







VC调试方法大全
一、调试基础
调试快捷键
F5: 开始调试
Shift+F5: 停止调试
F10: 调试到下一句,这里是单步跟踪
F11: 调试到下一句,跟进函数内部
Shift+F11: 从当前函数中跳出
Ctrl+F10: 调试到光标所在位置
F9: 设置(取消)断点
Alt+F9: 高级断点设置
跟踪调试
1、 尽量使用快捷键时行调试
2、 观察调试信息
3、 高级中断设置
异常调试
重试->取消->调试
函数堆栈,用variables或者call stack 窗口
Release调试
1、 经常测试你的Debug和Release版本
2、 不要移除调试代码,如用ASSERT, TRACE等。
3、 初始化变量,特别是全局变量,malloc的内存,new的内存
4、 当你移除某个资源时,确保你移除了所有跟这个资源相关的申明(主要是在resouce.h文中)
5、 使用3或者4级的警告级编译你的代码,并确保没有警告,project->setting->c/c++->warninglevel(中文版是项目->属性->C/C++->常规->警告等级)
6、 _debug改成NDEBUG进行调试,project->setting->C/C++->Preprocessordefinitions(中文版是项目->属性->C/C++->预处理器->预处理定义)(这里是debug和Release编译的重要不同之一)
7、 在Release中调试源代码,project->setting->C/C++->debug info选择programDataBase(中文版是项目->属性->C/C++->常规->调试信息格式->用于“编辑并继续”的程序数据库),project->setting->link选上Generate debug info(中文版是项目->属性->链接器->调试->生成调试信息)
8、 走读代码,特别关注堆栈和指针
二、TRACE宏
当选择了Debug目标,并且afxTraceEnabled变量被置为TRUE时,TRACE宏也就随之被激活了。但在程序的Release版本中,它们是被完全禁止的。下面是一个典型的TRACE语句:
…
int nCount =9;
CString strDesc("total");
TRACE("Count =%d,Description =%s\n",nCount,strDesc);
…
可以看到,TRACE语句的工作方式有点像C语言中的printf语句,TRACE宏参数的个数是可变的,因此使用起来非常容易。如果查看MFC的源代码,你根本找不到TRACE宏,而只能看到TRACE0、TRACE1、TRACE2和TRACE3宏,它们的参数分别为0、1、2、3。
个人总结:最近看网络编程是碰到了TRACE语句,不知道在哪里输出,查了一晚上资料也没找出来,今天终于找到了,方法如下:
1.在MFC中加入TRACE语句
2.在TOOLS->MFCTRACER中选择 “ENABLE TRACING”点击OK
3.进行调试运行,GO(F5)(特别注意:不是执行‘!’以前之所以不能看到TRACE内容,是因为不是调试执行,而是‘!’了,切记,切记)
4.然后就会在OUTPUT中的DEBUG窗口中看到TRACE内容了,调试执行会自动从BUILD窗口跳到DEBUG窗口,在那里就看到TRACE的内容了,^_^
以下是找的TRACE的详细介绍:
==============================
TRACE宏对于VC下程序调试来说是很有用的东西,有着类似printf的功能;该宏仅仅在程序的DEBUG版本中出现,当RELEASE的时候该宏就完全消失了,从而帮助你调式也在RELEASE的时候减少代码量。
使用非常简单,格式如下:
TRACE("DDDDDDDDDDD");
TRACE("wewe%d",333);
同样还存在TRACE0,TRACE1,TRACE2。。。分别对应0,1,2。。个参数
TRACE信息输出到VC IDE环境的输出窗口(该窗口是你编译项目出错提示的哪个窗口),但仅限于你在VC中运行你的DEBUG版本的程序。
TRACE信息还可以使用DEBUGVIEW来捕获到。这种情况下,你不能在VC的IDE环境中运行你的程序,而将BUILD好的DEBUG版本的程序单独运行,这个时候可以在DEBUGVIEW的窗口看到DEBUGVIE格式的输出了。
VC中TRACE的用法有以下四种:
TRACE1 ,就是不带动态参数输出字符串, 类似C的printf("输出字符串");
TRACE2: 中的字符串可以带一个参数输出 ,类似C的printf("...%d",变量);
TRACE3:可以带两个参数输出,类似C的printf("...%d...%f",变量1,变量2);
