threshold)会重新设置,阈值为大于等于前面算出的整数最小的2的次幂。
二、tableSizeFor方法
此方法的作用是计算大于等于给定数字的最小2次幂,最大返回2的30次幂,源码如下:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}实现方法的证明:
假设入参减1得到的值,转换为二进制后为:0001XX···XXX,记最右边的数字处于第0位,记最左边的1为第m位,大于等于入参的最小2次幂就是2^(m+1)。
m最大30,0001XX···XXX中,1右边包括本身最多有31个数字:int最大值(2^31-1)减1,得到的值用二进制表示:11···110,前面30个1,最后一个0,所以m最大30。
方法中的第一行将入参减1是为了防止入参就是2的次幂,导致返回的值应是入参本身,但实际返回的值是入参的两倍。
由0001XX···XXX(1位于第m位)转换到00010XX···XXX(1位于第m+1位)的过程:
n |= n >>> 1 等价于 n = n | n >>> 1,0001XX···XXX | 0001XX···XXX>>>1 = 00011XX···XXX,这样就保证第m位向右紧邻的1位数字为1;
n |= n >>> 2 等价于 n = n | n >>> 2,00011XX···XXX | 00011XX···XXX>>>2 = 0001111XX···XXX,这样就保证第m位向右紧邻的(1+2)位数字为1;
n |= n >>> 4 等价于 n = n | n >>> 4,0001111XX···XXX | 0001111XX···XXX>>>4 = 00011111111XX···XXX,这样就保证第m位向右紧邻的(1+2+4)位数字为1;
同理,执行n |= n >>> 16后,第m位向右紧邻的(1+2+4+8+16)=31位数字为1,m最大30,故第m位右边已全部为1(000111···111(共m+1个1)),将结果加1后得到000100····0(最右边的0处于第0位,仅有的1处于第m+1位,转换成十进制为2^(m+1))。由于返回值为int,不会有2^31,故最大结果限制为2^30:
static final int MAXIMUM_CAPACITY = 1 << 30;数组的大小为什么是2的次幂?
为了能够使用位运算快速计算出元素的位置。数组的长度为2的次幂,数组的最大下标为2的次幂减一,转换为2进制就全部是1。将key的hashCode与最大下标进行与运算,可以快速得出该key除以最大下标的余数。
三、插入键值对(put方法)
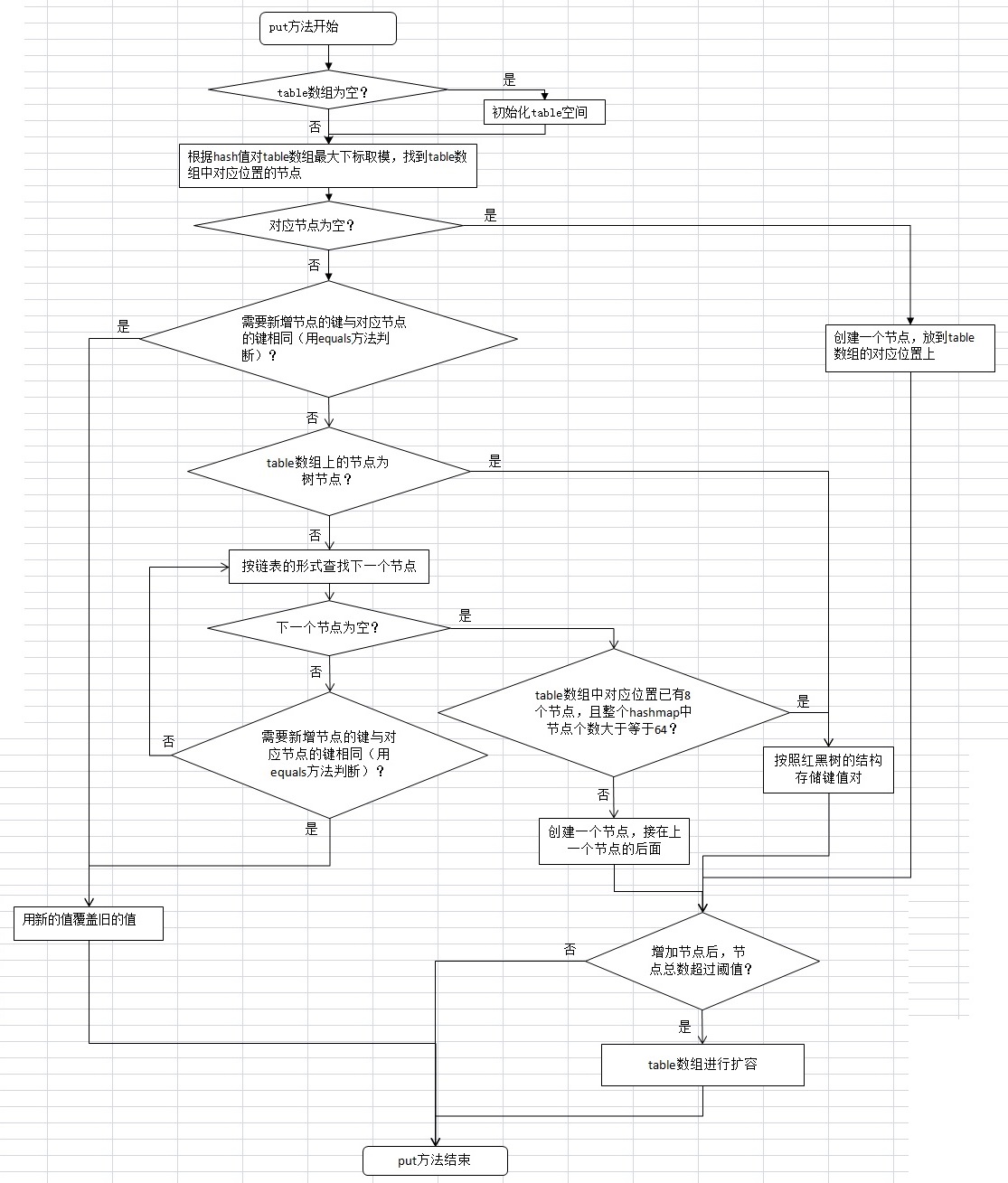
put方法源码及注释如下:
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//HashMap实例化时不会初始化table,table的初始化在首次插入键值对时进行
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//根据hash值对table数组最大下标取模,检查table中对应的位置是否为空,如果为空就新建一个Node节点
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//如果需要增加节点的键在table中已有(用equals判断),会将新节点的值覆盖旧节点的值(具体操作在下面的if (e != null)中)
