




 本文介绍了一种使用Python爬取网站图片的方法。首先选择喜欢的网站,然后安装Python环境,接着通过编写Python代码实现网页请求、图片链接抓取及图片下载等功能。文中详细展示了Python代码实现过程,并附带具体实例。
本文介绍了一种使用Python爬取网站图片的方法。首先选择喜欢的网站,然后安装Python环境,接着通过编写Python代码实现网页请求、图片链接抓取及图片下载等功能。文中详细展示了Python代码实现过程,并附带具体实例。
使用Python爬取小姐姐图片
首先上网站链接 唯vb.net教程
美女生
爬取图片主要分为一下几步:
1.打开一个你喜欢c#教程的小姐姐的网站
E.g xiaojiejie web
2.下载并安装python环境
python 官网
python基础教程
3.开始编码
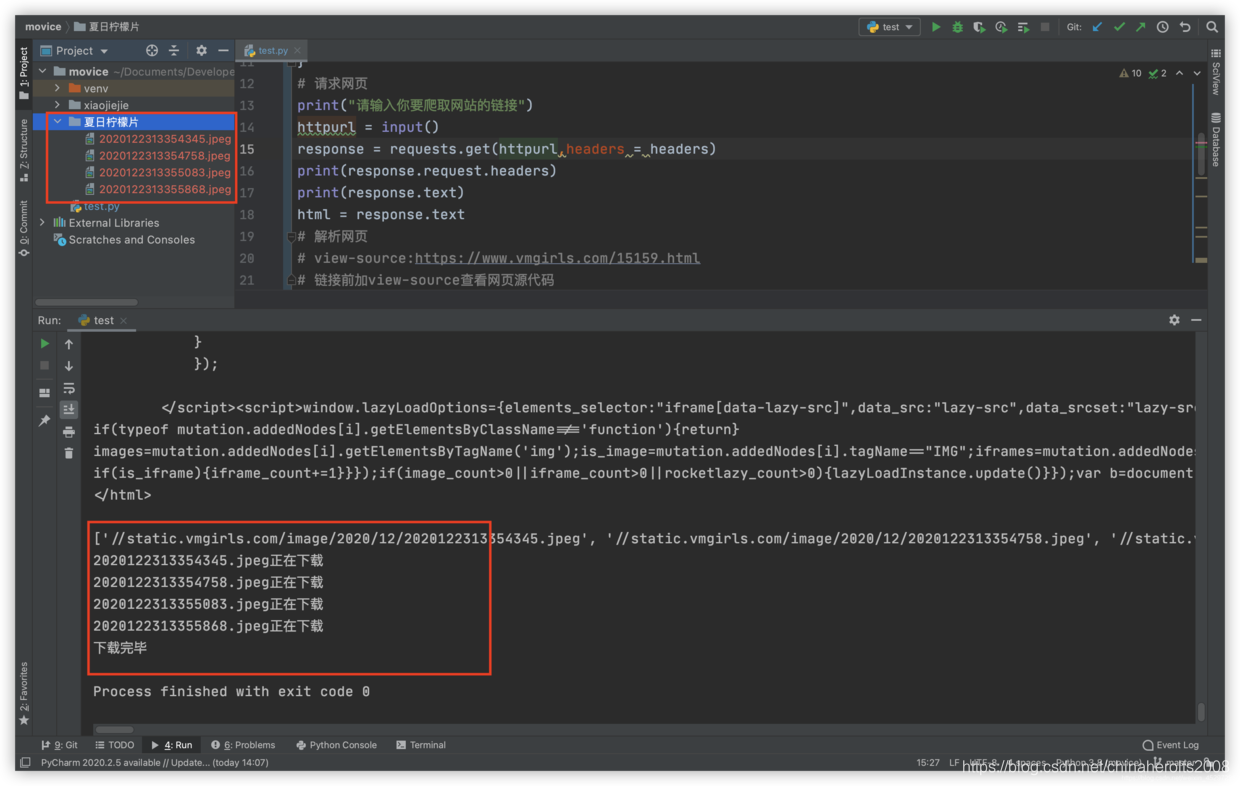
python 全部代码如下
# requests 请求 需要提前在Terminal中安装 pip install requests
import os
import time
import requests
# re正则
import re
# 改变自己身份
headers = {
'User-Agent': 'asbasdf'
}
# 请求网页
print("请输入你要爬取网站的链接")
httpurl = input()
response = requests.get(httpurl,headers = headers)
print(response.request.headers)
print(response.text)
html = response.text
# 解析网页
# view-source:https://www.vmgirls.com/15159.html
# 链接前加view-source查看网页源代码
dir_name = re.findall('<h1 class="post-title h1">(.*?)</h1>',html)[-1]
if not os.path.exists(dir_name):
os.mkdir(dir_name)
# 正则查找
urls = re.findall('<a href="(.*?)" alt=".*?" title=".*?">',html)
print(urls)
# 保存图片
for url in urls:
time.sleep(1)
# 图片名字
name = url.split('/')[-1]
response = requests.get("https:"+url,headers = headers)
print(name+"正在下载")
with open(dir_name+'/'+name,'wb') as f:
f.write(response.content)
print('下载完毕')
4.运行并下载


















 7045
7045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









