







主要内容 webmagic
- 前言
- 正文
- 尝试
- 再尝试
前言(废话,可忽略)
已经记不得有多久没更新内容了,脑子只记得这一年过得兵荒马乱的~~~
2015年从电信出来去了互联网云计算的创业团队,激情满满学到了很多东西,这一年学习到openstack以及很多开源的项目,结实了很多厉害的大牛和好玩的同事伙伴。有陶老大,老谭,川川,钊哥这样的大神;也有老田,老余,啸大爷这样的逗逼同事。
最喜欢的就是和啸爷撕逼,哈哈….
不过最终公司还是夭折了,不管怎样我还是很感谢这一切。感恩陶老大…
正文
上周接到领导任务,让抓取对手网站发布的一些数据,获取到数据后供给市场部人员分析使用。
说实话,第一感觉就是要做网络爬虫spider。心里默念,“我靠,老子这块没玩过啊”但还是本着“男人不能说自己不行”的原则网上搜索了一些文章,最终选择了webmagic。webmagic这个框架整体来说比较易于二次开发,容易上手,还也是较多不足的地方,比如二级域名domain的问题,这样再根据targetUrl去获取二级页面时,可能出现信息无法获取的场景,也就是跨域domain的问题,比较常见。之前比较反感国内很多博客网站内容都是千篇一律,都是你抄我抄,蛋疼的很。
ok,言(我)归(也)正(想)传(抄)。哈哈~
webmagic相关资料
| url | 简介 |
|---|---|
| http://webmagic.io/ | 官网 |
| http://webmagic.io/docs/zh/ | 中文文档,里面有demo |
| https://git.oschina.net/flashsword20/webmagic | webmagic项目托管地址 |
| http://blog.163.com/iamlyia0_0/blog/static/509579972014851290431/ | 参考 |
若只是简单获取相关网页数据,引入两个jar就大功告成了。
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.5.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.5.3</version>
</dependency>
按照官方提供的demo运行后,你会发现里面有几大组件。表格中其功能为本人理解,可能与实际对象含义存在偏差,如有误,请@我改正:
| 名称 | 功能 |
|---|---|
| Downloader | 基础。利用httpClient作为下载工具,下载页面内容便于后续处理解析; |
| Page | 网页内容对象。 指根据url下载到的页面内容,包括页面dom元素,css样式,javascript等; |
| Pageprocess | 爬虫的核心。 负责解析页面,抽取有用信息,以及发现新的链接,可采用css(),$(),xpath()方法对特定页面元素进行抽取; |
| Site | 网站设置。设置网站domain,cookies,header,重试次数,访问间隔时间等; |
| Scheduler | 抓取页面队列。 管理待抓取的URL,以及一些去重的工作,将目标url内容push到抓取队列中; |
| Pipeline | 输出,收尾。 负责抽取结果的处理,包括计算、持久化到文件、数据库; |
| Spider | 爬虫的入口类 采用链式设计,通过它来设定多线程,页面解析器,调度以及输出方式等。 |
尝试
上面介绍了那么多,咱们是不是该好好耍一耍了呢?
