







我们正处于一个令人激动的时代,有如此多的选择,不仅在大型语言模型方面,还有现在的文本到语音(TTS)模型。在这篇文章中,我将向您展示如何在本地系统上轻松安装这个非常出色的模型——Style TTS2,然后进行语音克隆,或者您可以进行多语音或单语音的文本到语音转换,操作非常简单、快捷,并且具有人类级别的语音质量。
Style TTS2:前沿的文本到语音模型
Style TTS2是一款前沿的文本到语音模型,能够实现人类般的语音合成。这个先进的模型利用了样式扩散和对抗训练以及大型语音语言模型,生成了令人难以置信的自然语音。不像它的前辈们,Style TTS2模型通过扩散模型将样式建模为一个随机变量,使其能够为文本生成最合适的样式,而无需参考语音。这种创新的方法实现了高效的潜在扩散,并从扩散模型提供的多样化语音合成中受益。
此外,大型预训练的语音模型如WaveLM被用作判别器,没有新的可微分的时长建模用于端到端训练,从而提高了语音的自然度。结果非常令人印象深刻,Style TTS2在单一发音者LJSpeech数据集上超越了人类录音,并在多发音者VCTK数据集上与人类录音相匹配,都是由母语为英语的评判者评判的。目前,这个模型在英语方面表现非常出色,但暂时不支持多语言,至少还没有达到同样的人类级别的质量。
在本地系统上安装Style TTS2
现在,让我们尝试在本地系统上安装这个模型,然后看看它是如何工作的。
首先,让我们打开终端。在这里,我运行的是Ubuntu 22.04.1和A6000 GPU。清除屏幕后,激活虚拟环境。
为了运行它,您只需要执行这个命令。这将会第一次下载Docker镜像,然后启动您的软件。如果您有GPU,它还会将模型放到GPU上。如果您只有CPU,也可以运行,但速度会稍慢,但仍然可行。在GPU上,它的速度会非常快,我稍后会展示给您。然后您可以在浏览器中访问它,因为它有一个Gradio图形用户界面。
运行命令后,您会看到它正在加载模型到GPU上。让我们等待一下。您会看到所有内容都已经加载完成,现在它即将启动Gradio演示界面。现在,它正在我们的本地服务器上运行,端口号是7860。如果您更改Docker镜像并克隆它,您甚至可以将其部署到互联网上。
