






kafka 实战
ps: 描述图来自"Apache kafka 实战"
创建topic
cd /usr/local/kafka
bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic test --partitions 1 --replication-factor 1
控制台显示创建成功

kafka的日志

zookeeper的日志

查看topic的状态
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test

(PartitionCount)分区数
(ReplicationFactor)副本数
发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
消费消息
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
生产者:

消费者:

(message system) 消息引擎/消息队列
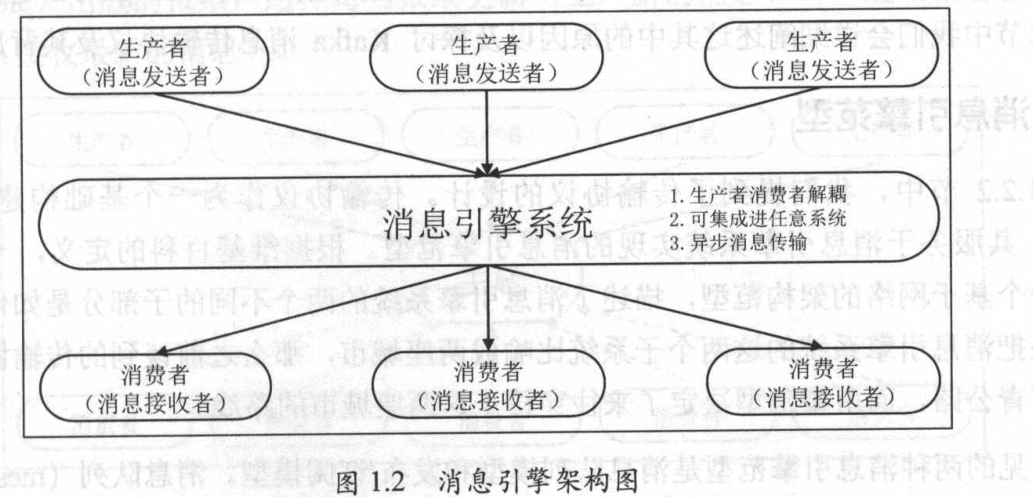
消息引擎功能
- 解耦
- 异步
- 削峰
设计消息引擎的重要理念:
- 消息设计
- 传输协议设计
消息引擎的重要模型:
- 消息队列模型(点到点/P2P)
- 发布/订阅模型(pub/sub)
p2p模型,消息会向队列一样,消费掉的消息会从队列中移除,一个消息只能被某个消费者消费,是点到点的消息传输.
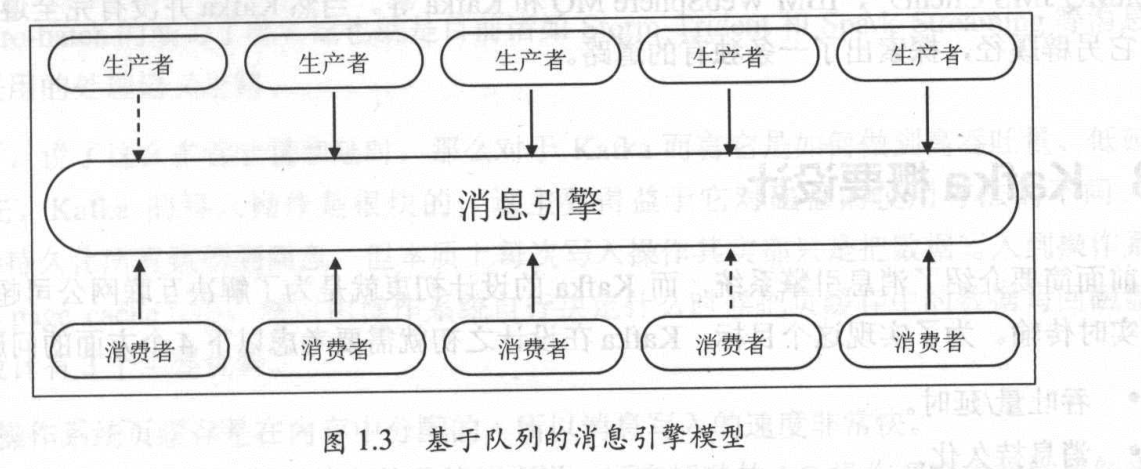
pub/sub模型,消息会保存在topic(主题)容器中,一旦生产了新的消息,所有订阅相同topic的消费者都会收到消息.

