






爬虫
网络爬虫本质上就是一个 程序 或者 脚本, 网络爬虫按照一定规则获取互联网中信息(数据), 一般来说爬虫被分为三大模块: 获取数据 解析数据 保存数据
爬虫网络上数据的程序或脚本。爬虫的价值本质就是获取数据的价值. 数据的价值越高, 爬虫的价值越高
数据的价值: 一切皆为数据
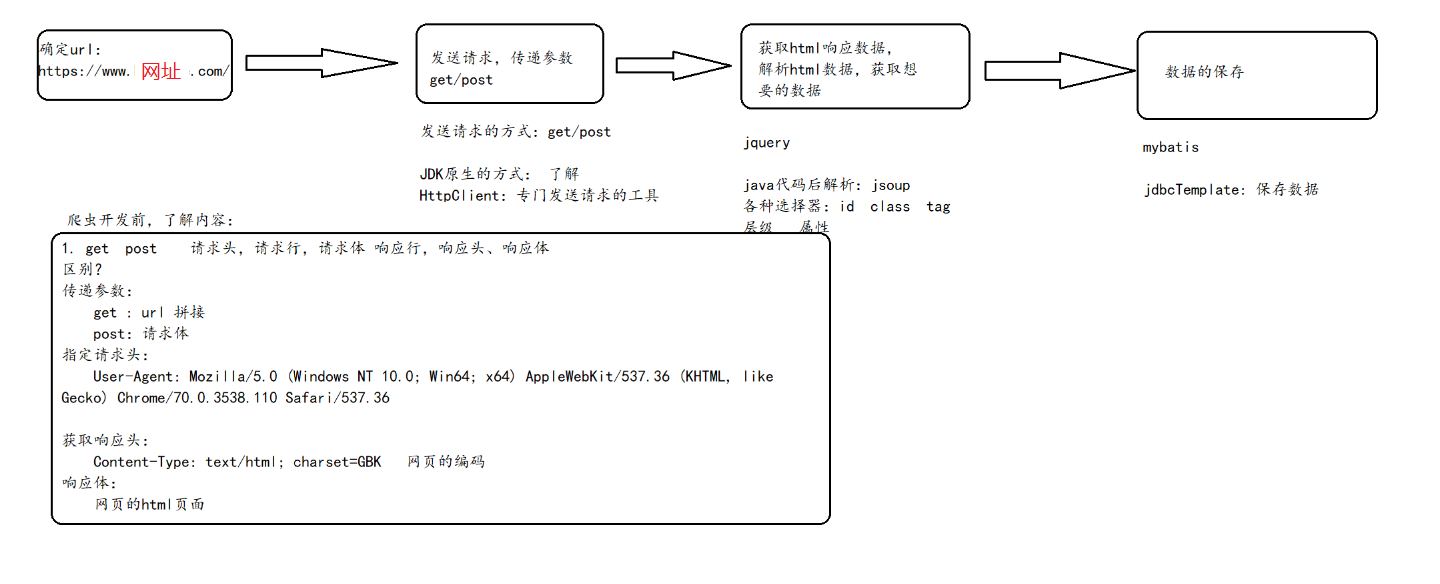
获取数据: 发送http请求,获取html网页 jdk的URL httpclient工具(工具)
解析数据: 解析html网页,获取我们想要的数据内容 jQuery js jsoup
保存数据: DButils jdbc mybatis jdbcTemplate 将数据保存到数据库
爬虫的分类:
通用爬虫: 获取互联网中所有的数据,不局限于网站, 行业 ,分类
垂直爬虫: 获取互联网中某一个网站, 行业 , 分类下的数据
爬虫的基本流程:
1.1原生Jdk发送 [ Get方法 ]
public class jdkGet {
public static void main(String[] args) throws Exception {
// 1 确定首页的Url
String indexUrl = "http://xxx.com";
// 2发送请求,获取数据
// 2.1将String类型的字符串转换成一个URL对象
URL url = new URL(indexUrl);
// 2.2通过url对象获取远程连接
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
// 2.3设置请求方式 请求参数 请求头
urlConnection.setRequestMethod("GET");
// 2.4获取数据
InputStream inputStream = urlConnection.getInputStream();
// 2.5遍历响应的输入流
byte[] bytes = new byte[1024];
int len = 0;
while ((len=inputStream.read(bytes))!= -1){
System.out.println(new String(bytes,0,len));
}
// 释放资源
inputStream.close();
}
}1.2原生Jdk发送 [ Post方法 ]
public class jdkPost {
public static void main(String[] args) throws IOException {
// 1 确定url
String indexUrl = "http://xxxx.com";
// 2发送请求,获取数据
// 2.1创建Url对象
URL url = new URL(indexUrl);
// 2.2 发送请求
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
// 2.3设置请求方法
urlConnection.setRequestMethod("POST");
// 2.4获取响应结果数据
InputStream inputStream = urlConnection.getInputStream();
// 2.5使用字符流的方式读取内容
// // 创建一个byte数组
// byte[] bytes = new byte[1024];
// // 定义一个变量用来记录读的长度
// int len = 0;xxxx
// while ((len = inputStream.read(bytes)) != -1) {
// String s = new String(bytes, 0, len);
// System.out.println(s);
// }
// 把字节流转换成字符流
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
// 定义一个变量用来接受读的长度
String line = null;
// 判断,一次读一行
while ((line = bufferedReader.readLine()) != null) {
System.out.println(line);
}
// 2.6 关闭资源
inputStream.close();
bufferedReader.close();
}
}2.1使用HttpClient发送请求 [ Get方法 ]
public class HttpClientGet {
public static void main(String[] args) throws IOException {
// 1.确定爬取的url地址
String indexUrl = "http://www.xxx.com";
