






向量数据库数据导入
milvus-cli导入 (功能不稳定)
连接方式(milvus_cli)
docker run -v ${宿主机目录}:${容器内部目录} --network host -it zilliz/milvus_cli:latest 数据导入方式(只能导入csv或者json格式)
insert -c ${集合名} -d ${分区} ${数据文件地址}pymilvus导入(推荐方式)
导入概述
将任意格式数据来源转化为list中包含dict的数据格式后进行插入
如
[{"vector":[1,2,3],"color":1,"brand":2},
{"vector":[1,2,3],"color":1,"brand":2}]
npy导入样例
npy数据样例(512位向量)
(10 * 513的数据文件)
测试集合结构
{
'collection_name': 'id_test',
'auto_id': True,
'num_shards': 1,
'description': '',
'fields': [{
'field_id': 100,
'name': 'id',
'description': '',
'type': < DataType.INT64: 5 > ,
'params': {},
'auto_id': True,
'is_primary': True
}, {
'field_id': 101,
'name': 'vector',
'description': '',
'type': < DataType.FLOAT_VECTOR: 101 > ,
'params': {
'dim': 512
}
}, {
'field_id': 102,
'name': 'user',
'description': '',
'type': < DataType.INT64: 5 > ,
'params': {}
}],
'aliases': [],
'collection_id': 449008755109392222,
'consistency_level': 2,
'properties': {},
'num_partitions': 1,
'enable_dynamic_field': False
}
npy格式文件导入code(示例)
import numpy as np
from pymilvus import MilvusClient
collection_name = "id_test"
client = MilvusClient(
uri="http://xxxxx:19530"
)
# 读取.npy文件
filename = "data.npy"
data = np.load(filename)
insert_data = []
# 指定要提取的列索引以及向量数据的范围,假设第一列为user_id,后续512列为向量
id_index = 0
start_index = 1
end_index = 513
# 遍历每一行
for row in data:
vector = row[start_index:end_index].astype(float)
# 提取指定列数据
user_id = row[id_index].astype(int)
#每一行组装为字典数据
row_data = {"vector": vector, "user": user_id}
insert_data.append(row_data)
print(insert_data)
res = client.insert(
collection_name=collection_name,
data=insert_data
)CSV导入样例
CSV数据样例(32位向量)
vector,color,brand "[-0.7209183664844216, 0.8711053876779193, 0.9964217845088184, 0.6231620813215315, 0.7918401115762204, 0.6459907382976304, -0.24449705344348627, 0.5283286331488382, -0.17982155969060365, 0.8378458891464253, 0.37783508288987555, -0.4628324550213916, 0.6581650509576793, 0.6071805318064338, 0.4498795735649994, -0.7750999466447372, -0.6462082414609587, -0.580388413445476, 0.8981473701593645, 0.07818571472661451, -0.5864306922180489, -0.16207520167186562, -0.9907683953944031, -0.4744881016805491, 0.8176021236939539, 0.08151555622128459, 0.6256771902239864, 0.3861348883342641, 0.09309366607546044, -0.7791598062940868, 0.8306950004781792, -0.10447828701244677]",501680546,521294227
