






1,Hashtable: key不允许为null, value不允许为null,Super是Dictionary,线程安全;
2,ConcurrentHashMap:key不允许为null,value不允许为null, Super为AbstractMap,分段锁技术;
3,TreeMap:Key不允许为null, value允许为null,Super为AbstractMap,线程不安全;
4,HashMap:Key允许为null,Value允许为null,Super为AbstractMap,线程不安全;
*存储null值时会抛出NPE异常。
二,合理利用集合有序性(sort)和稳定性(order)
说明:稳定性指集合每次遍历的元素次序是一定的。有序性是指遍历结果是按某种比较规则依次排列的。
如:ArrayList是无序,稳定的;HashMap是无序,不稳定的;TreeSet是有序,稳定的。
三,利用Set元素唯一性,可以快速对一个集合进行去重操作,避免使用List的Contains方法进行遍历,对比,去重。
异常分类:分为检测异常和非检查异常,但是在实际中又混淆了这两种异常的应用。由于非检测异常使用方便,很多开发人员就认为检测异常没什么用处。其实异常的应用情景可以概括为以下:
1.调用代码不能继续执行,需要立即终止。出现这种情况的可能性太多。例如服务器连接不上,参数不正确等。这些时候都适用非检测异常,不需要调用代码的显式捕捉和处理,而且代码简洁明了。
2.调用代码需要进一步处理和恢复。假如将SQLException定义为非检测异常,这样操作数据时开发人员理所当然的认为SQLException不需要调用代码的显式捕捉和处理,进而导致严重的Connection不关闭,Transaction不回滚、DB中出现脏数据等情况,正因为SQLException定义为检测异常,才会驱使开发人员去显式捕捉,并且在代码产生异常后清理资源。当然清理资源后,可以继续抛出非检测异常,阻止程序的执行。根据观察和理解,检测异常大多可以应用于工具类中。
Java中的垃圾收集- GC参考手册。
标记*清除(Mark and Sweep)是最经典的垃圾收集算法。将理论用于生产实践时,会有很多需要优化调整的地点,以适应具体环境。
碎片整理(Fragmenting and Compacting)
每次执行清除(sweeping),JVM都必须保证不可达对象占用的内存能被回收重用。但这(最终)有可能会产生内存碎片(类似于磁盘碎片),进而引发两个问题:
1),写入操作越来越耗时,因为寻找一块足够大的空闲内存会变得非常麻烦。
2),在创建新对象时,JVM在连续的块中分配内存。如果碎片问题很严重,直至没有空闲片段能存放下新创建的对象,就会发生内存分配错误(allocation error)。
要避免这类问题,JVM必须确保碎片问题不可控。因此在垃圾收集过程中,不仅仅是标记和清除,还需要执行“内存碎片整理”过程。这个过程让所有可达对象(reachable objects)依次排列,以消除(或减少)碎片。
说明: JVM中的引用时一个抽象的概念,如果GC移动某个对象,就会修改(栈和堆中)所有指向该对象的引用。移动/提升/压缩 是一个STW的过程,所以修改对象引用是一个安全的行为。
分代假设(Generational Hypothesis)
func main(){
if len(os.Args) != 2{
fmt.Fprintf(os.Stderr, "Usage: %s host:port", os.Args[0])
os.Exit(1)
}
service := os.Args[1]
tcpAddr, _ := net.ResolveTCPAddr("tcp4", service);
conn,_ := net.DialTCP("tcp", nil, tcpAddr);
话说可以直接走HTTP的包吗?不应该包装成TCP的包?还是系统帮你包装了
_, _= conn.Write([]byte("HEAD /HTTP /1.0\r\n\r\n"));
result,_ := ioutil.ReadAll(conn)
fmt.Println(string(result))
os.Exit(0)
}
TCP Server
1,绑定服务到指定端口 fun ListenTCP(net string, laddr * TCPAddr)(1 * TCPListener, err os.Error)
2,监听端口func(1 * TCPListener) Accept()(c Conn, err os.Error)
service := ":7777"
tcpAddr, _ := net.ResolveTCPAddr("tcp4", service)
listener, _ := net.ListenTCP("tcp", tcpAddr);
for{
conn, err := listener.Accept()
if err != nil{
continue
}
daytime := time.Now().String()
conn.Write([]byte(daytime))
conn.Close();
}
并发版本:-----------------------------------------------------------------------
