






正则
什么是正则
正则就是一串有规律的字符串
掌握好正则对于编写shell脚本有很大帮助
各种编程语言中都有正则,原理是一样的
本章将要学习grep/egrep、sed、awk
grep //过滤指定关键词
grep [-cinvABC] 'word' filename
创建grep目录,将/etc/passwd拷贝到当前目录
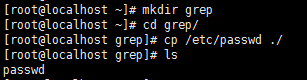
grep 'word' filename //过滤出指定的关键词的行
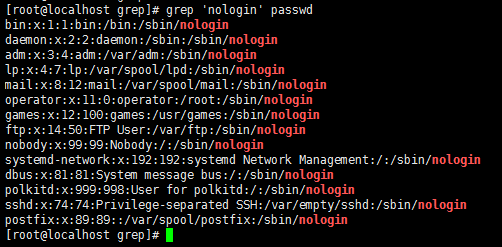
-c //行数,显示出过滤关键词的行号

-i //不区分大小写,不区分过滤词的大小写
编辑passwd,更改为大写字母
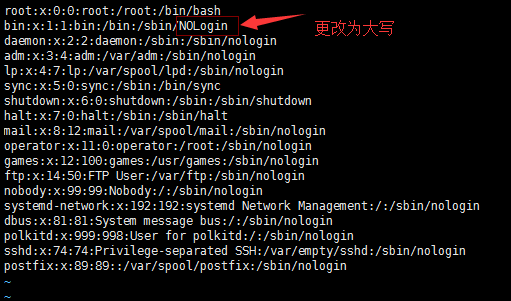
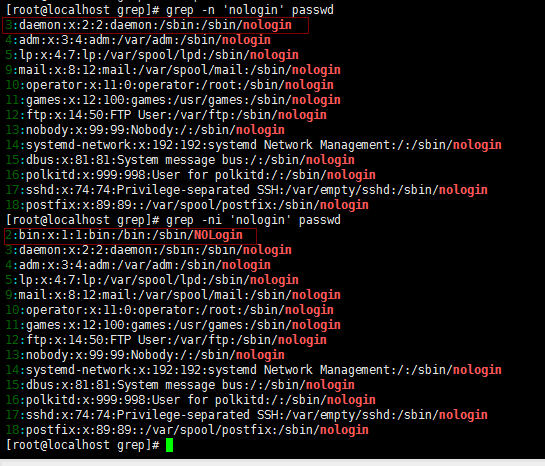
-n //显示行号,显示过滤出关键词的行号
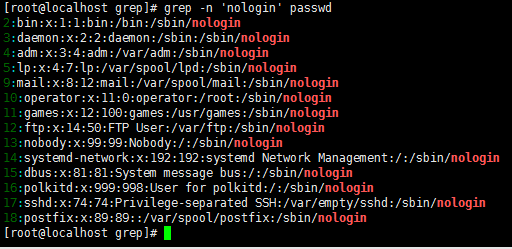
-v //取反,过滤出除关键词之外的行