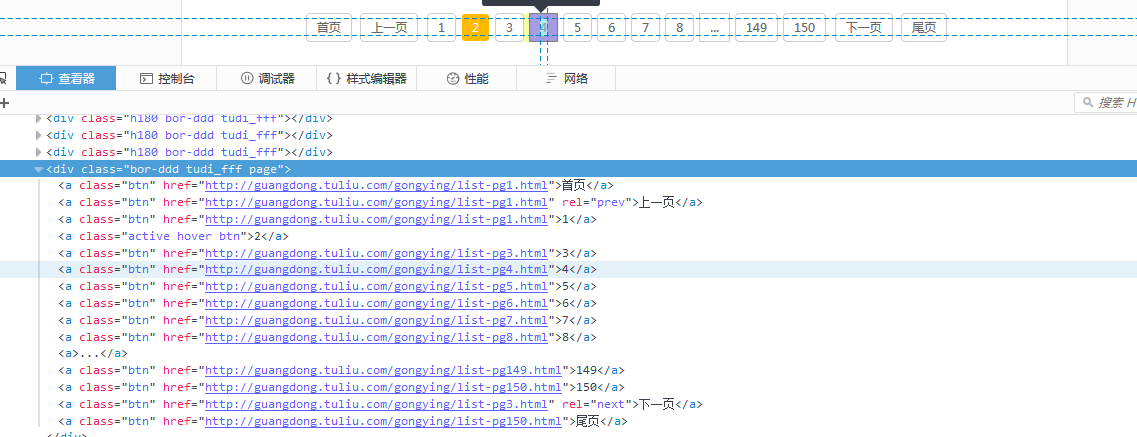
首先咱们获取某互联网的信息数据,具体url就不指明了,可在代码中自行查找。打开网页后会看到数据量还是挺多的,有个分页div。按照官方讲解可获取分页div内容,一般来讲这块是有规律的,那样其实全部的url也就获取到了。
// 获取页面分页内容;
List<String> pageNumberList = page.getHtml().xpath("//div[@class='bor-ddd tudi_fff page']/a/text()").all();
// 待抓取列表;
List<String> targetUrlList = new LinkedList<String>();
int [] pageNumber = new int[200];
// 求数组最大值;
int max=0;
for(String url : pageNumberList){
try{
int i = Integer.valueOf(url);
pageNumber[i] = i;
}catch (NumberFormatException ex){
continue;
}catch (Exception ex){
ex.printStackTrace();
continue;
}
for(int i=1;i<pageNumber.length;i++)
{
if(pageNumber[i]>max)
max=pageNumber[i];
}
}
写道这里的时候,其实已经获取到了全部页面,对伐?
那后面的就一路向西就好了,挨个解析页面就行啦,你说呢~
再尝试
常见的场景:有些数据只能登陆网站才可以获取到,webmagic本身是不提供post请求,咋办呢? 只能追本溯源了,采用JDK自带的类进行处理了,首先模拟登陆获取需要用到的cookie,组装好相关site设置后,这样就可以获取到敏感数据了。
首先先手工登陆该网站,会发现登陆成功后会有一个提示,那我们就拿这个提示来验证咱们是否登陆成功,好伐?截图为手工成功后页面进行调整前的内容:
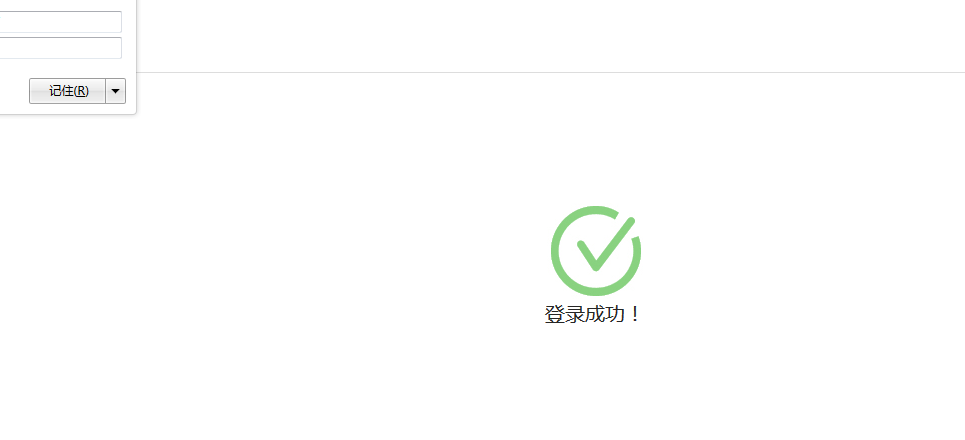
代码如下:
/**
* 模拟登陆,获取cookie
* @param username
* @param password
* @throws Exception
*/
public void logIn(String username, String password) throws Exception {
httppost.setHeader("Content-Type", "application/x-www-form-urlencoded");
String post = "username="+username+"&password="+password;
httppost.setEntity(new StringEntity(post, "utf-8"));
try {
// 提交登录数据
HttpResponse re = httpclient.execute(httppost);
// System.out.println("response: "+re);
Header[] h =re.getAllHeaders();