kafka 都支持以上两种模型
Java消息服务(Java message service)JMS
一套API规范,kafka以及其他很多的消息引擎都支持了这套API规范,但是kafka没有完全遵循这套规范
kafka优点
- 吞吐量/延时(batching思想,批处理)
- 消息持久化
- 负载均衡和故障转移
- 伸缩性
怎么做到高吞吐/低延时?
然后kafka会持久化所有数据到磁盘,但本质上每次写入操作其实都只是把数据写入到操作系统的页缓存(page cache)中,然后由操作系统自行决定什么时候把页缓存中的数据写回磁盘上。3个优势
- 操作系统页缓存是在内存中分配的,所以消息写入的速度非常快
- kafka不必和底层的文件系统打交道,所有烦琐的I/O操作都jiaoyou操作系统来处理
- kafka写入操作采用追加写入(append)的方式,避免了磁盘随机写操作
磁盘顺序访问速度和内存随机访问速度差不多一样快
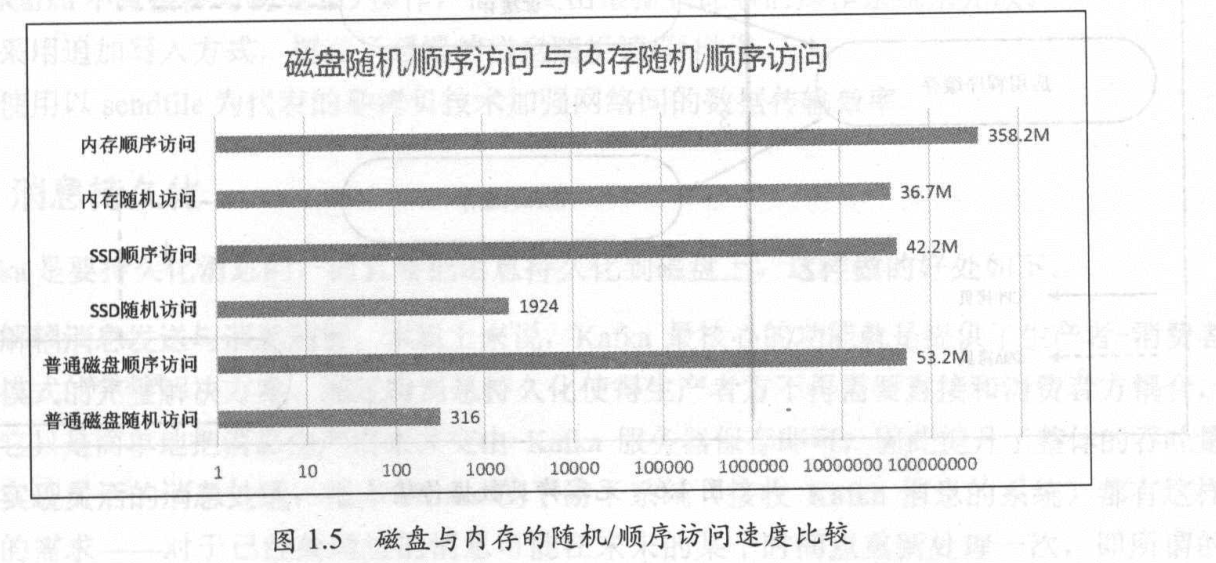
kafka写入/读取消息都是先访问操作系统页缓存,如果命中,则把消息直接发送到网络的socket上.