-r 遍历所有子目录
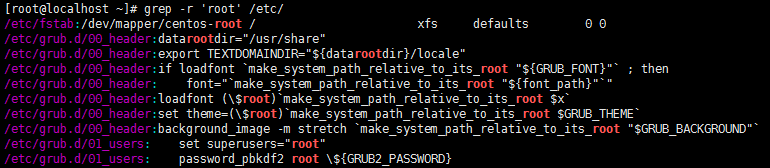
-A 后面跟数字,过滤出符合要求的行以及下面n行
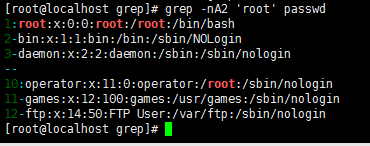
-B 后面跟数字,过滤出符合要求的行以及上面n行
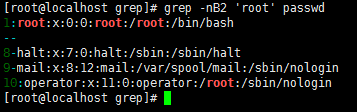
-C 后面跟数字,同时过滤出符合要求的行以及上下各n行
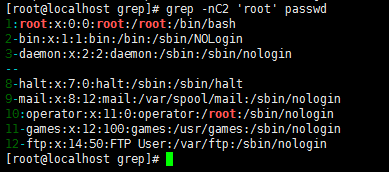
grep '[0-9]' passwd //过滤出包含0-9中任意一个字符的行
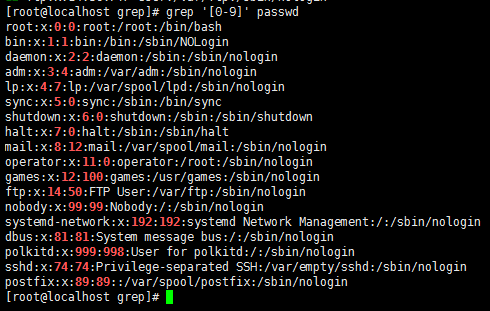
grep -v '[0-9]' /etc/inittab //过滤出不包含数字的行
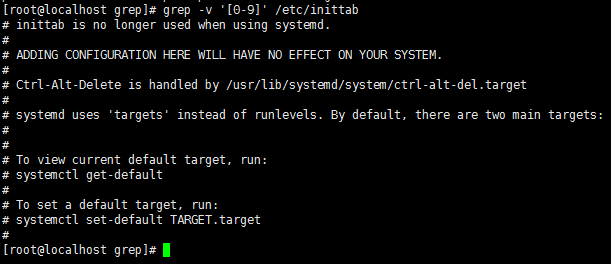
grep -v '^#' inittab //过滤出不以#开头的行
拷贝/etc/inittab到当前目录,编辑该文件,增加一行字符串
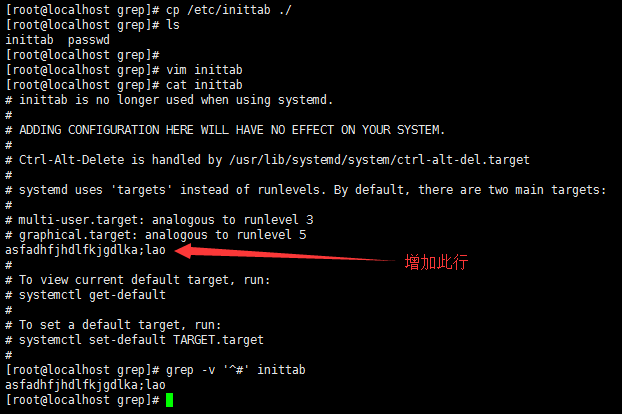
编辑inittab文件,增加空行及字符串
grep -v '^#' inittab //过滤掉以#开头的行
grep -v '^#' inittab |grep -v '^$' //过滤掉以#开头的行和空行
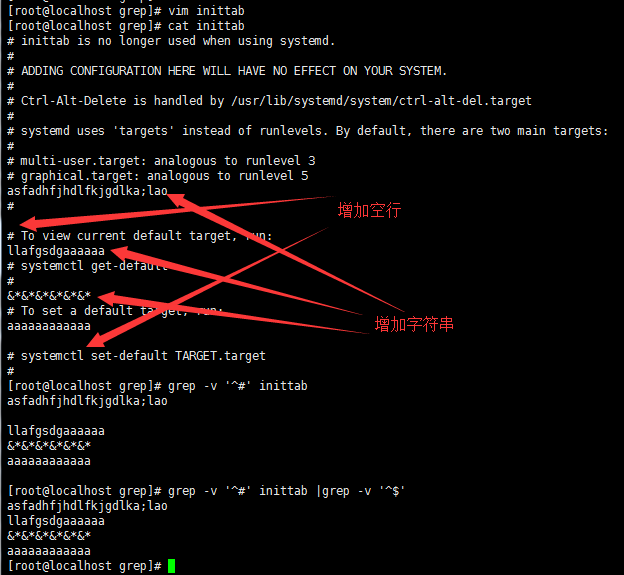
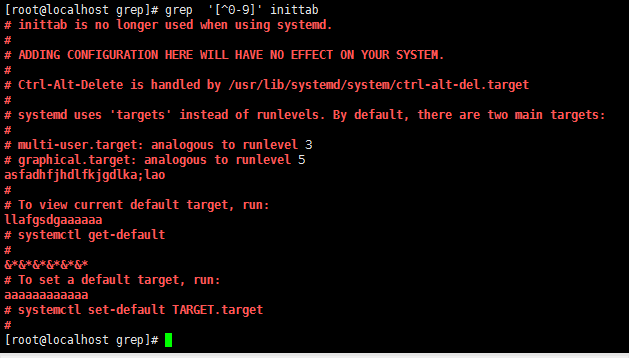
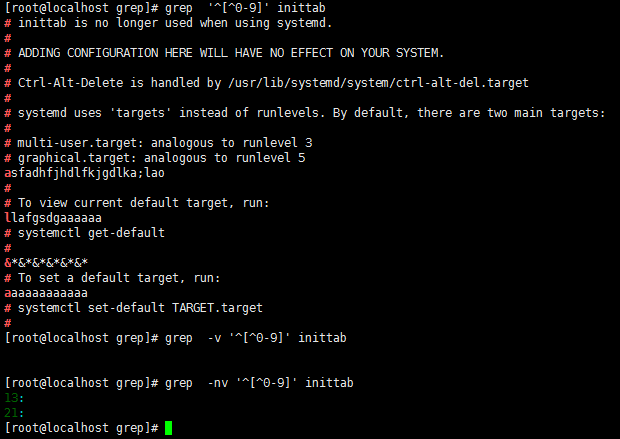
grep '[^0-9]' inittab //非0-9的任意一个字符都匹配
grep '^[^0-9]' inittab //以非0-9开头的字符都匹配,[ ]里面的^是取反,外面的^是以[ ]里面的内容开头
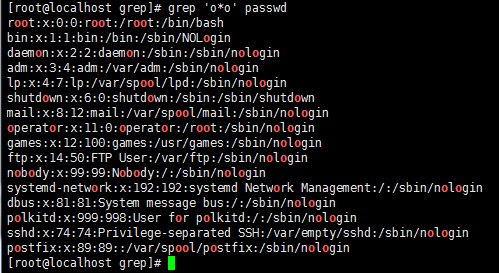
grep 'r.o' passwd //.代表任意一个字符

