






https://my.oschina.net/ydsakyclguozi/blog/404625 出处不明了。
- 显示最新的项目列表
- 删除与过滤
- 排行榜相关
- 按照用户投票和时间排序
- 处理过期项目
- 计数
- 特定时间内的特定项目
- 实时分析正在发生的情况,用于数据统计与防止垃圾邮件等
- Pub/Sub
- 队列
- 缓存
一、Mysql+Memcached架构的问题
实际上MySQL是适合进行海量数据存储的,通过Memcached将热点数据加载到cache,加速访问,很多公司都曾使用过这样的架构,但随着业务数据量的不断增加,和访问量的持续增长,我们遇到了很多问题:
- MySQL需要不断进行拆库分表,memcached也需要不断跟着扩容,扩容和维护工作占据大量开发时间。
- Memcached数据与MySQL数据库一致性的问题
- Memcached数据命中率低或down机,大量访问直接穿透DB,MySQL无法支撑。
- 跨机房cache同步问题。
众多NoSQL百花齐放,如何选择?
最近几年,页面不断涌现出很多各种各样的NoSQL产品,那么如何才能正确地使用好这些产品,最大化地发挥其长处,使我们需要深入研究和思考的问题,实际归根结底最重要的是了解这些产品定位,并且了解每款产品的tradeoffs,在实际应用中做到扬长避短,总体上这些NoSQL主要用于解决以下几种问题
- 少量数据存储,高速读写访问。此类产品通过数据全部in-memery的方式来保证高速访问,同时提供数据落地的功能,实际这真实Redis最主要的使用场景。
- 海量数据存储,分布式系统支持,数据一致性保证,方便的集群节点添加/删除
Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家会有疑问,似乎Redis更像一个加强版的Memcached,那么何时使用Memcached,何时使用Redis呢?
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
- Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储
- Redis支持数据的备份,即master-slave模式的数据备份。
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
二、Redis常用数据类型
- String
- Hash
- List
- Set
- Sorted Set
- Pub/Sub
- Transactions
在具体描述这几种数据类型之前,我们先通过一张图了解下Redis内部内存管理中是如何描述这些不同的数据类型:
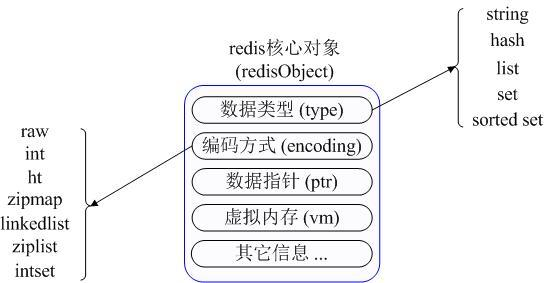
三、各种数据类型应用和实现方式
四、Redis实际应用场景
1.显示最新的项目列表
下面这个语句常用显示最近项目,随着数据多了,查询毫无疑问会越来越慢。
SELECT * FROM FOO WHERE ...ORDER BY time DESC LIMIT 10在WEB应用中,“列出最新的回复”之类的查询非常普遍,这通常会带来扩展性问题。这令人沮丧,因为项目本来就是按照这个顺序被创建的,但要输入这个顺序却不得不进行排序。
类似的问题就可以用Redis来解决。比如说,我们的一个web应用想要列出用户贴出的最新20条评论。在最新的评论边上我们有一个“显示全部”链接,点击后就可以获取更多的评论。
我们假设数据库中的每条评论都有一个唯一的递增的ID字段。
我们可以使用分页来制作主页和评论页,使用Redis模板,每次新评论发表时,我们会将它的ID添加到一个Redis列表:LPUSH latest.comments<ID>
我们将列表裁剪为指定长度,因此Redis只需保存最新的5000条评论:LTRIM latest.comments 0 5000
每次我们需要获取最新评论项目范围时,我们调用一个函数来完成(使用伪代码):
function get_latest_comments(start, num_items) {
id_list = redis.lrange("latest.comments",start,start_item-1);
IF id_list.length < num_items
id_list = SQL_DB("SELECT...ORDER BY time LIMIT...")
END
RETURN id_list
}这里我们做得很简单。在Redis中我们的最新ID使用了常驻缓存,这是一直更新的。但是我们做了限制不能超过5000个ID,因此我们的获取ID函数会一直询问Redis。只有在start/count参数超出了这个范围的时候,才需要去访问数据库。
我们的系统不会像传统方式那样“刷新”缓存,Redis实例中的信息永远是一致的。SQL数据库只是在用户需要获取“很远”的数据才会触发。而主页或第一个评论页是不会麻烦到硬盘上的数据库了。
2.删除和过滤
我们可以使用LREN来删除评论。如果删除操作非常少,另一个选择是直接跳过评论条目的入口,报告说改评论已经不存在。
有些时候你想要给不同的列表附加上不同的过滤器。如果过滤器的数量受到限制,你可以简单的为每个不同的过滤器使用不同的Redis列表。毕竟每个列表只有5000条项目,但Redis却能够使用非常少的内存来处理几百万条项目。
3.排行榜相关
另一个很普遍的需求是各种数据库的数据并非存储在内存中,因此在按得分排序以及实时更新这些几乎每秒钟都需要更新的功能上数据库的性能不够理想。
典型的,比如那些在线游戏的排行榜,比如
4.按照用户投票和时间排序
5 .处理过期项目
6.计数
7.特定时间内的特定项目
8.实时分析正在发生的情况,用于数据统计与防止垃圾邮件等
9.Pub/Sub
10.队列
11.缓存















 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