上面的过程是使用了Linux的sendfile系统调用做到的,而这种技术就是使用零拷贝技术(Zero Copy)
下面是传统的Linux数据传输
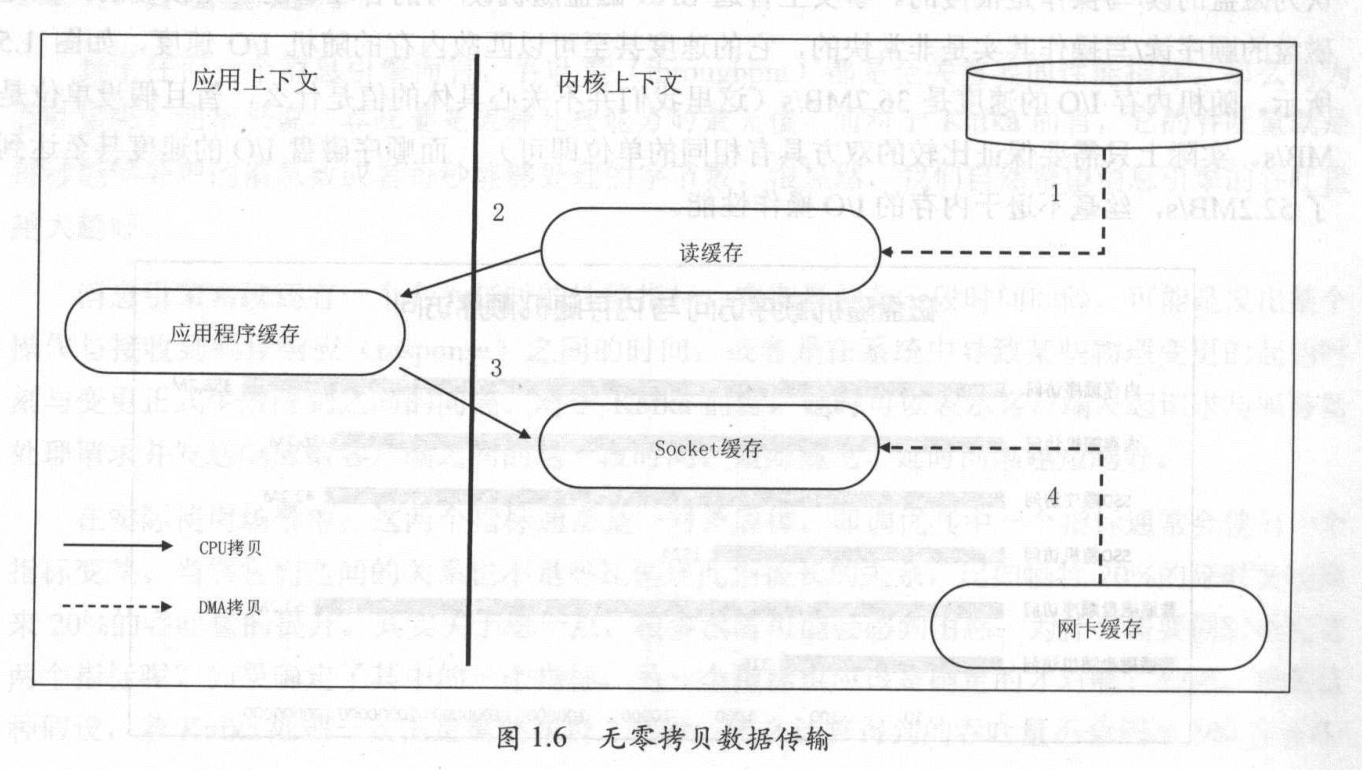
下面是使用了零拷贝,使用零拷贝节省了内核缓冲区与用户态应用程序缓冲区之间的数据拷贝,同时利用直接存储器访问技术(DMA)执行I/O操作,因此也避免了OS内核缓冲区的数据拷贝
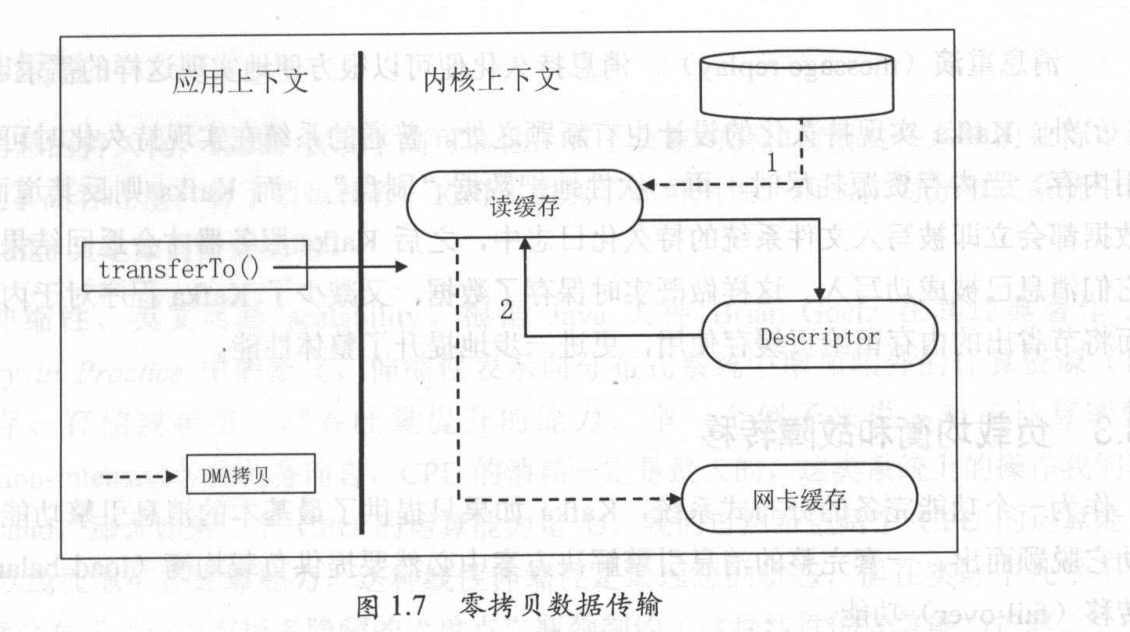
总结一下:
- 访问消息大量使用操作系统页缓存,内存操作速度快且命中率高
- kafka不直接参与物理I/O操作,而是交给操作系统执行
- 持久化消息采用追加写入方式,摒弃缓慢磁盘的随机访问操作
- 网络消息发送使用sendfile的技术加快网络传输的效率
为什么要持久化消息?
- 解耦消息发送与消息消费
- 实现灵活消息处理(消息重演)