for (Header header : h) {
System.out.println(header.toString());
}
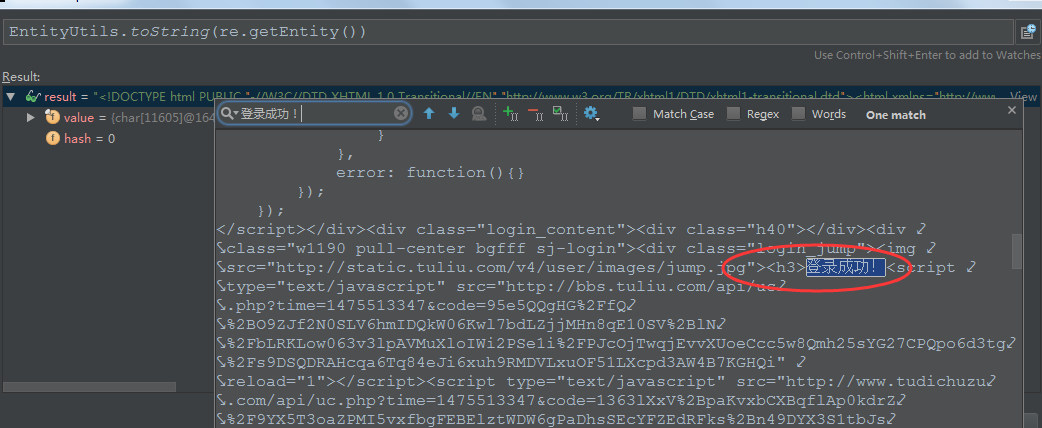
if(re.getEntity()!=null && EntityUtils.toString(re.getEntity()).contains("登录成功!")){
System.out.println("登录成功!");
}
} catch (ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
Server: nginx
Date: Mon, 03 Oct 2016 16:53:23 GMT
Content-Type: text/html; charset=utf-8
Transfer-Encoding: chunked
Connection: keep-alive
Keep-Alive: timeout=10
Vary: Accept-Encoding
Set-Cookie: PHPSESSID=g12odi58b8s1cittik8jelfsk5; path=/; domain=.tuliu.com
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Pragma: no-cache
Set-Cookie: tlfailed_num=deleted; expires=Thu, 01-Jan-1970 00:00:01 GMT; path=/; domain=.tuliu.com
Set-Cookie: tlfailed_num_time=deleted; expires=Thu, 01-Jan-1970 00:00:01 GMT; path=/; domain=.tuliu.com
Cache-control: private
X-Powered-By: Tuliu.com
登录成功!拿到PHPSESSID后离成功就剩一步之遥啦,将PHPSESSID设置到site对象中即可获取部分敏感数据啦,是不是很开心呢?
//抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(5)
.setSleepTime(2000)
.addHeader("Connection", "keep-alive")
.addCookie("PHPSESSID", PHPSESSID) // 此处为模拟登陆后的指;
.setUserAgent("Mozilla/5.0 (Windows NT 6.1; WOW64; rv:49.0) Gecko/20100101 Firefox/49.0")
.setCharset("UTF-8").enableHttpProxyPool();特别喜欢这种链式设计,用着很爽,好吧,已经很困了,先写到这里到,后续会再分享多个demo,大家一起学习webmagic。demo已提供链接,为了数据安全demo中url,username已模糊处理,望多交流。















 1022
1022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









