






1. kafka特性
kafka是一种分布式的消息服务系统,它从消息发送端获取消息,然后将消息发布给接收端。kafka在不同机器上设置备份以提供高可用性。同时通过分区(partition)设置,kafka能够并行处理消息,从而提高消息处理效率。
kafka不会对消息进行处理,而是作为消息管道在消息发送端和消费端之间建立连接。一方面,kafka的高效率和高可用性使得在开发过程中消息的传递更为简便;另一方面,由于kafka支持多对多发送,即可以从多个消息源接收消息,亦可向多个消息接收端发送消息,故也可用于日志收集等其他场景。
2. kafka集群结构及逻辑
2.1 kafka集群结构
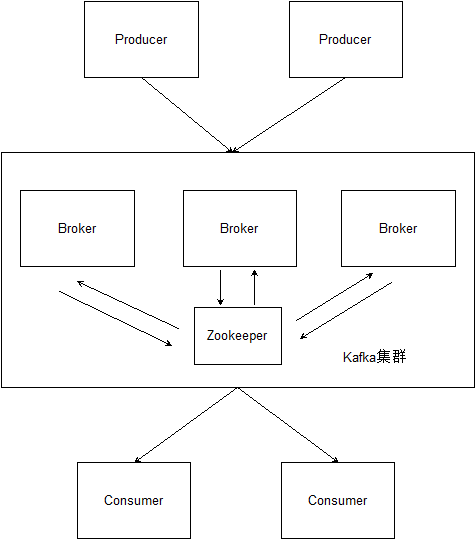
kafka集群结构如上图所示。整个消息处理过程分为三部分:
- 产生并发送消息的外部组件叫做Producer,它可以是任意产生消息的系统或程序。Producer通过kafka提供的api将消息发送给kafka集群。
- 接收并转发消息的部分是kafka的核心:kafka集群。kafka集群由一系列运行kafka进程的实例(即服务)组成。每个实例是一个kafka进程,称为Broker。每个Broker都会负责处理一部分消息,并把正在处理的消息备份在其他Broker中。Broker将状态信息保存在Zookeeper中,并通过Zookeeper来相互通信。
- 从kafka集群接收消息的外部组件叫做Consumer,Consumer可以是任意需要消费消息的系统或程序。Consumer通过kafka提供的api将从kafka集群接收消息。
2.2 发送消息到kafka
在大部分情况下,我们需要传递的消息都不会是一种。相反,我们常常需要在一个Producer中产生多种类型的消息(或者多个Producer分别产生不同种类的消息),然后把这些消息发送到一个kafka集群中,然后按照种类把消息分发给多个Consumer。在kafka中,每种消息称为一个Topic。当Producer发送消息时,需要指定Topic的名字,这样发送的消息就会被分类处理。
2.3 从kafka接收消息
和发送消息类似,从kafka读取消息的时候,需要指定topic的名字,这样Consumer就只能接收类型为确定topic的消息。如果多个Consumer都指定了同一个topic,那么这些Consumer都会获得一个消息副本。
由于kafka集群是一个分布式系统,因此可以通过指定Group来并行地从kafka接收消息。一个Group里可以包含多个Consumer,这些Consumer各自获得一部分消息,合并起来即是完整的消息内容。当这些Consumer并行接收消息时,可以提高读取效率。相关细节将在3.1消息分区中有详细介绍。
Consumer以主动拉取(pull)的方式获取数据,这样Consumer可以根据自己消费能力去拉取数据。而在kafka中,消息会被分布式地持久化到磁盘上,因而并不担心数据溢出问题。
3. kafka消息处理及接收发送机制
本章将介绍kafka的内部机制。kafka以分区的方式接收和发送消息,从而以并行的方式提高效率。Broker间互为备份,提高了系统可用性。消息的接收及发送机制尽量简化,Consumer读取消息的进度(offset)对于Broker来说是透明的,从而提高kafka集群的服务效率。
3.1 消息分区
对于同属一个Topic的消息,kafka集群在接收后会按照配置放到不同的分区(Partition)上去。不同的分区尽量分布在不同的Broker上,并有一个独立的目录以存放消息文件。目录命令规则为 topic_partition。例如,对于Topic为my_topic,且分区序号1的消息,都会被存储在路径my_topic_1下。
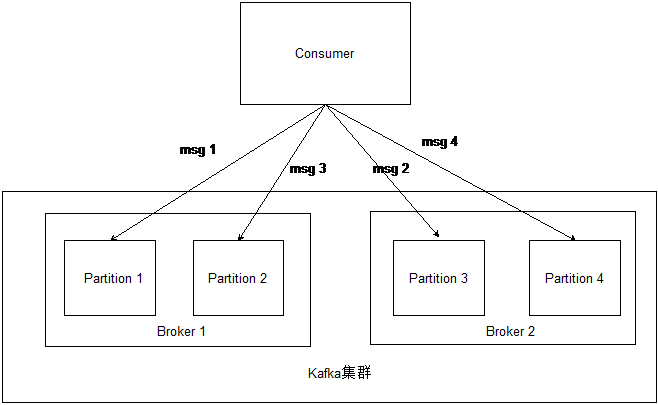
上图显示的是一个Consumer在向kafka集群发送单一topic的情况。对于这个topic,kafka集群设置了4个分区,所以Consumer发送的消息会分别发送到不同分区上。
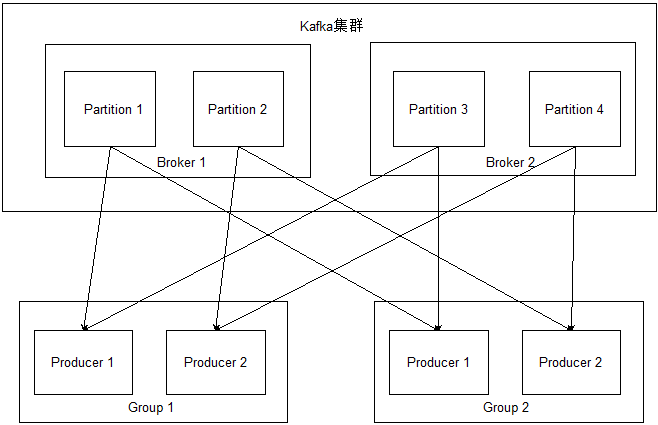
上图显示的是Producer读取kafka消息的情况。如2.3节所述,两个Group都能获得一份完整的消息。而对于每个Group内部的多个Producer,每个Producer只能获得一部分消息。同时,每个分区只会固定地向一个Producer发送消息。这样,一个Group里的多个Producer就可以并行读取数据,而不担心相互干扰,从而提高读取效率。
3.2 消息备份
为了防止集群中单点故障造成集群不可用或信息丢失,kafka中每个分区都会在其他Broker上设置备份,这个partition叫做 leader,而其备份叫做follower。当主分区所在的Broker挂掉以后,备份分区会被提升为主分区,并继续提供服务。