测试集合结构
{
'collection_name': 'car',
'auto_id': True,
'num_shards': 1,
'description': '',
'fields': [{
'field_id': 100,
'name': 'id',
'description': 'primary_field',
'type': < DataType.INT64: 5 > ,
'params': {},
'auto_id': True,
'is_primary': True
}, {
'field_id': 101,
'name': 'vector',
'description': '',
'type': < DataType.FLOAT_VECTOR: 101 > ,
'params': {
'dim': 128
}
}, {
'field_id': 102,
'name': 'color',
'description': 'color',
'type': < DataType.INT64: 5 > ,
'params': {}
}, {
'field_id': 103,
'name': 'brand',
'description': 'brand',
'type': < DataType.INT64: 5 > ,
'params': {}
}],
'aliases': [],
'collection_id': 449008755105781201,
'consistency_level': 2,
'properties': {},
'num_partitions': 1,
'enable_dynamic_field': False
}
csv格式文件导入code(示例)
import pandas as pd
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, MilvusClient
# 连接 Milvus
client = MilvusClient(
uri="http://xxxxx:19530"
)
# 从 CSV 文件读取数据
csv_file_path = 'xxxx.csv'
df = pd.read_csv(csv_file_path)
# 注意处理向量列的数据类型
df['vector'] = df['vector'].apply(lambda x: [float(i) for i in x.strip('[]').split(',')])
dict=df.to_dict(orient="records")
res = client.insert(
collection_name="car",
data=dict
)
#返回主键id
print(res)注意
-
确保数据中的列名与Schema中的字段标签名相同。
-
使用python单次导入数据大小不应过大,应小于350MB,以便正确导入数据,否则会遇到如下报错。
-
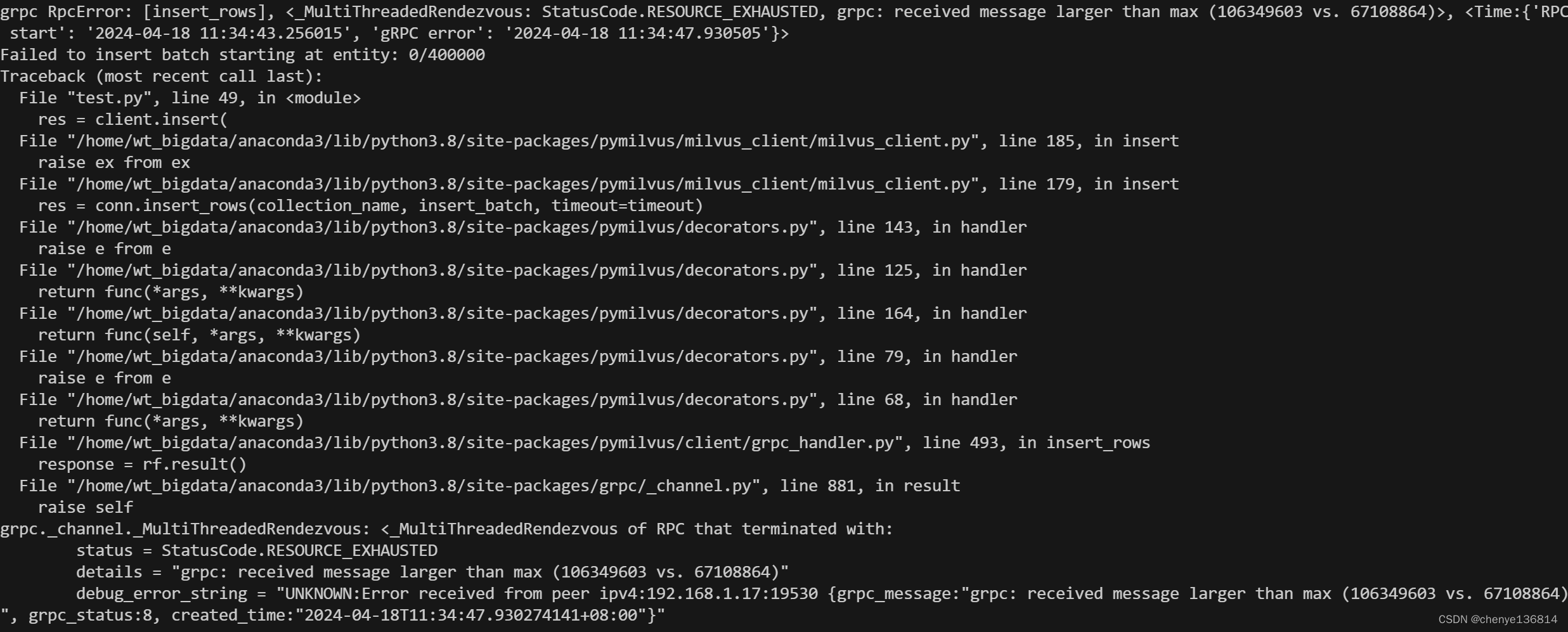
- 向量数据库导入
-
过大数据的导入采用代码中数据切分的模式进行数据导入
具体数据(在相同服务器进行,本次测试数据来源于单体部署milvus)
| 向量维度 | 数据量行数 w | 数据量大小 m | 导入时间 s |
|---|---|---|---|
| 64 | 1 | 13 | 0.14 |
| 64 | 5 | 67 | 0.68 |
| 64 | 10 | 135 | 1.39 |
| 64 | 20 | 270 | 2.82 |
| 64 | 25 | 338 | 3.23 |
| 128 | 1 | 26 | 0.24 |
| 128 | 5 | 134 | 1.00 |
| 128 | 10 | 268 | 1.84 |
| 128 | 11 | 295 | 2.25 |
| 128 | 12 | 322 | 2.36 |
| 256 | 1 | 53 | 0.31 |
| 256 | 5 | 267 | 1.67 |
| 256 | 6 | 320 | 1.76 |
| 512 | 1 | 106 | 0.61 |
| 512 | 2 | 213 | 1.68 |
| 512 | 3 | 319 | 1.69 |
(远程导入数据可能受到网络io瓶颈的影响)

















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









