






版权声明:原创作品,如需转载,请与作者联系。否则将追究法律责任。
1、mapper和reducer
MapReduce对数据的处理分为两个阶段:map阶段和reduce阶段,这两个阶段分别由用户开发的map函数和reduce函数完成,在MapReduce运行环境中运行时,它们也分别被称为mapper和reducer。键值对(key-value pair)是MapReduce的基础数据结构,mapper和reducer读入和输出的数据均为键值对。MapReduce中,“键”和“值”可以是基础类型数据,如整数、浮点数、字符串或未经加工的字节数据,也可以是任意形式的复杂数据类型。程序员可以自行定义所需的数据类型,也可借助于Protocol Buffer、Thrift或Avro提供的便捷方式完成此类工作。 MapReduce算法设计的工作之一就是在给定数据集上定义“键-值”数据结构,比如在搜索引擎搜集、存储网页类工作中,key可以使用URL来表示,而value则是网页的内容。而在有些算法中,Key也可以是没有任何实际意义的数据,其在数据处理过程中可被安全忽略。在MapReduce中,程序员需要基于如下方式定义mapper和reducer: map: (k1,v1)-->[(k2,v2)] reduce: (k2,[v2])-->[(k3,v3)] 其中[...]表示其可能是一个列表。这些传递给MapReduce进行处理的数据可以存储于分布式文件系统上,mapper操作将应用于每一个传递过来的“键-值”对并生成一定数量的“中间键值对(intermediate key-value)”,而后reduce操作将应用于这些中间键值对并于处理后输出最终的键值对。 另外,mapper操作和reducer操作之间还隐含着一个应用于中间键值对的“分组”操作,同一个键的键值对需要被归类至同一组中并发送至同一个reducer,而传送给每个reducer的分组中的键值对是基于键进行排序后的列表。reducer生成的结果将会保存至分布式文件系统,并存储为一个或多个以r(即reducer号码)结尾的文件,但mapper生成的中间键值对数据则不会被保存。
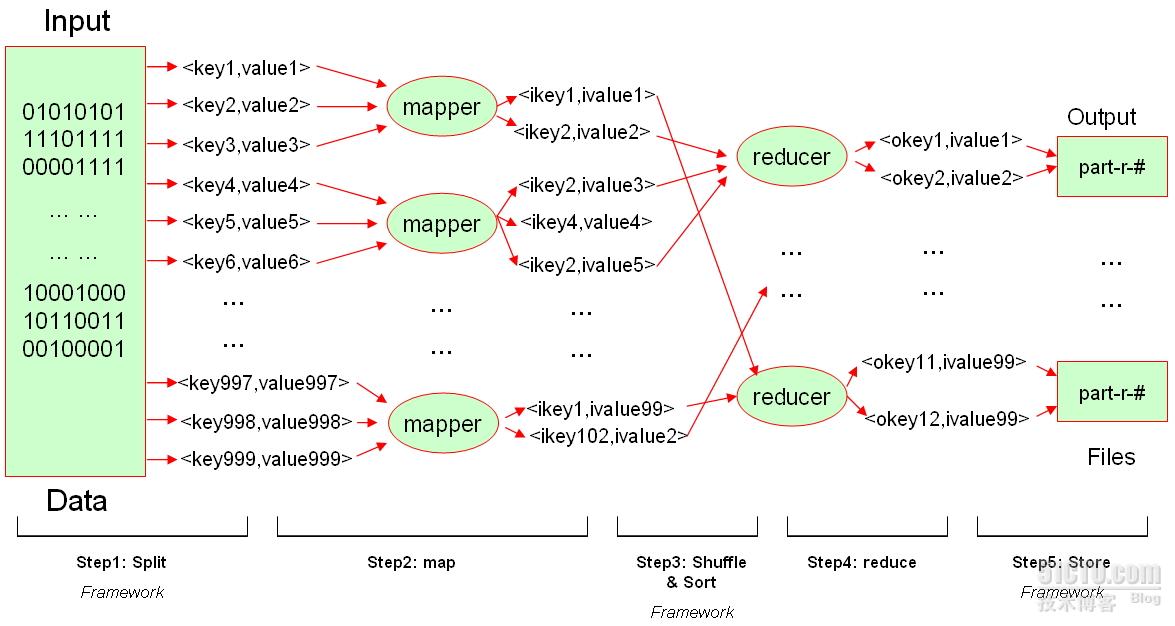
MapReduce在大数据处理时,会根据要处理的数据文件及用户编写的map函数首先将数据分割为多个部分(split),而后为每一个split启动一个map任务(map task,即map进程),这些map任务由MapReduce运行环境调度着分散运行于集群中的一个或多个节点上;每个mapper执行结束后,都可能会输出许多的键值对,称作中间键值对,这些中间键值对临时性地存放在某位置,直到所有的mapper都执行结束;而后MapReduce把这些中间键值对重新进行分割为一个或多个分组,分组的标准是键相同的所有键值对都要排序后归入同一个组中,同一个组可以包含一个或多个键及其对应的数据,MapReduce运行环境会为每一个分组启动一个reduce任务 (reduce task),这些reduce任务由MapReduce运行环境调度着运行于集群中的一个或多个节点上。 事实上,中间键值对分组的功能由一个称作partitioner的专用组件负责,后文对此会有进一步阐述。