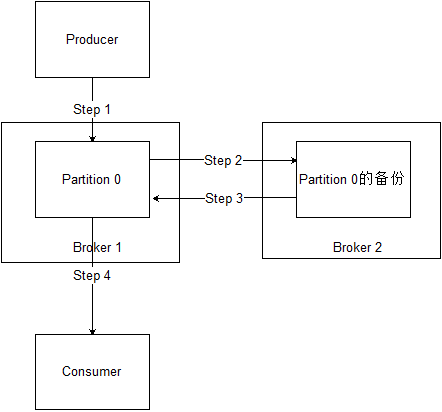
上图显示了消息备份的过程:
- Producer向kafka集群中的Broker 1的分区0的leader发送一条消息;
- 分区0把接收到的消息同步到位于Broker 2的备份分区(分区0的follower)上;
- 备份分区接收到信息,并向Broker 1发送确认信息;
- Broker 1允许Consumer来消费本消息。
3.3 消息接收与发送
3.3.1 Producer发送消息到Broker
如3.1节所述,Producer产生的消息会分散发送给各个partition。Producer会与各个partition leader所在Broker直接建立socket连接,没有直接中间路由,从而降低了网络延迟。各partition leader信息都保存在Zookeeper上,Producer直接从Zookeeper上获得各partition leader的信息。
在发送消息时,Producer客户端决定当前这条消息往哪个partition leader发送,可采用"random", "key-hash"或者"round-bin"的方式,主要目的是使消息在各partition间均衡发送。
3.3.2 Broker对消息的处理
如3.1节所述,Broker在接收到Producer发送的消息后,会按照topic和partition把消息保存在相应的目录下,物理存储形式为append log,即将获得的消息追加到log文件的末尾。当log文件达到一定大小(默认为1GB)时,Broker会另外创建一个新的log文件。
在把消息写到log文件时,Broker会先将消息存在buffer里面,当buffer中存的消息达到一定量时就会异步flush到磁盘上(即log文件中),从而提高消息落磁盘的效率;而Consumer在读取文件时,会优先去buffer中读取,若未找到相应消息,则会去log文件中寻找(这样buffer就如同一个cache)。这样,大部分消息都会直接经由内存传递,大大降低了消息的时延。
3.3.3 Consumer从Broker接收消息
Consumer以主动拉取的方式从Broker获得消息,这样Consumer可以按照自己处理消息的能力来适时获取消息。
读消息时,Consumer向Broker告知自己已经读取的进度(offset)和本次想要读取消息的数量。Broker根据这两个指标向Consumer发送消息。Consumer将offset保存在本地,并定时发往Zookeeper进行注册。因此,Broker端无需保存Consumer的状态信息,不需要做太多工作,是一个很轻量级的服务。同样,Consumer端也是很轻量级的实现。这些都保证了kafka的高效服务。
4. 一些常用操作
# 启动broker
bin/kafka-server-start.sh -daemon config/server.properties
# 关闭broker
bin/kafka-server-stop.sh
# 查看topic列表
bin/kafka-topics.sh --list --zookeeper <zk_ip>:<zk_port>
# 创建topic
bin/kafka-topics.sh --create --zookeeper <zk_ip>:<zk_port> --replication-factor 1 --partitions 1 --topic <topic_name>
# 查看topic明细
bin/kafka-topics.sh --describe --zookeeper <zk_ip>:<zk_port> --topic <topic_name>
# 修改topic配置
bin/kafka-topics.sh --zookeeper <zk_ip>:<zk_port> --partition 4 --topic <topic_name>--alter
# 删除topic
bin/kafka-topics.sh --zookeeper <zk_ip>:<zk_port> --delete --topic <topic_name>
# 启动Producer-console脚本
bin/kafka-console-producer.sh --broker-list <broker_ip>:<broker_port> --topic <topic_name>
# 启动Consumer-console脚本
bin/kafka-console-consumer.sh --zookeeper <zk_ip>:<zk_port> --topic <topic_name> --from-beginning参考文章:















 735
735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