func main(){
service := ":1200"
tcpAddr, _:=net.ResolveTCPAddr("tcp4", service);
listener, _ := net.ListenTCP("tcp", tcpAddr);
for{
conn. err := listener.Accept()
if err != nil{
continue;
}
go handleClient(conn);
}
}
func handleClient(conn net.Conn){
defer conn.Close()
daytime := time.Now().String()
conn.Write([]byte(daytime))
}
读取客户端请求,并保持长连接版本:------------------------------------------------------------------
func handleClient(conn net.Conn){
conn.SetReadDeadline(time.Now().Add(2 * time.Minute))
request := make([]byte, 128)
defer conn.Close();
for{
read_len, err := conn.Read(request)
if err != nil{
fmt.Println(err)
break
}
if read_len ==0 {
break
}else if strings.TrimSpace(string(request[:read_len])) == "timestamp"{
daytime := strconv.FormatInt(time.Now().Unix(), 10)
conn.Write([]byte(daytime))
}else{
daytime := time.Now().String()
conn.Write([]byte(daytime))
}
request = make([]byte, 128)
}
}
--------------------------------WEB服务器工作模型------------------------------------------
1,多进程方式: 为每个请求启动一个进程来处理。单个进程问题不会影响其他进程,因此稳定性最好。性能最差。
2,一个进程中 用多个线程处理用户请求。线程开销明显小于进程,而且部分资源还可以共享,但是线程切换快可能造成线程抖动,且线程过多会造成服务器不稳定。
3,异步方式: 使用非阻塞方式处理请求。一个进程或线程处理多个请求,不需要额外开销,性能最好,资源占用最低。但是可能有一个请求占用过多资源,其他请求得不到响应,一个进程或线程处理多个请求,不需要额外开销,性能最好,资源占用最低。
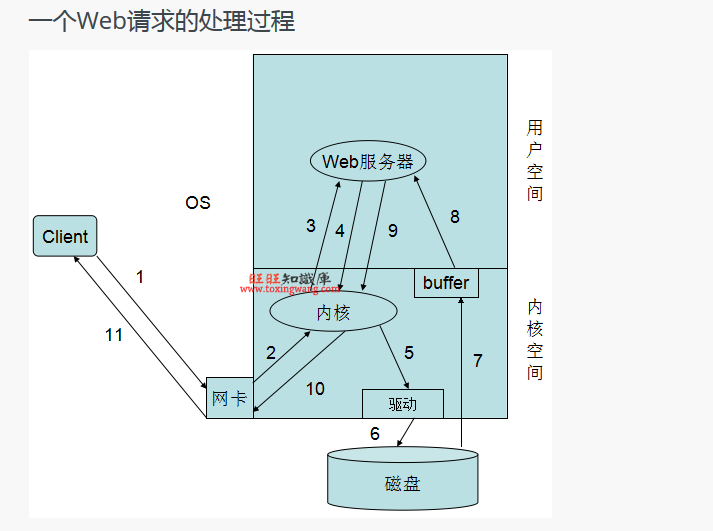
用户请求>送达给用户空间>系统调用>内核空间>内核到磁盘上读取网页资源>返回到用户空间>响应给用户。这里面有两个I/O过程,一个是客户端请求的网络i/o,另一个就是Web服务器请求页面的磁盘I/O。
1,客户发起请求;
2,服务器网卡接收到请求后转交给内核处理;
3,内核根据请求对应的套接字,将请求交给工作在用户空间的Web服务器进程;
4,Web服务器进程根据用户请求,向内核进行系统调用,申请获取相应资源(如index.html);
5,内核发现web服务器进程请求的是一个存放在硬盘上的资源,因此通过驱动程序连接磁盘内核调度磁盘,获取需要的资源。
6,内核将资源存放在自己的缓冲区中,并通知Web服务器进程。
7,Web服务器进程通过系统调用取得资源,并将其复制到进程自己的缓冲区中。
8,Web服务器进程形成响应,通过系统调用再次发给内核以响应用户请求;
9,内核将响应发送至网卡;
10,网卡发送响应给用户;
用户空间的web服务器进程是无法直接操作io的,需要通过系统调用进行。
----------|___>wait___>|-----------|___>copy___>|----------|
I/O Device| |内核buffer | |用户态进程|
----------|<___________|-----------|<___________|----------|
1,进程向内核进行系统调用申请IO。
2,内核将资源从IO/DEVICE调度到内核的buffer中。(wait阶段)
3,内核还需将数据从内核buffer中复制(copy阶段)到Web服务器进程所在的用户空间,才算完成一次IO调度。
这几个阶段都是需要时间的。根据wait和copy阶段的处理等待的机制不同。可将I/O动作分为如下五种模式:
1),阻塞I/O:所有过程都阻塞。
2),非阻塞I/O:如果没有数据buffer,则立即返回 EWOULDBLOCK ;
3),I/O复用: 在wait和copy阶段分别阻塞。
4),信号(事件)驱动I/O: 在wait阶段不阻塞,但copy阶段阻塞(信号驱动I/O,即通知)
5),异步I/O, AIO。















 2904
2904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