TRACE4 可以带三个参数输出,类似C的printf("...%d,%d,%d",变量1,变量2,变量3);
TRACE 宏有点象我们以前在C语言中用的Printf函数,使程序在运行过程中输出一些调试信息,使我们能了解程序的一些状态。但有一点不同的是:
TRACE 宏只有在调试状态下才有所输出,而以前用的Printf 函数在任何情况下都有输出。和Printf 函数一样,TRACE函数可以接受多个参数如:
int x = 1;
int y = 16;
float z = 32.0;
TRACE( "This is a TRACE statement\n" );
TRACE( "The value of x is %d\n", x );
TRACE( "x = %d and y = %d\n", x, y );
TRACE( "x = %d and y = %x and z = %f\n", x, y, z );
要注意的是TRACE宏只对Debug 版本的工程产生作用,在Release 版本的工程中,TRACE宏将被忽略。
三、ASSERT宏
如果你设计了一个函数,该函数需要一个指向文档对象的指针做参数,但是你却错误地用一个视图指针调用了这个函数。这个假的地址将导致视数据的破坏。现在,这种类型的问题可以被完全避免,只要在该函数的开始处实现一个ASSERT测试,用来检测该指针是否真正指向一个文档对象。一般来讲,编程者在每个函数的开始处均应例行公事地使用assertion。ASSERT宏将会判断表达式,如果一个表达式为真,执行将继续,否则,程序将显示一条消息并且暂停,你可以选择忽视这条错误并继续、终止这个程序或者是跳到Debug器中。下面一例演示了如何使用一个ASSERT宏去验证一个语句。
void foo(char p, int size )
{
ASSERT( p != 0 ); //确认缓冲区的指针是有效的
ASSERT( ( size >= 100 ); //确认缓冲区至少有100个字节
// Do the foo calculation
}
这些语句不产生任何代码,除非—DEBUG处理器标志被设置。Visual C++只在Debug版本设置这些标志,而在Release版本不定义这些标志。当—DEBUG被定义时,两个assertions将产生如下代码:
//ASSERT( p!= 0 );
do{
if( !(p !=0) && AfxAssertFailedLine(—FILE—,—LINE—) )
AfxDebugBreak();
}while(0);
//ASSERT((size 〉= 100);
do{
if(!(size 〉= 100) &&AfxAssertFailedLine(—FILE—,—LINE—))
AfxDebugBreak();
}while(0);
Do-while循环将整个assertion封装在一个单独的程序块中,使得编译器编译起来很舒畅。If语句将求取表达式的值并且当结果为零时调用AfxAssertFailedLine()函数。这个函数将弹出一个对话框,其中提供三个选项“取消、重试或忽略”,当你选取“重试”时,它将返回TRUE。重试将导致对AfxDebugBreak()函数的调用,从而激活调试器。
AfxAssertFailedLine()是一个未正式公布的函数,它的功能就是显示一个消息框。该函数的源代码驻留在afxasert.cpp中。函数中的—FILE—和—LINE—语句是处理器标志,它们分别指定了源文件名和当前的行号。
AfxAssertFailedLine()是一个未正式公布的函数,它的功能就是显示一个消息框。该函数的源代码驻留在afxasert.cpp中。函数中的—FILE—和—LINE—语句是处理器标志,它们分别指定了源文件名和当前的行号。
四、VERIFY 宏
因为assertion只能在程序的Debug版本中起作用,在表达式中不可以包含赋值语句、增加语句(++)或者是减少语句(--),因为,这些语句实际改变数据。可有时你可能想要验证一个能动的表达式,使用一个赋值语句。那么就到了用VERIFY宏来替代ASSERT。例如:
voidfoo(char p, int size )
{
char q;
VERIFY(q = p);
ASSERT((size 〉= 100);
//Do the foo calculation
//Do the foo calculation
}
在Debug模式下,ASSERT和VERIFY是一回事,但是在Release模式下,VERIFY宏仍然测试表达式而assertion却不起任何作用。可以说,在Release模式下,ASSERT语句被删除了。
