






栈
可以从 生活中 来举例, 比如 你家里一共有 10个人在吃饭, 吃完饭后 也就说至少有10个碗清洗和整理到碗橱(假设一个人一个碗,大小都一样.) 现在每清洗好后一个碗, 就依次叠在一起.
当下次只有你一个人在家吃饭时,你现在需要取一个碗来吃饭, 按照正常逻辑 你会从那碟碗上 取第一个.(从下面取或者从中间取都是不明智的) 这就是一个生活中 栈的例子.

从 程序设计 角度来谈谈,看下面的一段测试程序.
void testStack(int a,char b,int c) {
}
int main() {
testStack(2, 'b', 1); //研究下函数参数的入栈和出栈顺序
return 0;
}我们objdump -d这段程序,由于长度关系 只取出一部分..
<main>:
400489: ba 01 00 00 00 mov $0x1,%edx
40048e: be 61 00 00 00 mov $0x61,%esi
400493: bf 02 00 00 00 mov $0x2,%edi
<testStack>
400478: 89 7d fc mov %edi,-0x4(%rbp)
40047b: 89 f0 mov %esi,%eax
40047d: 89 55 f4 mov %edx,-0xc(%rbp)
400480: 88 45 f8 mov %al,-0x8(%rbp)
从汇编代码可以看出 ,分别把$0x1,$0x61,$0x2 三个立即数存入不同的寄存器中,然后再通过寄存器传参,可以看出 由于栈是由高到低(栈底->栈顶), 所以入栈的顺序为 1, 'b', 2
低 400478 %edi,-0x4(%rbp) 2 栈顶
40047b $0x61,%esi 'b'
高 40047d %edx,-0xc(%rbp) 1 栈底说到这,函数参数从右往左入栈好处是 由于出栈是先pop最左边的 也就是离函数名最近的.所以每次取参数就很方便.
深入认识栈
栈可以说是一个残缺的线性表, 因为元素的添加和删除都是在一端进行的.都遵循着 "后进先出" (LIFO) ,跟上文说的碗一样 ,最后的放的碗总是先被使用.
来看下栈的图示结构.
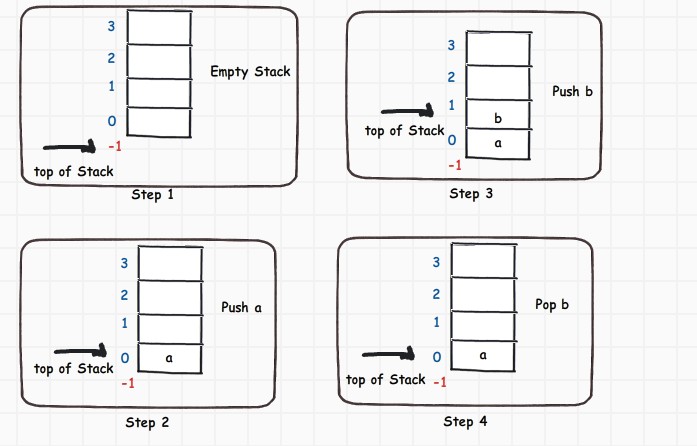
通过图示可以大概看出两种操作 Push 和 Pop 也就是 入栈 和 出栈.Step 1 开始初始化为一个空栈,Step 2 ,向栈中压入一个值 a, Step 3继续压栈 b ,Step 4中进行 Pop b.只剩下 a. 逻辑比较简单.很容易懂.
程序设计时,可以使用Array 和 List 两种数据结构来实现, Array实现的 为 顺序栈 ,它在内存中为连续存放的,List实现的为链式栈,随机存放.
顺序栈:
实现原理: 使用一个数组 vessel 和 大小 size, 每次push前 先判断 vessel的大小是否小于 size ,如果小于则进行入栈操作, 每次Pop前 先检查 vessel的大小是否为 0 如果不为0 则进行Pop操作.
设计类如下:
template <class T>
class StackArray {
int size;
int tos; /**< 索引 */
T* vessel;
public:
StackArray(int s);
void Push(T& elm);
T& Pop();
};
/* --- 构造函数 --- */
template <class T>
StackArray<T>::StackArray(int s) {
size = s;
tos = -1;
vessel = new T[s];
}
Push操作实现:
template <class T>
void StackArray<T>::Push(T& elm) {
if (tos == size-1) { return; } /**< 判断栈是否满 */
vessel[tos++] = elm;
}
Pop操作实现:
template <class T>
T& StackArray<T>::Pop() {
if (tos == -1) { return; } /**< 判断栈是否为空 */
return vessel[tos--];
}链式栈
实现原理:顺序栈是个效率很高的实现方法,但是对内存利用很不灵活,所以可以进一步使用链式来进行内存管理,利用设计链表的方法,先设计出链式栈节点类 ,然后在设计出 链式栈类. 链式栈节点类 , 需要 保存数据 和 指向下一个节点的指针 两个成员变量.
template <class T>
class StackLinkNode {
T data;
StackLinkNode<T>* link;
StackLinkNode(T& value):data(value),link(NULL){}
};
链式栈设计 和 顺序栈不同,不需要容器来保存 只需要一个 栈顶指针.
template <class T>
class StackLink {
StackLinkNode<T>* tos;
public:
StackLink():tos(NULL){}
void Push(T& value);
T& Pop();
};
template <class T>
void StackLink<T>::Push(T& value) {
StackLinkNode<T>* node = new StackLinkNode<T>(value);
node->link = tos; /**< 新创建的结点指向栈顶结点 */
tos = node; /**< tos++ 指向新添加的节点 */
}

Pop操作如下:
template <class T>
void StackLink<T>::Pop() {
StackLinkNode<T>* old = tos;
tos = tos->link; /**< 向栈底移动 */
T data = old->data; /**< 保存原栈顶元素 */
delete old;
return data;
}如图:

实现Pop时需要注意 资源释放问题. 所以需要个临时的来进行保存.
其它知识点:
由于栈操作是常数时间,所以影响一个栈的执行效率是在冗长的错误检测上,比如链式栈, 但是忽略错误检测是不行的, 我们应该尽量把冗长错误检测进行重新整理. 使其尽可能的高效率.
原文链接: http://blog.csdn.net/crazyjixiang/article/details/6755430















 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