grep 'o*o' passwd //和*左边的字符重复0到n个,匹配右边o结尾的字符
grep 'root.*bash' passwd //过滤出指定的行

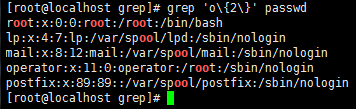
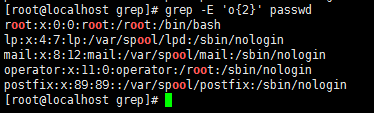
grep 'o\{2\}' /passwd //过滤出出现2次o的行
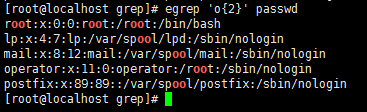
或者 egrep 'o{2}' passwd == grep -E 'o{2}' passwd
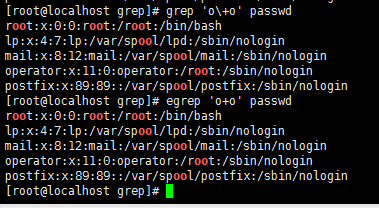
grep 'o\+o' passwd
或者 egrep 'o+o' passwd //和+左边的字符重复1到n个
egrep 'o?g' passwd 或者
grep -E 'o?g' passwd //匹配?前面的字符的0个或者1个
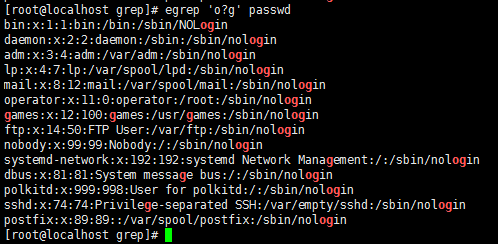
grep -E 'root|nologin' passwd //过滤出root的行或者nologin的行
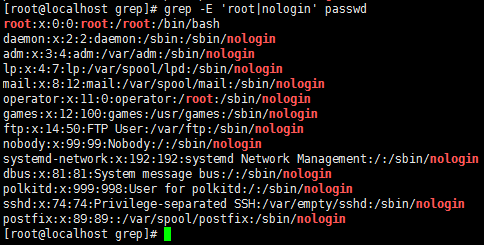
egrep '(oo){2}' passwd //过滤出2对oo的行