kafka所有数据都会立即写入文件系统的持久化日志,之后kafka服务器才会返回结果通知他们消息已经被成功写入,保证了实时保存数据
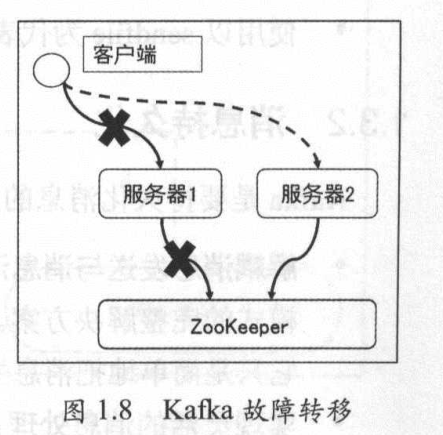
(load-balancing)负载均衡 (fail-over)故障转移
负载均衡
- 分区leader选举
故障转移
- 心跳机制
- 会话机制
伸缩性
kafka的状态统一交由zookeeper管理,扩展kafka集群只需要增加新的kafka服务器即可
kafka架构图

kafka名词
消息
消息的格式:
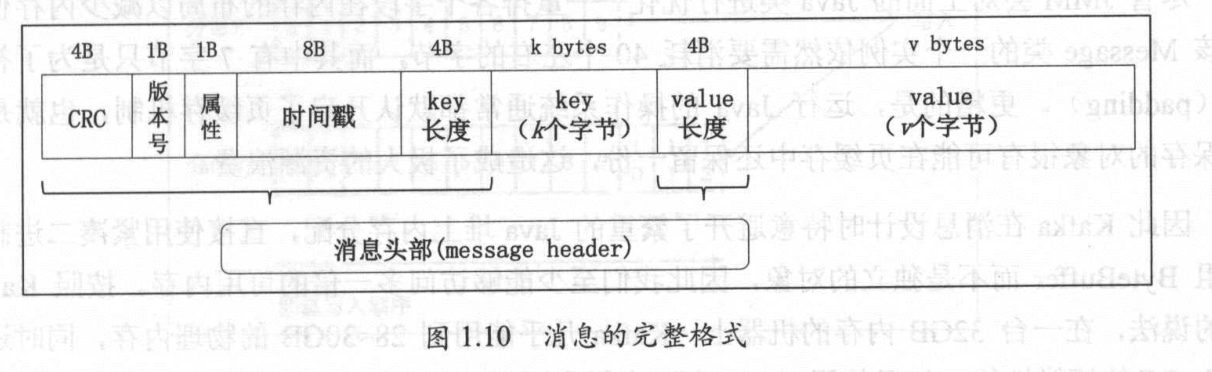
key: 消息建,对于消息做分区(partition)时使用,即决定消息存放在那个topic的哪个partition下
value: 消息体,保存实际的数据
timestamp: 消息发送时间戳
属性字段: 目前共一个字节(8位),目前用了3位,用于保存数据的压缩的类型.
