





ConcurrentHashMap底层是怎样的结构?
1、ConcurrentHashMap类的结构
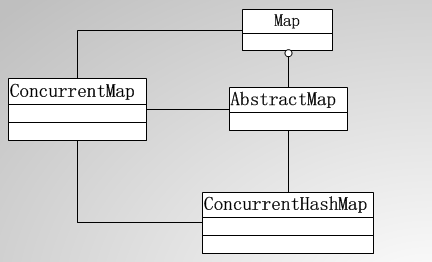

 本文详细解析了ConcurrentHashMap的内部结构与实现机制,探讨其如何在多线程环境下高效进行并发操作,为读者提供了深入理解Java并发容器的基础。
本文详细解析了ConcurrentHashMap的内部结构与实现机制,探讨其如何在多线程环境下高效进行并发操作,为读者提供了深入理解Java并发容器的基础。
1、ConcurrentHashMap类的结构
转载于:https://my.oschina.net/u/2423525/blog/750820
 2323
2323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