sed
sed -n '/root/'p test.txt //打印指定关键词的行
![]()
sed -n '5'p test.txt //打印指定行数

sed -n '2,5'p test.txt //指定打印行数的范围
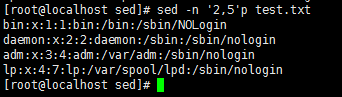
sed -n '1,$'p test.txt //打印第一行到最后一行
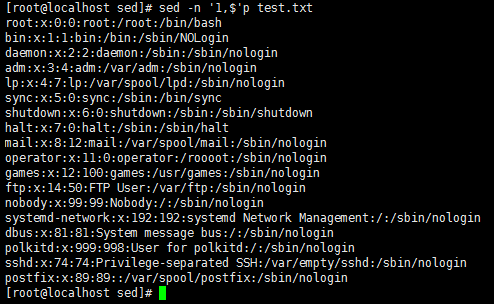
sed -n '/o\+t/'p test.txt 或者
sed -nr '/o+t/'p test.txt //和+左边的字符重复1到n个,加r参数无需加转义符
sed -e '1'p -e '/root/'p -n test.txt // -e参数,多次匹配

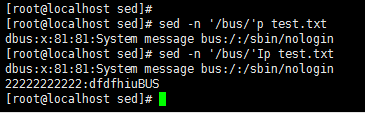
sed -n '/bus/'p test.txt //打印出指定关键词的行,加I参数,同时显示大写字符
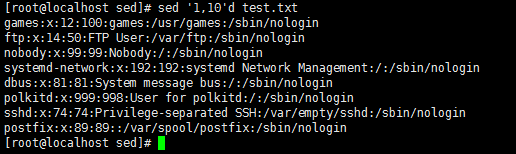
sed '1,10'd test.txt //删除指定的行,并打印出剩下的行,不是真正的删除
sed -i '1,15'd test.txt //-i参数,直接删除指定的行