topic partition
topic 主题
partition 分区
逻辑概念,代表一类消息,通常用来划分业务,一个topic由多个partition组成
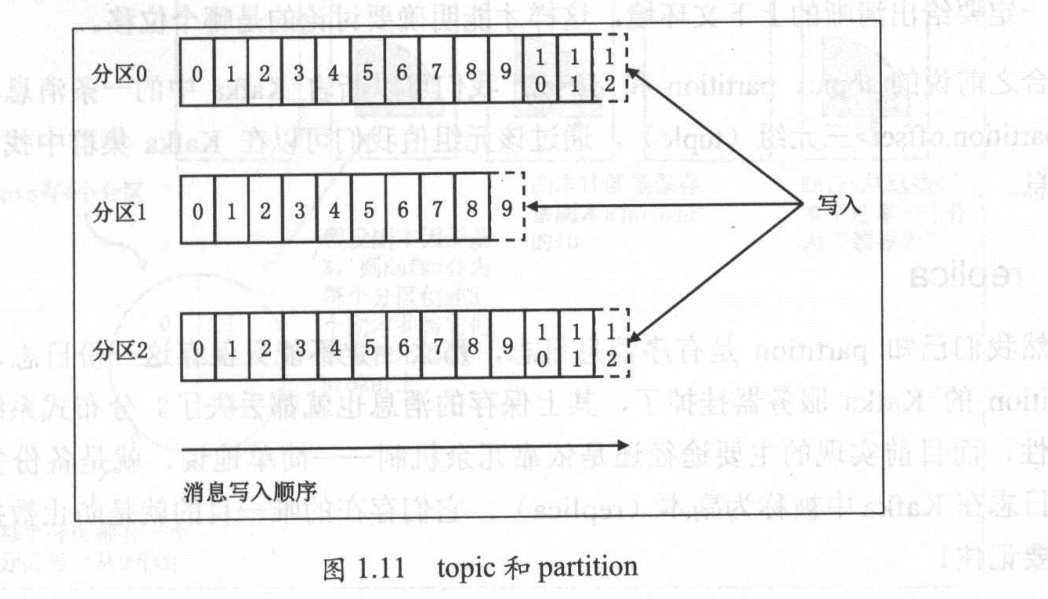
offset
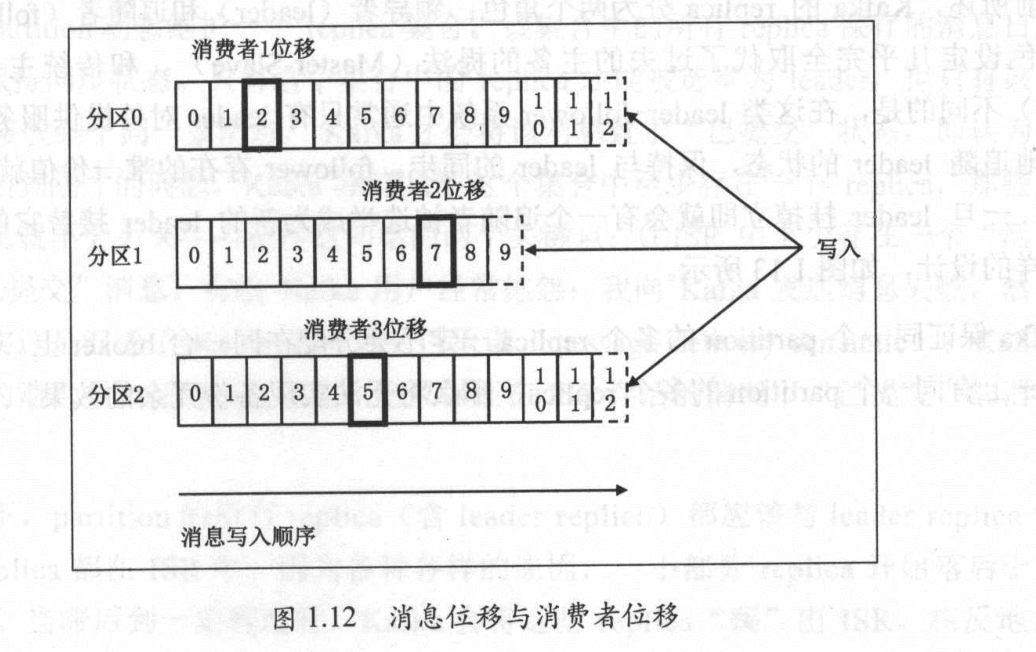
通过上边的topic partition offset 可以查询到唯一对应的消息
replica
replica partition的副本,唯一目的就是防止数据丢失
副本分两类: leader replica 领导者副本 和 follower replica 追随者副本
leader follower
