







优化器分类
传统关系型数据库里面的优化器分为CBO和RBO。
RBO— Rule_Based Potimizer 基于规则的优化器:( 内置规则)
RBO :RBO所用的判断规则是一组内置的规则,这些规则是硬编码在数据库的编码中的,RBO会根据这些规则去从SQL诸多的路径中来选择一条作为执行计划(比如在RBO里面,有这么一条规则:有索引使用索引。那么所有带有索引的表在任何情况下都会走索引)所以,RBO现在被很多数据库抛弃(oracle默认是CBO,但是仍然保留RBO代码,MySQL只有CBO)
RBO最大问题在于硬编码在数据库里面的一系列固定规则,来决定执行计划。并没有考虑目标SQL中所涉及的对象的实际数量,实际数据的分布情况,这样一旦规则不适用于该SQL,那么很可能选出来的执行计划就不是最优执行计划了。
CBO—Cost_Based Potimizer 基于成本的优化器: 多个执行路径,选择成本最小的一个
CBO :CBO在会从目标诸多的执行路径中选择一个成本最小的执行路径来作为执行计划。这里的成本实际代表了MySQL根据相关统计信息计算出来目标SQL执行对应的步骤的IO,CPU等消耗。也就是意味着数据库里的成本实际上就是对于执行目标SQL所需要IO,CPU等资源的一个估计值。而成本值是根据索引,表,行的统计信息计算出来的。(计算过程比较复杂)
经典案例:
CREATE TABLE `test` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(191) COLLATE utf8mb4_unicode_ci NOT NULL,
`display_name` varchar(191) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `index_display_name` (`display_name`),
KEY `index_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci插入数据
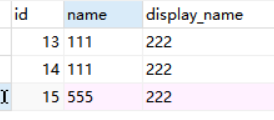
explain select * from test where name='111' and display_name='222'当前sql走了name索引,没有走display_name索引,为什么?
因为name命中的比较少,只有两行,排除四行数据;diplay_name命中的比较多,命中三行,只排除了三行数据。查询优化器会寻找较少的计算也就是name字段索引.
修改后:
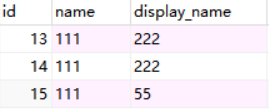
通过查看执行计划,mysql将会走diplay_name索引,因为命中的行数比较少。
但是如果name列有三行111,display_name有三行是222,索引该怎么执行呢?或者说执行下面的sql,应用了哪条索引呢?
select * from test where name='444' and display_name='555‘’ ???
Mysql查询优化器
查询优化器为我们做了哪些工作,我们怎么做,才能使查询优化器对我们的sql进行优化,以及启示我们sql语句怎么写,才能更有效率。
1、常量转化
它能够对sql语句中的常量进行转化,比如下面的表达式: WHERE col1 = col2 AND col2 = 'x'; 依据传递性:如果A=B and B=C,那么就能得出A=C。所以上面的表达式mysql查询优化器能进行如下的优化:WHERE col1 = 'x' AND col2 = 'x'; 对于col1 col2,只要是属于下面的操作符之一就可以进行类似的转化: =,<,>,<=,>=,<>,<=>,LIKE。
存取类型为常量时,性能更好。
2、无效代码的排除
查询优化器会对一些无用的条件进行过滤,比如说WHERE 0=0 AND column1='y'因为第一个条件是始终为true的,所以可以移除该条件,变为:WHERE column1='y'再见如下表达式:WHERE (0=1 AND s1=5) OR s1=7因为前一个括号内的表达式始终为false,因此可以移除该表达式,变为:WHERE s1=7。
3、常量计算
如下表达式:WHERE col1 = 1 + 2转化为:WHERE col1 = 3,Mysql会对常量表达进行计算,然后将计算结果生成查询条件。
4、存取类型(执行路径)
每个sql执行只能走一个索引。
当我们评估一个条件表达式,MySQL判断该表达式的存取类型。
优化器根据存取类型选择合适的驱动表达式。考虑如下的查询语句:以下是引用片段:
SELECT * FROM Table1 WHERE indexed_column=5 AND unindexed_column=6。因为indexed_column拥有更好的存取类型,所以更有可能使用该表达式做为驱动表达式。这里只考虑简单的情况,不考虑特殊的情况。那么驱动表达式的意思是什么呢?考虑到这个查询语句有两种可能的执行方法:
1) 不好的执行路径:读取表的每一行(称为“全表扫描”),对于读取到的每一行,检查相应的值是否满足indexed_column以及 unindexed_column对应的条件。
2) 好的执行路径:通过键值indexed_column=5查找B树,对于符合该条件的每一行,判断是否满足unindexed_column对应的条件。
一般情况下,索引查找比全表扫描需要更少的存取路径,尤其当表数据量很大,并且索引的类型是UNIQUE的时候。因此称它为好的执行路径,使用indexed_column列作为驱动表达式。
5、范围存取类型