// 2.导入依赖
// 2.1 创建HttpClient对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 2.2 创建请求对象: GET HttpGet对象 POST HttpPost对象
HttpGet httpGet = new HttpGet(indexUrl);
// 2.3设置请求头
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36");
// 2.4 发送请求,获取数据
CloseableHttpResponse response = httpClient.execute(httpGet);
// 2.5 获得相应码
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
// 获取响应头
Header[] allHeaders = response.getAllHeaders();
for (Header allHeader : allHeaders) {
System.out.println("响应头: name" + allHeader.getName() + "value:" + allHeader.getValue());
}
// 获取响应体
HttpEntity entity = response.getEntity();
String s = EntityUtils.toString(entity, "UTF-8");
System.out.println(s);
}
// 释放资源
httpClient.close();
}
}2.2使用HttpClient发送请求 [ Post方法 ]
public class HttpClientPost {
public static void main(String[] args) throws IOException {
// 1.确定一个Url
String indexUrl = "http://www.xxx.com";
// 2.发送请求,获取数据
// 2.1创建对象
CloseableHttpClient client = HttpClients.createDefault();
// 2.2 创建HttpPost对象
HttpPost httpPost = new HttpPost(indexUrl);
// 设置请求头,请求体(表单数据)
httpPost.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36");
// 2.3 发送请求,获取数据
List<BasicNameValuePair> parameters = new ArrayList<BasicNameValuePair>();
// 添加数据, 匿名对象 有参构造
parameters.add(new BasicNameValuePair("age", "31"));
CloseableHttpResponse response = client.execute(httpPost);
// 设置请求参数:请求体(表单数据)
HttpEntity urlEncodedFormEntity = new UrlEncodedFormEntity(parameters);
// 2.4 获取响应头, 状态码, 响应体
int statusCode = response.getStatusLine().getStatusCode();
if (statusCode == 200) {
// set-cookies: 服务器写回来的cookie信息
// 302 Location响应头 重定向的地址
Header[] allHeaders = response.getAllHeaders();
for (Header allHeader : allHeaders) {
System.out.println("响应头:" + allHeader.getName() + "响应体" + allHeader.getValue());
}
// 获取响应体
HttpEntity entity = response.getEntity();
// 返回 html页面 也有可能json数据 ajax
String s = EntityUtils.toString(entity, "UTF-8");
System.out.println(s);
}
// 关闭资源
client.close();
}
}
小荷才露尖尖角















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