leader副本负责提供服务给客户端,而follower副本不提供服务给客户端,follower 负责从leader中获取数据,一旦leader副本所在的broker宕机了,kafka会从剩余的follower中选举一个leader副本出来继续给客户端提供服务
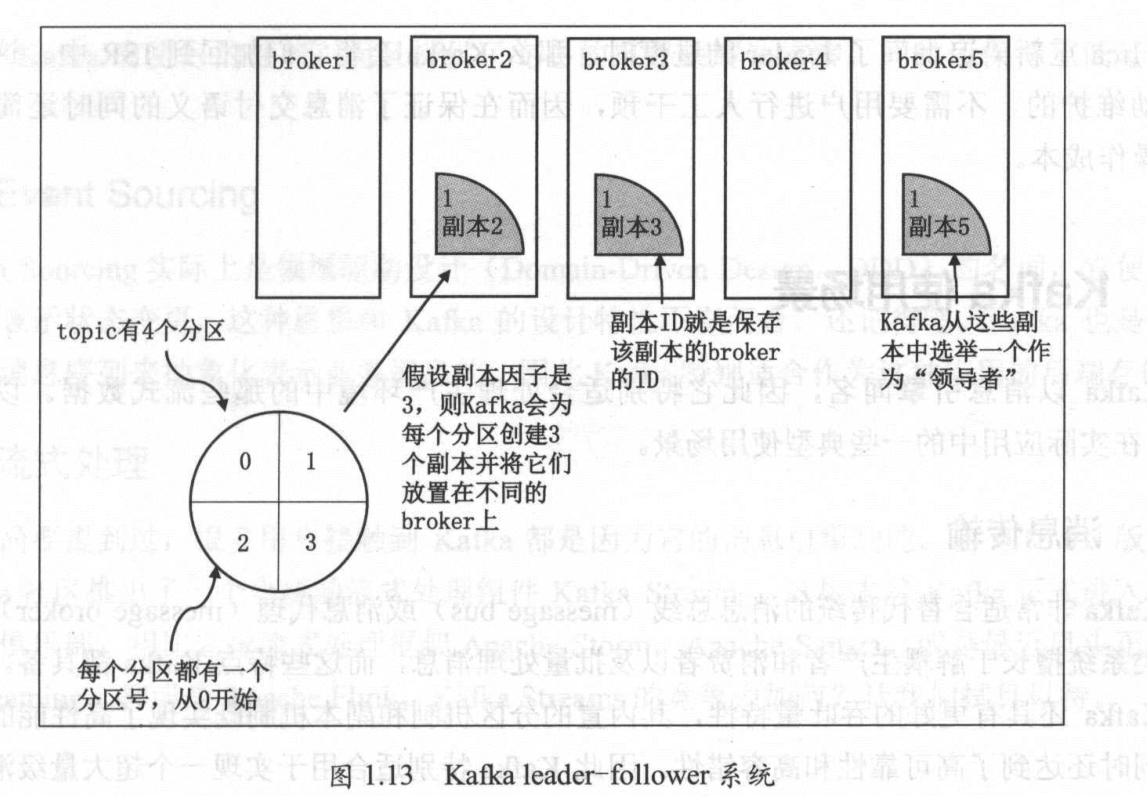
ISR
全称: in-sync replica,与 leader replica 保持同步的 replica的集合
kafka 使用场景
消息传输
日志行为追踪
审计数据收集
日志收集
event source
流失处理
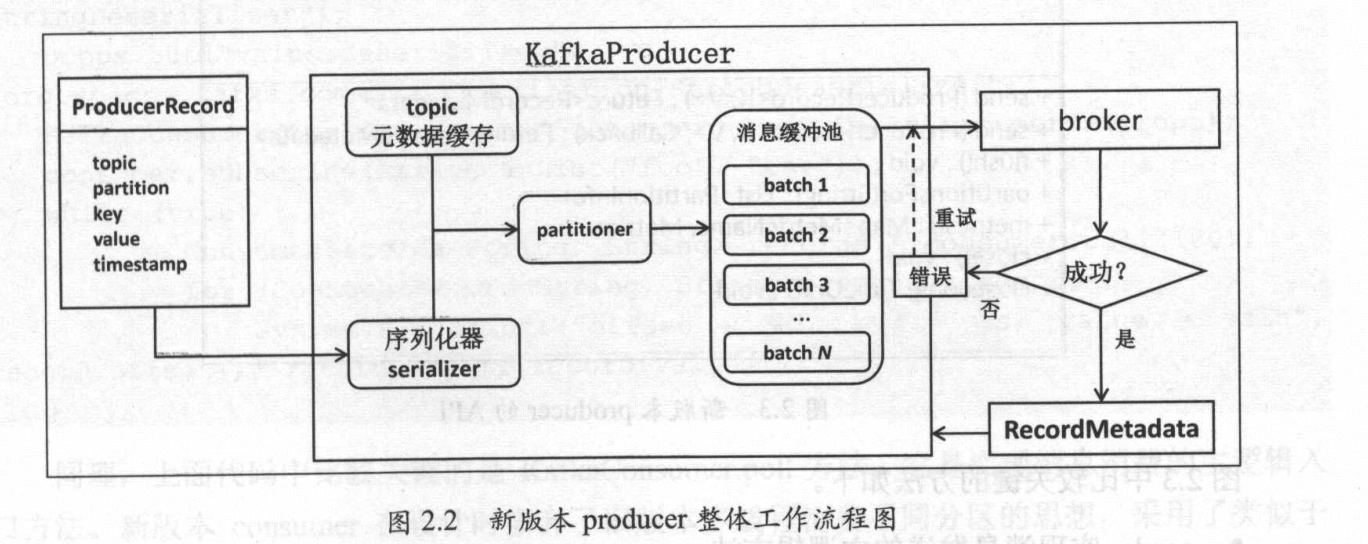
producer 生产者工作流程
版本:1.0.0
集群环境规划
磁盘
- 追求性价比的可以考虑使用JOBD(just bunch of disks:一堆普通硬盘)
- 使用机械硬盘(HDD)可以满足
kafka集群的使用,ssd更好
kafka需要多大的磁盘容量?
可以从以下几点考虑容量规划:
- 新增消息数
- 消息留存时间
- 平均消息大小
- 副本数
- 是否启用压缩
内存
-
尽可能的分配更多内存给操作系统的page cache
-
不要为broker设置过大的堆内存,最好不要超过6GB
-
page cache 大小至少大于一个日志段的大小
CPU
- 使用多核系统,CPU核数最好大于8
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