一些表达式可以使用索引,但是属于索引的范围查找。这些表达式通常对应的操作符是:>、>=、<、<=、IN、LIKE、 BETWEEN。
优化器将会对下面的表达式使用索引范围查找:column1 LIKE 'x%',但对下面的表达式就不会使用到索引了:column1 LIKE '%x',这是因为当首字符是通配符的时候, 没办法使用到索引进行范围查找。
6、AND
带AND的查询的格式为:AND ,考虑如下的查询语句:WHERE column1='x' AND column2='y'
优化的步骤:
1)如果两个列都没有索引,那么使用全表扫描。
2)否则,如果其中一个列拥有更好的存取类型(比如,一个具有索引,另外一个没有索引;再或者,一个是唯一索引,另外一个是非唯一索引),那么使用该列作为驱动表达式。
7、ORDER BY 排序非常消耗性能资源;索引是排好序的,要排序的字段尽量走索引。
一般而言,ORDER BY的作用是使结果集按照一定的顺序排序,如果可以不经过此操作就能产生顺序的结果,可以跳过该ORDER BY操作。考虑如下的查询语句:
SELECT column1 FROM Table1 ORDER BY 'x';优化器将去除该 ORDER BY子句,因为此处的ORDER BY子句没有意义。
再考虑另外的一个查询语句:SELECT column1 FROM Table1 ORDER BY column1;
在这种情况下,如果column1类上存在索引,优化器将使用该索引进行全扫描,这样产生的结果集是有序的,从而不需要进行ORDER BY操作。
再考虑另外的一个查询语句:SELECT column1 FROM Table1 ORDER BY column1+1(存在计算条件 不走索引;把列的值加1再进行排序); 假设column1上存在索引,我们也许会觉得优化器会对column1索引进行全扫描,并且不进行ORDER BY操作。实际上,情况并不是这样,优化器是使用column1列上的索引进行全扫表,仅仅是因为索引全扫描的效率高于表全扫描。对于索引全扫描的结果集 仍然进行ORDER BY排序操作。
where执行顺序是从左往右执行的,遵守原则:排除越多数据的条件放在第一个。带AND的查询,把有索引的列放在前面,否则会索引失效。
范围查询使用了索引。
浪费了我一个小时的时间,navicat默认只查询一千条,其他数据要右下角进行查询下一页。
每个叶子节点分别包含索引键值和一个指向对应数据记录物理地址的指针。
索引可以避免再次排序操作。
存取路径,范围存取路径,索引存取路径。
建立的索引是否合理?优化器根本搞不清楚你要使用哪个索引,所以,尽量避免相同的前缀的索引。
尽量减少列上的运算,而将运算放到常量上.
解决方案:
1)查看执行计划,是否使用索引。
2)连接查询变成单表查询。
3)使用show profile命令分析sql性能。
SELECT r.id, r.role_code AS roleCode, r.role_name AS roleName
FROM permission_doctor_role dr
JOIN permission_role r ON dr.role_id = r.id
WHERE dr.doctor_id = ?
AND dr.hospital_id = ?
AND dr.delete_flag = ?-- 如何查看sql的执行时间?
-- 信息面板:受影响的行;前sql的执行消耗的时间。
-- 如何查看sql的执行计划?
explain select * from permission_doctor_role dr where dr.doctor_id=123628099 AND dr.hospital_id=439500 and dr.delete_flag=1;
-- 如何查看sql的索引情况?
-- 共有多少索引? 单值索引还是复合索引?
-- 如果有多个查询条件,应该使用复合索引,但是复合索引不能创建过多
show index from permission_doctor_role
-- 如何查看sql执行过程中的资源消耗情况?
-- show profile cpu,block,io for query 上一步问题SQL的数字号码
show profiles
show profile cpu,block io for query 467
-- 如何创建复合索引?删除索引,展示所有的索引
create index index_permission_doctor_role_doctor_hospital_delete on permission_doctor_role(doctor_id,hospital_id,delete_flag);
drop index idx_permission_doctor_role_id_doctor_hospital on permission_doctor_role
show index from permission_doctor_role
-- 如何修改表结构,增加字段,考虑到数据类型、默认值
-- 实际需求:如何给p_doctor表添加两个字段记录用户来源。
alter table permission_doctor_role add p_test1 VARCHAR(15) DEFAULT 'crs';
select * from permission_doctor_role limit 10
-- 如何删除字段
alter table permission_doctor_role drop column p_test1














 1512
1512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