sed -i '/sbin/'d test.txt //指定字符串删除所在行

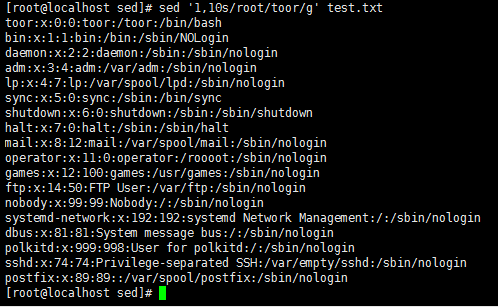
sed '1,10s/root/toor/g' test.txt //指定范围,将root替换为toor
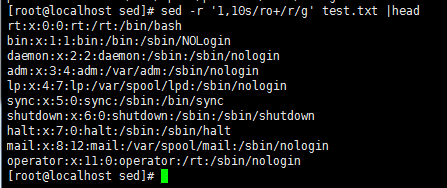
sed -r '1,10s/ro+/r/g' test.txt |head //替换正则,需加-r参数
head test.txt |sed -r 's/([^:]+):(.*):([^:]+)/\3:\2:\1/' //前10行的第一段替换最后一段
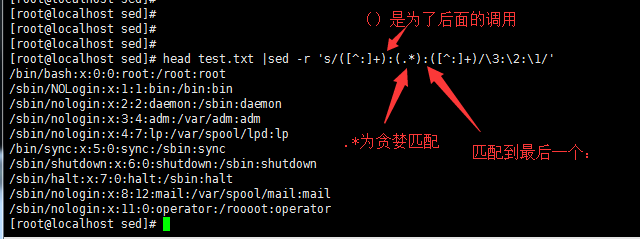
head test.txt |sed 's/\/root/123/g' //将/root替换为123,/root前面必须加转义符
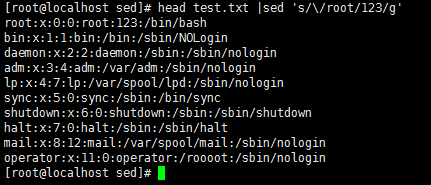
head test.txt |sed 's/\/sbin\/nologin/123/g'
或者 head test.txt |sed 's@/sbin/nologin@123@g' //将/sbin/nologin替换为123
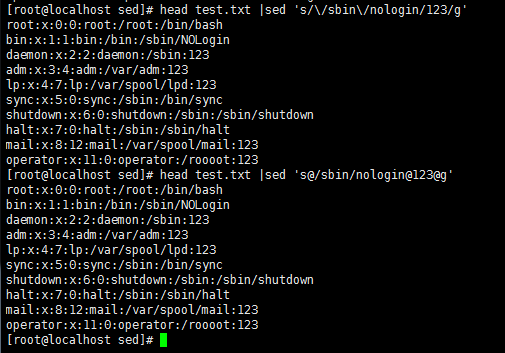
head test.txt |sed 's/[a-zA-Z]//g' //删除文档中的所有英文字母
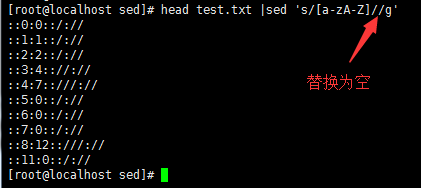
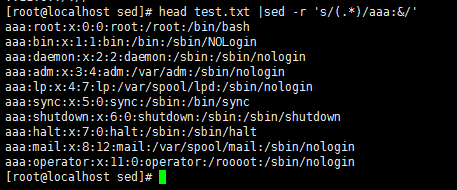
head test.txt |sed -r 's/(.*)/aaa:&/' //在所有行的前面加上字符串
awk
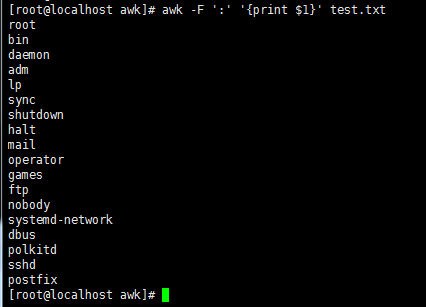
awk -F ':' '{print $1}' test.txt //指定分割符,打印第一段,不会更改原文件内容
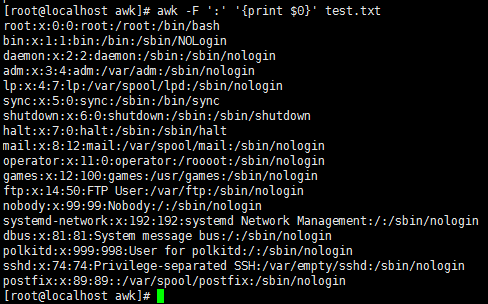
awk -F ':' '{print $0}' test.txt //指定分割符,$0打印所有的段
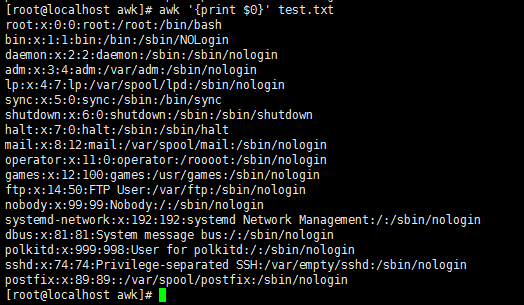
awk '{print $0}' test.txt //打印所有内容
awk '{print $1}' 1.txt // 忽略-F,没有指定分割符,默认会以空格或者空白字符为分隔符打印
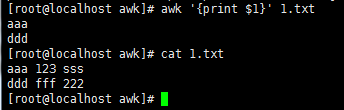
awk -F ':' '{print $1,$3,$4}' test.txt //打印多段,直接用,
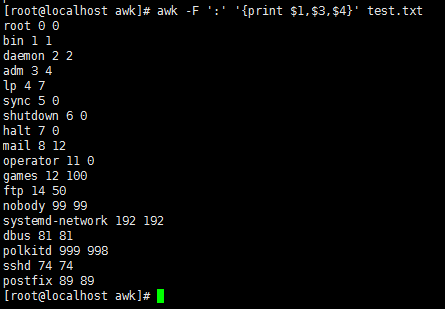
awk -F ':' '{print $1"#"$3"#"$4}' test.txt //指定符号分割
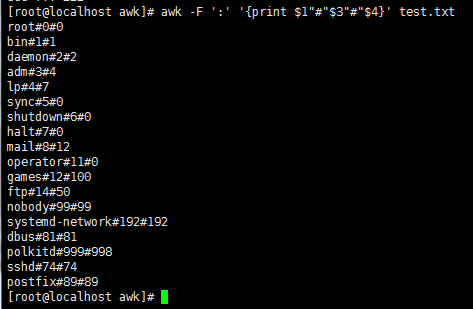
awk '/oo/' test.txt //匹配,打印包含oo的行