单reduce任务的MapReduce数据流
图像来源:hadoop the definitive guide 3rd edition
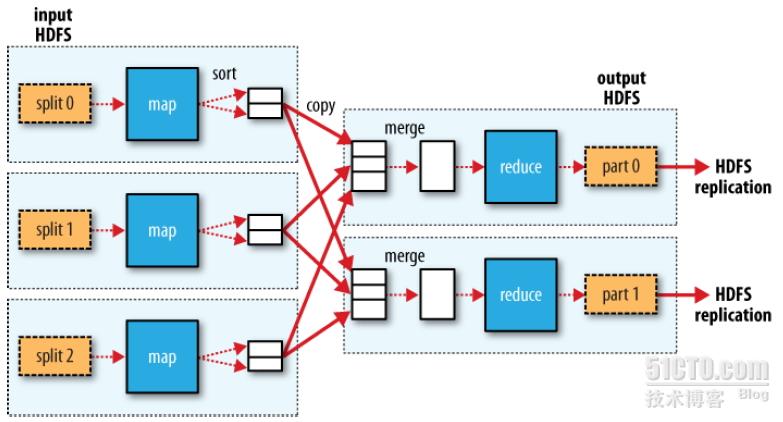
多reduce任务的MapReduce数据流
图像来源:hadoop the definitive guide 3rd edition
mapper和reducer可以直接在各自接收的数据上执行所需要的操作,然而,当使用到外部资源时,多个mapper或reducer之间可能会产生资源竞争,这势必导致其性能下降,因此,程序员必须关注其所用资源的竞争条件并加入适当处理。其次,mapper输出的中间键值对与接受的键值对可以是不同的数据类型,类似地,reducer输出的键值对与其接收的中间键值对也可以是不同的数据类型,这可能会给编程过程及程序运行中的故障排除带来困难,但这也正是MapReduce强大功能的体现之一。
除了常规的两阶段MapReduce处理流外,其还有一些变化形式。比如将mapper输出的结果直接保存至磁盘中(每个mapper对应一个文件)的没有reducer的MapReduce作业,不过仅有reducer而没有mapper的作业是不允许的。不过,就算用不着reducer处理具体的操作,利用reducer将mapper的输出结果进行重新分组和排序后进行输出也能以另一种形式提供的完整MapReduce模式。

没有reducer的MapReduce作业
图像来源:hadoop the definitive guide 3rd edition
MapReduce作业一般是通过HDFS读取和保存数据,但它也可以使用其它满足MapReduce应用的数据源或数据存储,比如Google的MapReduce实现中使用了Bigtable来完成数据的读入或输出。BigTable属于非关系的数据库,它是一个稀疏的、分布式的、持久化存储的多维度排序Map,其设计目的是可靠的处理PB级别的数据,并且能够部署到上千台机器上。在Hadoop中有一个类似的实现HBase可用于为MapReduce提供数据源和数据存储。这些内容在后文中会有详细介绍。
参考文献:
Data-Intensive Text Processing with MapReduce
Hadoop The Definitive Guide 3rd edtion
Apache Hadoop Documentation
本文出自 “马哥教育Linux” 博客,转载请与作者联系!














 565
565











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