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果该节点为树节点,则按红黑树的结构存储节点
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//hash碰撞,在table数组中对应位置节点后面继续查找
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//按链表的结构添加新的节点
p.next = newNode(hash, key, value, null);
//如果table中对应位置已有8个节点,且整个hashmap中节点个数已超过64(在treeifyBin()中判断),则转换为红黑树存储
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//在table数组中对应位置节点的链表中找到相同的键,就结束循环
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//节点个数是否大于阈值,如果大于则需要扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}put方法流程图:
所以Java8中HashMap的数据结构是 数组+链表+红黑树:
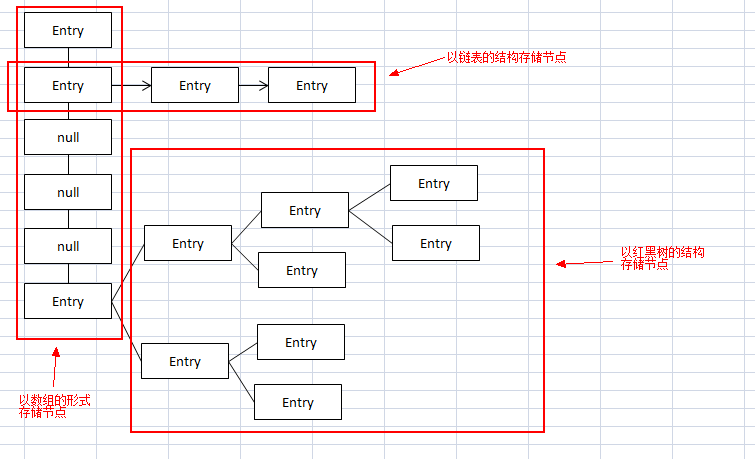
红黑树是一种二叉树,按中序遍历(红黑树的实现源码比较复杂,本人没有深入研究,只清楚这些~)
四、根据键获取值(get方法)
get方法源码及注释:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//先根据键的hash值找到在table数组中的位置
if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
//如果这个节点以树结构存储,则按树结构查找
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
//节点不是树结构,不断查找下一个节点,直到找出key的节点,或全部查找完该链表
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}- 先找到key的hash值对应table数组的位置;
- 如果该位置上的节点为树节点,就按照树结构进行查找;如果不为树节点,则不断查找下一个节点,直到找出key为输入参数的节点,或遍历完table数组这一位置链表上的所有节点。
五、扩容
当节点的个数大于阈值时,HashMap会扩容,扩容至原空间大小的两倍,同时阈值也会扩大(原阈值位运算左移一位:<< 1)。扩容后节点的位置重新分配。
六、线程安全
HashMap是线程不安全的。在高并发情况下,实现线程安全可以用ConcurrentHashMap或用Collections.synchronizedMap(map)包装一下,源码很简单,就是加了synchronized关键字,在此不多做介绍。
推荐使用ConcurrentHashMap。因为hashtab和Collections.synchronizedMap(map)将整个方法加了synchronized关键字,但ConcurrentHashMap只将方法中的一部分加了synchronized关键字,故ConcurrentHashMap效率较高。














 2882
2882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