awk -F ':' '$1 ~ /oo/' test.txt //指定第一段包含有oo的行
awk -F ':' '$1 ~ /o+/' test.txt //指定第一段包含有一个o及以上的行,无需加任何参数
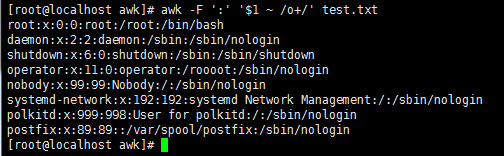
awk -F ':' '/root/ {print $1,$3} /mail/ {print $1,$3,$4}' test.txt //支持多个表达式一起写,同时打印出包含root和mail的行指定的段
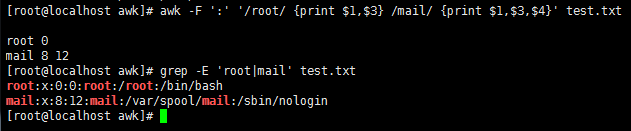
awk -F ':' '/root|mail/ {print $0}' test.txt //同时打印出包含root和mail的行

awk -F ':' '$3==0' test.txt //打印出数值等于0的行

awk -F ':' '$3==0 {print $1}' test.txt //打印出数值等于0的行的第一段

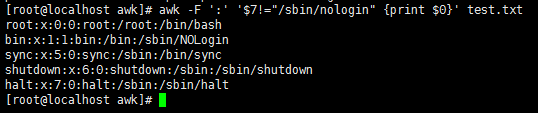
awk -F ':' '$3>=100 {print $0}' test.txt //打印出数值大于等于100的所有行

awk -F ':' '$3>="100" {print $0}' test.txt //数字加上双引号默认为字符串
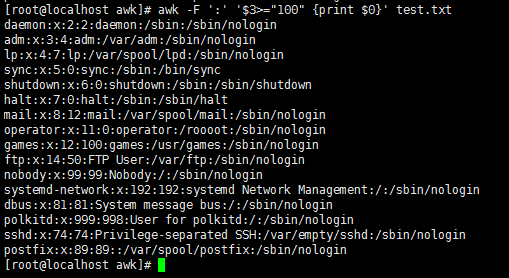
awk -F ':' '$7!="/sbin/nologin" {print $0}' test.txt //打印出第7段不包含/sbin/nologin的行
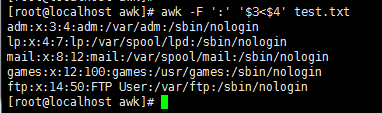
awk -F ':' '$3<$4' test.txt //字段大小比较
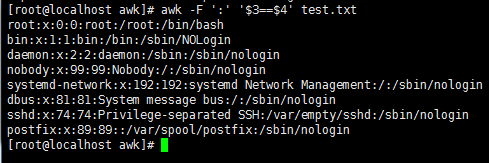
awk -F ':' '$3==$4' test.txt //第三段等于第四段的行
awk -F ':' '$3>"5" && $3<"7"' test.txt //第三段的字符串大于5并且小于7的行