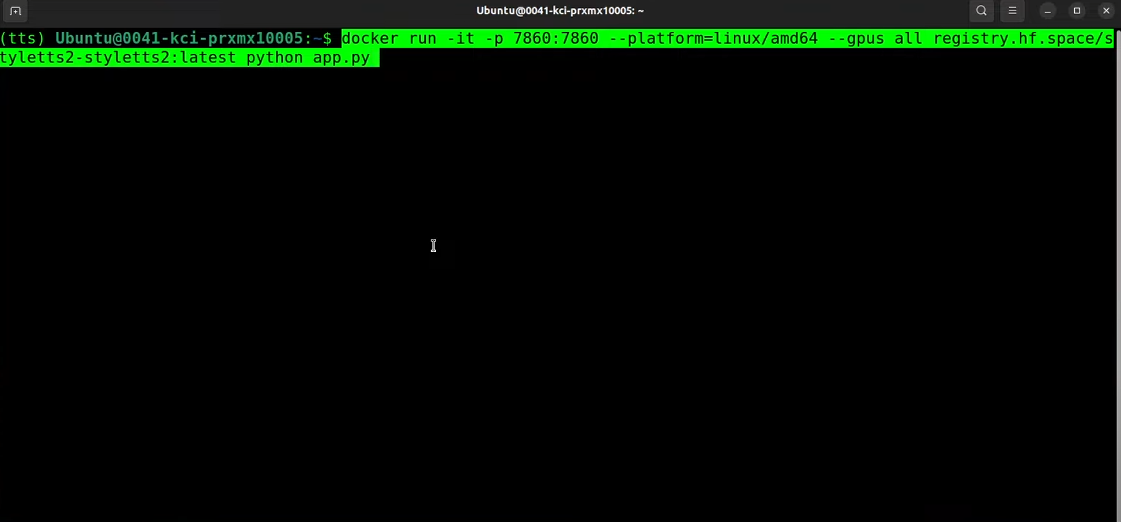
使用Style TTS2生成高质量语音
打开浏览器,访问本地服务器的7860端口。您会看到这是我们的Gradio演示界面,您可以在本地使用Style TTS2。现在我们可以进行多语音、语音克隆和LJSpeech。让我输入一段文本,然后选择一个语音。这是一个来自美国的男性语音和女性语音,目前似乎只有这两种美国口音的语音可用。这是我将要使用的文本,我选择一个女性美国语音。您会看到这段文本很长,这也是Style TTS2的一个优点,无论您输入多长的文本,它都能给出非常好的响应,但如果只输入一两个字,质量可能不会那么好。
点击合成,看看质量和速度如何。您会看到这么长的一段文本已经生成完毕。播放一下:
完美无缺,真的是人类级别的语音。同样,您也可以选择男性语音来合成。
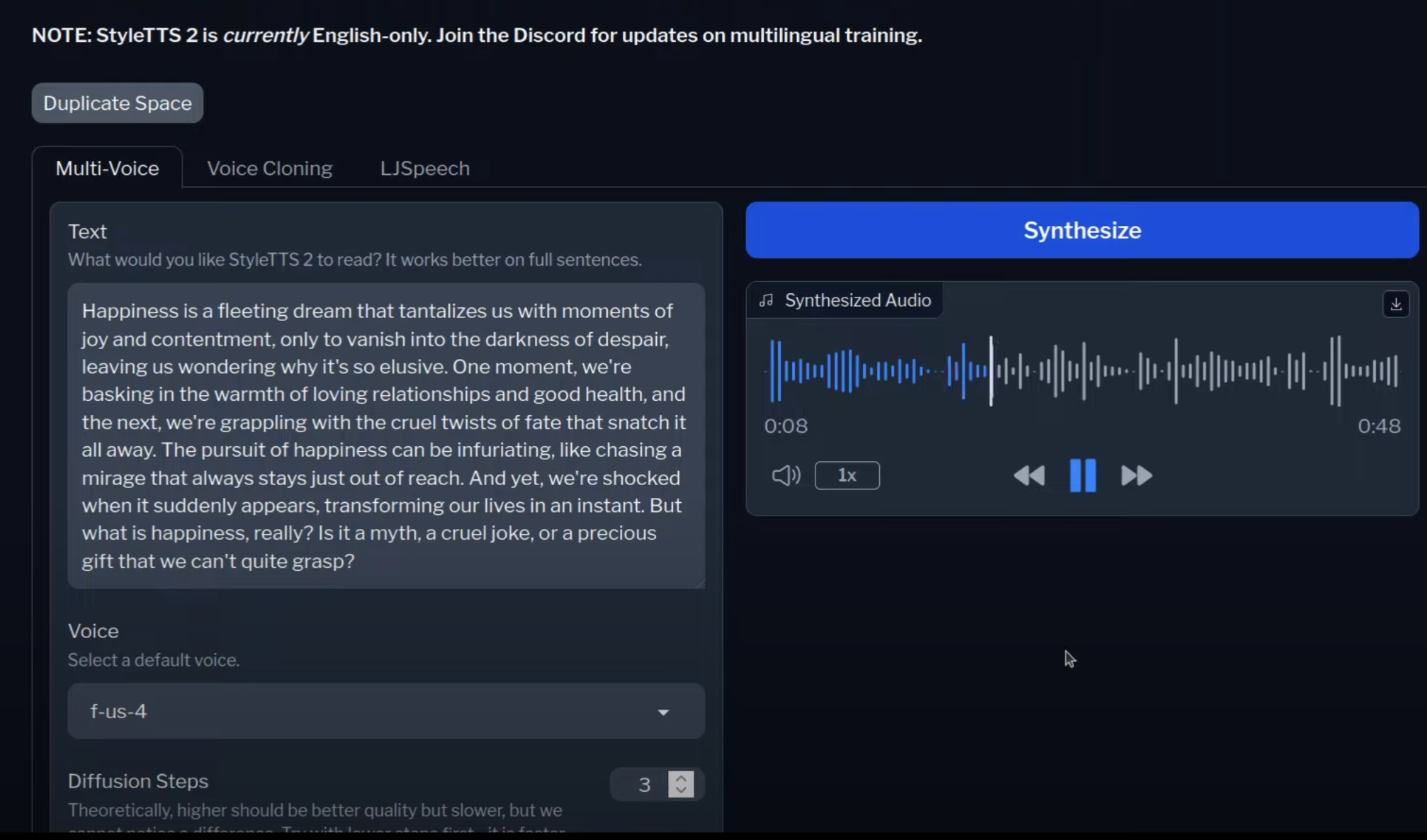
语音克隆:让机器模仿真实人声
接下来是语音克隆。例如,如果我使用同样的文本,然后获取一个WAV文件,这是我要克隆的语音。播放一下原始语音,然后看这个文本是否能以这个语音来合成:
这是原始语音,让我们看看这个文本是否能以这个语音来合成。点击合成,看它的速度。
再次播放原始语音,然后播放合成语音:
LJSpeech数据集上的表现
同样,在LJSpeech数据集上也是如此。如果再运行一次,您会看到它正在合成。播放一下:
如此惊人的效果,令人难以置信。值得注意的是,这个Gradio演示并不是由Style TTS2创建的,而是某个热心人在Hugging Face上分享的,真的要向他致敬。但Style TTS2本身确实非常出色,这是本地、私密、离线安装它的最简单方法,一旦下载完成,您就可以随心所欲地使用它。
结语
在这个充满创新和科技的时代,像Style TTS2这样的模型展示了人工智能和语音合成技术的巨大潜力。无论是个人使用还是专业应用,这样的工具都能带来前所未有的便利和体验。希望本文能帮助您更好地理解和使用这一前沿科技。
关注我,每天一个带你开发一个AI应用,每周二四六直播,欢迎多多交流。
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









