






一、JAVA基础
继承、抽象类与接口区别、访问控制(private default protected public)、多态相关
1.interface和abstract class的区别
1)语法层次:抽象类中方式中,抽象类可以拥有任意范围的成员数据,同时也可以拥有自己的非抽象方法。凡是接口方式中,它仅能够有静态、不能修改的成员数据(但是我们一般是不会在接口中使用成员数据),同时它所有的方法都必须是抽象的。在某种程度上来说,接口是抽象的特殊化。
2)设计层次:从设计理念的角度来看,他们存在如下三个不点:a.抽象层级不同。抽象类是对类抽象,而接口是对行为的抽象。b.跨域不同。抽象类所跨域的是具有相似特点的类,而接口却可以跨域不同的类。c.设计层次不同。抽象类而言,它是自下而上进行设计的,我们要知道子类才能抽象出父类,而接口不同,它根本不需要知道子类的存在,只需要定义一个规则即可,至于子类不需要知道。
2.是否可以继承多个接口,是否可以继承多个抽象类
java可以实现多个接口,对于类是单继承体系结构。
3.Static Nested Class 和Inner Class的不同
静态内部类没有了指向外部的引用,可以直接被实例化而不需要依附与外部类的实例化。
非静态内部类保留了指向外部的引用,必须依附于外部类的实例化才能实例化内部类。
4.Overload和Override的区别。Overload的方法是否可以改变返回值的类型?
overload是一个类多态性的表现,override是父类与子类之间多态性的不同不限。
overload:方法相同,方法签名不同。
override:子类中定义与父类相同的名称及签名。
注意:不能通过访问权限、返回类型、抛出的异常进行重载
5.abstract的method是否可以同时是static,是否同时是native,是否同时是synchronized
static修饰的方法不能被重写。
6.是否可以继承String类
String类是final修饰的类,所以不能继承,
7.构造器是否可以被重写?
构造器不能被继承,所以也不能够被重写。
8.final,finally,finalize的区别
1)final关键字可以用于类、方法、变量前,用来表示该关键字修饰的类、方法、变量具有不可变的特性。
a.final关键字用于基本数据类型前:这时表明该关键字修饰的变量是一个常量,在定义后该变量的值就不能被修改。
b.final关键字用于方法声明前:这时意味着该方法是最终的方法,只能被调用,不能被覆盖,但是可以被重载。
c.final关键字用于类名前:此时该类被称为最终类,该类不能被其他类继承。
2)finally:当一个代码抛出一个异常时,就会终止方法中剩余代码的处理,并退出这个方法的执行。假如我们打开了一个文件,但是在处理文件过程中发生异常,这时文件还没被关闭,此时就会产生资源回收问题。对此,java提供了一种好的解决方案,那就是finally子句,finally子句的语句是一定会被执行的,所以我们只要把前面说的文件关闭的语句放在finally子句中,无论在读写文件中是否遇到异常退出,文件关闭语句都会执行,保证了资源的合理回收。
3)finalize方法来自于java.lang.Object,用于回收资源。可以为任何一个类添加finalize方法。finalize方法将在垃圾回收器清楚对象之前调用。在实际应用中,不要依赖使用方法回收任何短缺的资源,这是因为很难知道这个方法在什么时候被调用。
9.int和Integer有什么区别
Integer是int的包装类,int的初始值是0,Integer的初始值为null.
无论如何,Integer与new Integer()不会相等。不会经历拆箱过程,new出来的对象存放在堆,而非new的Integer常量则再常量池(方法区),他们的内存地址不一样。
两个都是非new出来的Integer,如果数在-128到127之间,则是true,否则为false。java在编译Integer i2 = 128的时候,被翻译成-》Integer i = Integer.valueOf(128);而valueOf()函数会对-128到127之间的数进行缓存。
两个都是new出来的Integer比较,都为false
int和Integer比,都为ture,因为会把Integer自动拆箱为int再去比。
Collection相关的数据结构及API
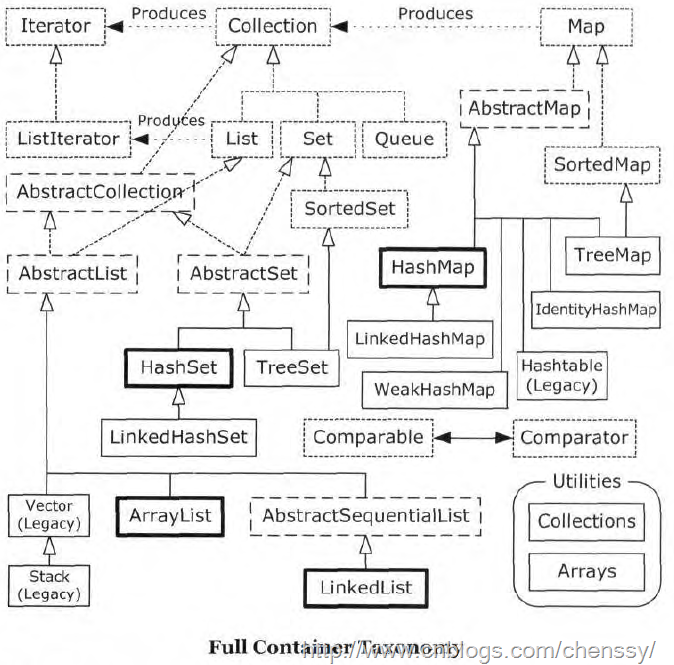
1.列举几个Java Collection类库中常用的类
Collection是java.util 中的一个借口,继承自Iterable。
子接口:List,Set,Queue
实现类:ArrayList,LinkedList、HashSet、TreeSet、Vector、Stack
其他相关的类:Iterator、TreeMap、HashTable、HashMap
Collection接口是最基本的集合接口,它不直接提供实现。
2.List、Set、Map是否都继承自Collection接口
List,Set继承自Collection接口,而Map不是。
