






在基于前面的基础爬虫,实现分布式的爬虫
节点管理,需要四个队列进行通信
- url_queue: URL管理进程将URL传递给爬虫节点的通道
- result_queue: 用于数据处理进程获取数据的通道
- conn_queue: 数据处理进程将新的URL传递给 URL管理进程的通道
- store_queue: 数据处理进程将数据传递给数据存储进程的通道
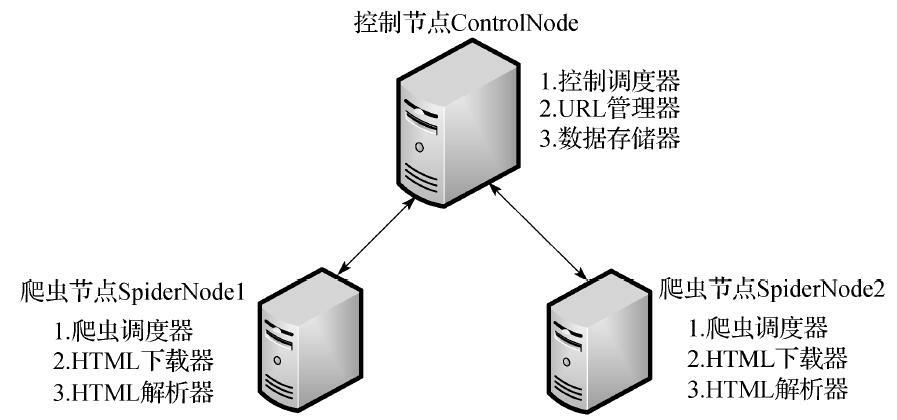
多个进程协调进行工作
- url_manager_proc进程: 两个作用:一是将url放入 url_queue队列,让工作节点获取url。二是将数据处理进程提取的urls集合存放到 URLS集合中去
- result_solve_proc 进程:1. 获取数据后(result_queue.get() )将数据存放到 store_queue给数据存储进程使用。2. 将urls存放到conn_queue给url_manager_proc进程使用
- store_proc 进程:将数据存储到文件或者数据库中

NodeManager.oy:
from multiprocessing import Queue, Process
from multiprocessing.managers import BaseManager
import time
from DataOutput import DataOutput
from URLManager import UrlManager
class NodeManager(object):
def start_manager(self, url_que, result_que):
'''
创建分布式管理器
:param url_que: url队列
:param result_que: 结果队列
:return: 返回管理器对象
'''
# 将队列注册到网络上
BaseManager.register('get_task_queue', callable=lambda: url_que)
BaseManager.register('get_result_queue', callable=lambda: result_que)
manager = BaseManager(address=('', 8000), authkey='123'.encode('utf-8'))
return manager
def url_manager_proc(self, url_que, conn_que, root_url):
url_manager = UrlManager()
url_manager.add_new_url(root_url)
while True:
while url_manager.has_new_url():
new_url = url_manager.get_new_url()
# 将新的url发给工作节点
url_que.put(new_url)
print('old_url=', url_manager.old_urls_size())
if url_manager.old_urls_size()>2000:
url_que.put('end')
print('控制节点发出结束通知')
# 关闭管理节点,同时存储set状态
url_manager.save_progress('new_urls.txt', url_manager.new_urls)
url_manager.save_progress('old_urls.txt', url_manager.old_urls)
return
# 将从result_solve_proc 获取的urls添加到URL管理器
try:
if not conn_que.empty():
urls = conn_que.get()
for url in urls:
url_manager.add_new_url(url)
except BaseException:
time.sleep(0.1)
def result_solve_proc(self, result_que, conn_que, store_que):
while True:
try:
if not result_que.empty():
content = result_que.get(True)
if content['new_urls'] == 'end':
# 结果分析进程接收通知然后结束
print('结果分析进程接收通知然后结束')
store_que.put('end')
return
conn_que.put(content['new_urls']) # url为set类型
store_que.put(content['data']) # 解析的数据为dict类型
else:
time.sleep(0.1)
except BaseException as e:
time.sleep(0.1)
def store_proc(self, store_que):
out = DataOutput()
while True:
if not store_que.empty():
data = store_que.get()
if data == 'end':
print('存储进程接收通知结束')
out.ouput_end(out.filepath)
return
out.store_data(data)
else:
time.sleep(0.1)
if __name__ == '__main__':
url_que = Queue()
result_que = Queue()
store_que = Queue()
conn_que = Queue()
node = NodeManager()
manager = node.start_manager(url_que, result_que)
# 创建URL管理进程, 数据提取进程, 数据存储进程
url_manager_proc = Process(target=node.url_manager_proc,
args=(url_que, conn_que, 'http://baike.baidu.com/view/284853.htm'))
result_solve_proc = Process(target=node.result_solve_proc, args=(result_que, conn_que, store_que))
store_proc = Process(target=node.store_proc, args=(store_que, ))
# 启动进程和分布式管理器
url_manager_proc.start()
result_solve_proc.start()
store_proc.start()
manager.get_server().serve_forever()















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









