






2014年曾经写过一篇《 解谜游戏 MU Complex 的过关图文攻略 (Episode1) 》,后来发现这个游戏出了Episode2,但可惜2015年的时候没有玩,今年发现的时候这个游戏在kongregate.com上的flash免费版已经下架,只好去steam平台上花¥34买了一个。

游戏的Episode1名叫“ENTER THE COMPLEX ”,剧情和原来没有变化,Episode2名叫“FREELYA”,开启时需要输入访问码“freeme”,这个访问码可以在Episode1通关时获取到。
进入到游戏后,会登录到一台名为jackparrot的主机,你接到的任务是获取密码并访问willterk。

这关一共有五个文件,termial.usage是对游戏技巧的简要说明,另外三个mail文件是公司其他员工向jakparrot发的邮件,每台主机都会有很多这样的文件,建议最好都扫一遍,因为有些mail文件中会提供对通关很重要的信息。
这关里最重要的文件是password,需要使用sudo命令打开,最后得到willterk主机的密码是peterobrain。

使用ssh命令登录willterk即可。
在willterk上,你需要找到密码登录mainframe,这一关需要用camera打开摄像头,用light normal和light black两个命令开关照明设备。

正常模式下,拍摄到的密码为“5 8 2 3 B _ _”

关闭找明后,可以看到密码输入板上的手印。其中1、2、3、5、8、A、B键上有手印,结合之前已经输入的字符,可以判断出密码最后两位的字符为1和A,所以密码可能是“5823B1A”或“5823BA1”,试一下这两个密码,最后得出密码是“5823BA1”。
mainframe中支持输入map命令查看整个MUComlex第五层(Level5)的拓扑图。这个Level被分为了4个区域(Section),我们需要解锁全部四个区域。

我们先去开启左上角的区域。

输入命令“ssh kyletopz”登录主机kyletopz

登录到这台主机后,无法使用ls命令,因为这台机器被锁住了。我们需要玩一个名为“bot”的游戏,

这个游戏的功能是,操作机器人走到目的地,可以使用move(前进两格)、cw(顺时针旋转)、ccw(逆时针旋转)三个命令操作机器人。

依次输入以下命令:
bot push ccw
bot push move
bot push cw
bot push move
bot push move
bot push ccw
bot push move
bot push move
bot push ccw
bot push move
bot push move
bot push ccw
bot push move
bot push ccw
bot push move最后输入指令bot play启动机器人,机器人成功到达终点后,计算机解锁,效果如下:

注意这个bot的游戏,每次进入后地图是不一样的,如下图就是这一关另外一种地图的版本:
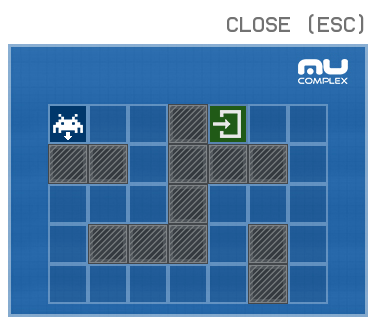
它的走法如下:
bot push ccw
bot push move
bot push cw
bot push move
bot push cw
bot push move
bot push ccw
bot push move
bot push ccw
bot push move
bot push move
bot push ccw
bot push move
bot push cw
bot push move
bot push ccw
bot push move
bot push ccw
bot push movekyletopz中一共有四个文件

我们打开database.txt,可以查看到fredmorgan的登录密码85eb2,这个密码也不是每次游戏都一样的。

fredmorgan中有五个文件,其中pic.jpg是解题的关键。

看这个图的时候,很容易被图片上面的红字迷惑,其实过关的密码藏在图片左下角,有五个字母“CLARA”,这是FredMorgan亡妻的名字。输入unlock命令,并输入密码clara,就可以解锁eddywolvers了。使用ssh登录eddywolvers。