1)List所代表的是有序的Collection。实现List接口的集合有:ArrayList,LinkedList,Vector,Stack
2)Set是一种不包括重复元素的Collection。实现Set接口的集合有:EnumSet,HashSet,TreeSet。
3)Map与List、Set集合不同,它是由一系列键值对组成的集合,提供了key到value的映射。同时它也没有继承Collection.实现Map的有:HashMap,TreeMap,HashTable,EnumMap。
3.HashMap和HashTable的区别
1)HashMap是非线程安全的,HashTables是线程安全的,在方法的前面都有synchronized来同步。
2)HashMap的键和值都允许有null值存在,而HashTable则不行。
3)因为线程安全的问题,HashMap效率比HashTable的要高。
4)HashTable有一个contains(Object value)功能和containsValue(Object value)功能一样。
5)HashTable的hash数组默认大小是11,增加的方式是old*2+1.HashMap中hash数值的默认大小是16,而且一定是2的指数。
6)hash值的使用不同,HashTable直接使用对象的hashCode:
int hash = key.hashCode();
int index = (hash&0x7FFFFFF)%tab.length;而HashMap是重新计算hash的值,而已用以代替求模:
int hash = hash(k);
int i = indexFor(hash,table.length);
private static int hash(Object k){
h ^ = (h >>>20) ^ (h >>>12);
return h ^ (h >>> 7) ^ (h >>> 4);
}HashMap和ConcurrentHashMap的关系
ConcurrentHashMap是线程安全的HashMap的实现。同样是线程安全的类,它与HashTable在同步方面有什么不同呢?他和HashTable也是有区别的,主要区别就是加锁的粒度以及如何加锁,ConcurrentHashMap 的加锁粒度要比HashTable更细一点。将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
4.HashMap中是否任何对象都可以做为key,用户自定义对象做为key有没有什么要求?
用户自定义的对象当作key需要实现Map中的hashCode和Equals方法。
HashMap用可以的哈希值来存储和查找键值对,当插入一个Entry时,HashMap会计算Entry Key 的哈希值。Map会根据这个哈希值把Entry插入到相应的位置。查找时,HashMap通过计算Key的哈希值到特定的位置查找这个Entry。
如果我们在使用自定义对象做为Key时,我们需要保证当改变对象的状态的时候,不改变它的哈希值。
5、Collection 和 Collections的区别
Collection 是一个接口,它是各种集合结构的父接口。
Collections是一个包装类,它包含有各种有关集合操作的静态方法。Collcetions不能被实例化,它的构造函数是私有的。
线程及相关
- 创建线程的方式及实现
创建线程的方式有三种:1)继承Thread,2)实现Runnable接口,3)通过Callable和Future创建线程
- sleep() 、join()、yield()有什么区别
sleep()执行后线程进入阻塞状态
yield()从未导致线程转到等待/睡眠/阻塞状态。在大多数情况下,yield()将导致线程从运行状态转到可运行状态,但有可能没有效果。yield()执行后线程进入就绪状态
join():暂停当前正在执行的线程对象,并执行其他线程。join()执行后线程进入阻塞状态
wait:释放了锁,处于阻塞状态,等待notify
- 说说 CountDownLatch 原理
CountDownLatch是通过一个计数器来实现的,当我们在new 一个CountDownLatch对象的时候需要带入该计数器值,该值就表示了线程的数量。每当一个线程完成自己的任务后,计数器的值就会减1。当计数器的值变为0时,就表示所有的线程均已经完成了任务,然后就可以恢复等待的线程继续执行了。
- 说说 CyclicBarrier 原理
通俗点讲就是:让一组线程到达一个屏障时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。
- 说说 Semaphore 原理
- 说说 Exchanger 原理
- 说说 CountDownLatch 与 CyclicBarrier 区别
- ThreadLocal 原理分析
- 讲讲线程池的实现原理
- 线程池的几种方式
- 线程的生命周期















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