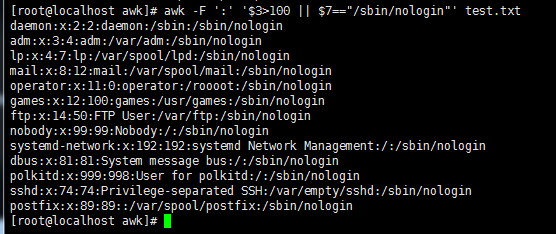
awk -F ':' '$3>100 || $7=="/sbin/nologin"' test.txt //第三段大于100,或者第七段为/sbin/nologin的行
awk -F ':' '$3>100 || $7 ~ /bash/' test.txt //第三段大于100,或者匹配第七段包含bash的行

awk -F ':' '{OFS="#"} $3>100 || $7 ~ /bash/ {print $1,$3,$7}' test.txt //OFS指定print输出后的分隔符

awk -F ':' '{OFS="#"} {print $1,$3,$7}' test.txt //不指定条件,输出全部
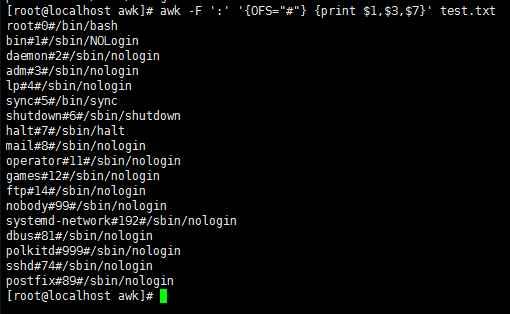
awk -F ':' '{OFS="#"} {if ($3>100) {print $1,$2,$3,$4}}' test.txt //if为条件判断,表示如果第三段大于100,则打印出该行的1-4段,并用#作为分隔符

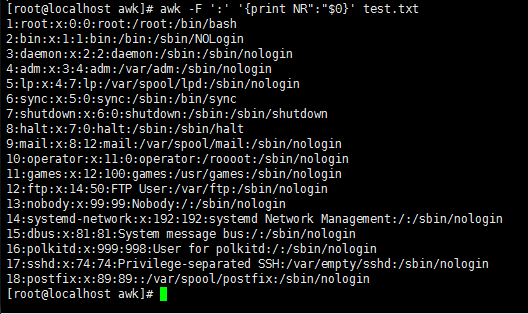
awk -F ':' '{print NR":"$0}' test.txt //NR参数打印显示所有行数
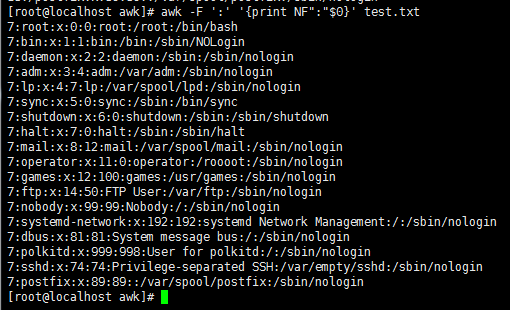
awk -F ':' '{print NF":"$0}' test.txt //NF参数打印显示所有行的段数
awk -F ':' 'NR<=10' test.txt //打印出1到10行
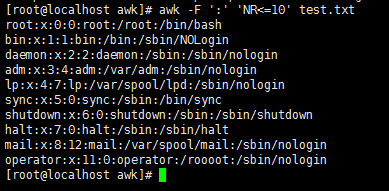
awk -F ':' 'NR<=10 && $1 ~ /root|sync/' test.txt //打印出1到10行,并且第一段包含root或者sync的行

awk -F ':' 'NR<=10 && $1 ~ /root|sync/' test.txt //使用$符号,表示从第一段开始
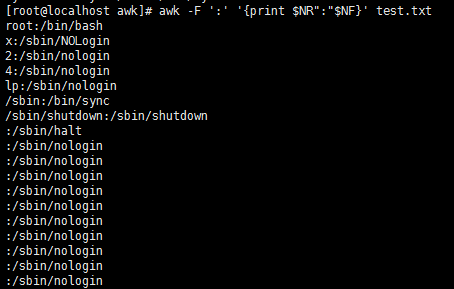
head -n 3 test.txt |awk -F ':' '$1="root"' //将前三行的第一段赋值为root
head -n 3 test.txt |awk -F ':' '{OFS=":"} $1="root"' //定义打印出的分隔符

awk -F ':' '{(tot=tot+$3)}; END {print tot}' test.txt //tot每次循环都会把第三段的值相加,tot默认从0开始,求和第三段的值
















 150
150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