要过这一关需要先完成两个挑战,输入start命令开始挑战。
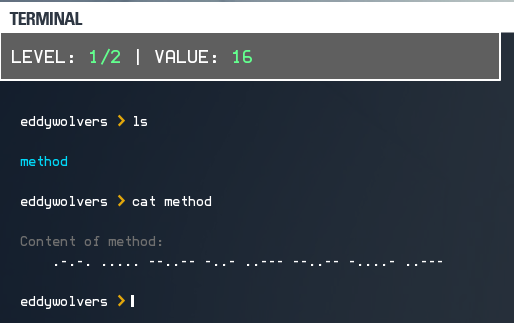
第一个挑战,线索是一组摩尔斯电码。摩尔斯电码的翻译规则,可以参考维基百科条目“摩尔斯电码”:
https://zh.wikipedia.org/wiki/%E6%91%A9%E5%B0%94%E6%96%AF%E7%94%B5%E7%A0%81
字母的摩尔斯电码:
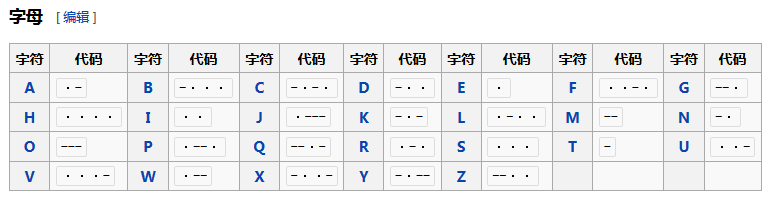
数字的摩尔斯电码(本题使用的是长码版):

标点符号的摩尔斯电码:

因此,我们可以翻译出,mothod的内容是:+5,x2,-2,因此计算答案的方法是f(x)=(x+5)*2-2

第二个挑战的规则是用国际信号旗写的,国际信号旗的介绍可参考条目:
https://zh.wikipedia.org/wiki/%E5%9C%8B%E9%9A%9B%E4%BF%A1%E8%99%9F%E6%97%97
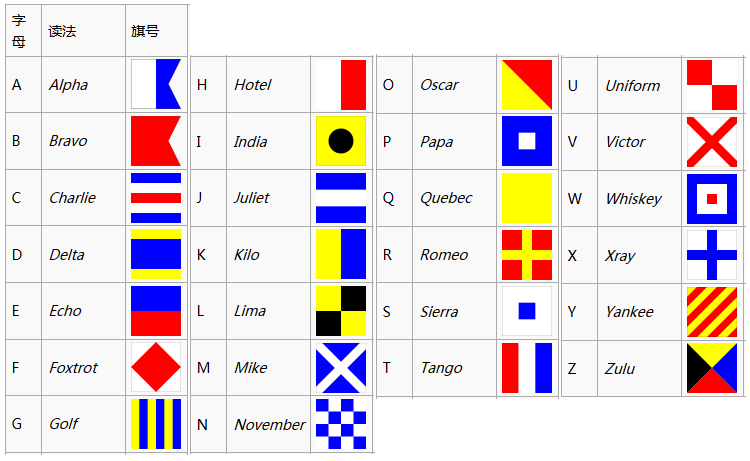
第二个挑战的规则,翻译过来就是“SQUARE MINUS SEVEN”,因此计算答案的方法是f(x)=x^2-7
将每道题目的VALUE代入到我们找出的方法中,即可算出结果,输入命令“solve 结果”提交答案
完成这两个挑战后,计算机的content.lock文件就解锁了
解锁eddywolvers后,你就可以使用cat命令解压扩展名为.tar的文件了

至此eddywolvers计算机解锁,完成了一个Section。

附中篇和下篇攻略地址:
解谜游戏 MU Complex 的过关图文攻略 (Episode2)(中)
http://my.oschina.net/Tsybius2014/blog/693896
解谜游戏 MU Complex 的过关图文攻略 (Episode2)(下)
http://my.oschina.net/Tsybius2014/blog/693923
END














 366
366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