请注意,如果你在一个ASSERT语句中错误地使用了一个能动的表达式,编译器将不做任何警告地忽略它。在Release模式下,该表达式就会被无声息地删除掉,这将会导致程序的错误运行。由于Release版的程序通常不包含Debug信息,这类错误将很难被发现。
五、VC高级调试方法-条件及数据断点的设定
(一)位置断点(LocationBreakpoint)
大家最常用的断点是普通的位置断点,在源程序的某一行按F9就设置了一个位置断点。但对于很多问题,这种朴素的断点作用有限。譬如下面这段代码:
void CForDebugDlg::OnOK()
{
for(int i = 0; i < 1000; i++) //A
{
intk = i * 10 - 2; //B
SendTo(k); //C
inttmp = DoSome(i); //D
Trace0("这里要输出的内容”);//在这里可以输出一些有用的信息,你也可以输出I的值,都是可以的
intj = i / tmp; //E
}
}
//其实我们还可以用其他方法调式也是一样的,你可以用TRACE0宏来输出循环中的每一个结果,我们也可以在debug中看见输出的结果,当出现问题时,输出的结果可能就不一样了,我们可以分析一下debug中的结果找出问题的所在
执行此函数,程序崩溃于E行,发现此时tmp为0,假设tmp本不应该为0,怎么这个时候为0呢?所以最好能够跟踪此次循环时DoSome函数是如何运行的,但由于是在循环体内,如果在E行设置断点,可能需要按F5(GO)许多次。这样手要不停的按,很痛苦。使用VC6断点修饰条件就可以轻易解决此问题。步骤如下。
1 Ctrl+B打开断点设置框,如下图:
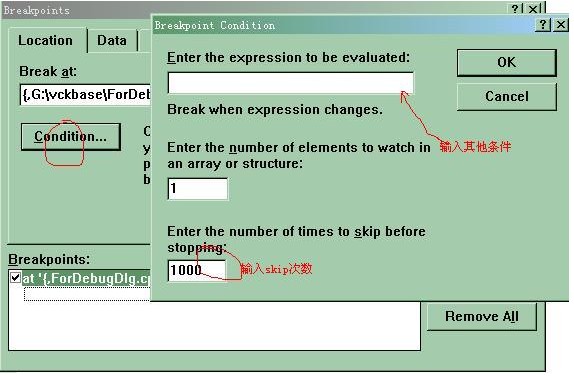
Figure 1设置高级位置断点
2 然后选择D行所在的断点,然后点击condition按钮,在弹出对话框的最下面一个编辑框中输入一个很大数目,具体视应用而定,这里1000就够了。
3 按F5重新运行程序,程序中断。Ctrl+B打开断点框,发现此断点后跟随一串说明:...487 times remaining。意思是还剩下487次没有执行,那就是说执行到513(1000-487)次时候出错的。因此,我们按步骤2所讲,更改此断点的skip次数,将1000改为513。
4 再次重新运行程序,程序执行了513次循环,然后自动停在断点处。这时,我们就可以仔细查看DoSome是如何返回0的。这样,你就避免了手指的痛苦,节省了时间。
再看位置断点其他修饰条件。如Figure 1所示,在“Enter the expression to be evaluated:”下面,可以输入一些条件,当这些条件满足时,断点才启动。譬如,刚才的程序,我们需要i为100时程序停下来,我们就可以输入在编辑框中输入“i==100”。
另外,如果在此编辑框中如果只输入变量名称,则变量发生改变时,断点才会启动。这对检测一个变量何时被修改很方便,特别对一些大程序。
用好位置断点的修饰条件,可以大大方便解决某些问题。
(二) 数据断点(DataBreakpoint)
软件调试过程中,有时会发现一些数据会莫名其妙的被修改掉(如一些数组的越界写导致覆盖了另外的变量),找出何处代码导致这块内存被更改是一件棘手的事情(如果没有调试器的帮助)。恰当运用数据断点可以快速帮你定位何时何处这个数据被修改。譬如下面一段程序:
#include "stdafx.h"
#include <string.h>
int main(int argc, char* argv[])
{
charszName1[10];
charszName2[4];
strcpy(szName1,"shenzhen");
printf("%s\n",szName1); //A
strcpy(szName2,"vckbase"); //B
printf("%s\n",szName1);
printf("%s\n",szName2);
return0;
}
这段程序的输出是
szName1: shenzhen
szName1:ase
szName2:vckbase
首先我给你分析一下为什么会是这样的结果呢!首先你在strcpy(szName1,"shenzhen");这个地方F9设置一个断点,然后F5运行程序,这是程序会断到我们设置的断点,如下图
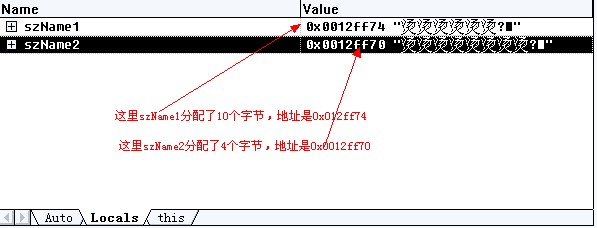
看到了吧,问题出现的原因就在这里,系统给szName2分配的地址是0x0012ff70这里是4个字节,然后呢,在0x0012ff70后面4个字节处,开始分配szName1这10个字节,也就是在0x0012ff74处开始分配10个字节,
F10单步跟踪,来到printf("%s\n", szName1)这一行,如下图

szName1分配的空间已经附上了值.
F10走到下一个printf("%s\n", szName1) 看下图,
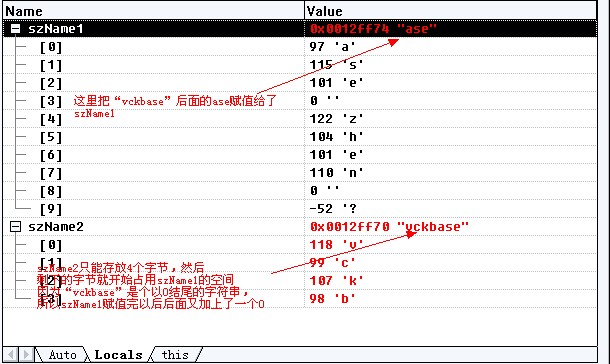
因为szName1 和szName2分配的空间是连续的,所以给szName2赋值超过所容纳的字节时就开始覆盖szName1的内容了,所以说当我们在输出结果的时候就出现我们想不到的结果了,
那么怎么去调试呢,下面是具体的方法
szName1何时被修改呢?因为没有明显的修改szName1代码。我们可以首先在A行设置普通断点,F5运行程序,程序停在A行。然后我们再设置一个数据断点。如下图:
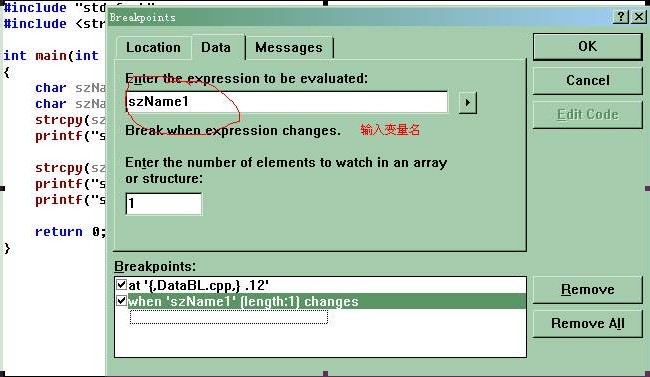
Figure 2 数据断点
F5继续运行,程序停在B行,说明B处代码修改了szName1。B处明明没有修改szName1呀?但调试器指明是这一行,一般不会错,所以还是静下心来看看程序,哦,你发现了:szName2只有4个字节,而strcpy了7个字节,所以覆写了szName1。
数据断点不只是对变量改变有效,还可以设置变量是否等于某个值。譬如,你可以将Figure 2中红圈处改为条件”szName2[0]==''''y''''“,那么当szName2第一个字符为y时断点就会启动。
可以看出,数据断点相对位置断点一个很大的区别是不用明确指明在哪一行代码设置断点。
(三) 其他
1 在call stack窗口中设置断点,选择某个函数,按F9设置一个断点。这样可以从深层次的函数调用中迅速返回到需要的函数。
2 Set Next StateMent命令(debug过程中,右键菜单中的命令)
此命令的作用是将程序的指令指针(EIP)指向不同的代码行。譬如,你正在调试上面那段代码,运行在A行,但你不愿意运行B行和C行代码,这时,你就可以在D行,右键,然后“Set Next StateMent”。调试器就不会执行B、C行。只要在同一函数内,此指令就可以随意跳前或跳后执行。灵活使用此功能可以大量节省调试时间。
3 watch窗口
watch窗口支持丰富的数据格式化功能。如输入0x65,u,则在右栏显示101。
实时显示windows API调用的错误:在左栏输入@err,hr。
在watch窗口中调用函数。提醒一下,调用完函数后马上在watch窗口中清除它,否则,单步调试时每一步调试器都会调用此函数。
4 messages断点不怎么实用。基本上可以用前面讲述的断点代替。
六。VC调试环境设置
为了调试一个程序,首先必须使程序中包含调试信息。一般情况下,一个从AppWizard创建的工程中包含的Debug Configuration自动包含调试信息,但是是不是Debug版本并不是程序包含调试信息的决定因素,程序设计者可以在任意的Configuration中增加调试信息,包括Release版本。
为了增加调试信息,可以按照下述步骤进行:
打开Projectsettings对话框(可以通过快捷键ALT+F7打开,也可以通过IDE菜单Project/Settings打开)
选择C/C++页,Category中选择general ,则出现一个Debug Info下拉列表框,可供选择的调试信息 方式包括:
命令行 Project settings 说明
无 None 没有调试信息
/Zd Line Numbers Only 目标文件或者可执行文件中只包含全局和导出符号以及代码行信息,不包含符号调试信息
/Z7 C7.0- Compatible 目标文件或者可执行文件中包含行号和所有符号调试信息,包括变量名及类型,函数及原型等
/Zi Program Database 创建一个程序库(PDB),包括类型信息和符号调试信息。
/ZI Program Databasefor
Edit and Continue 除了前面/Zi的功能外,这个选项允许对代码进行调试过程中的修改和继续执行。这个选项同时使#pragma设置的优化功能无效
选择Link页,选中复选框"Generate DebugInfo",这个选项将使连接器把调试信息写进可执行文件和DLL
如果C/C++页中设置了Program Database以上的选项,则Link incrementally可以选择。选中这个选项,将使程序可以在上一次编译的基础上被编译(即增量编译),而不必每次都从头开始编译。















 1918
1918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









