






本文实例为大家分享了python遍历文件目录、批量处理同类文件的具体代码,供大家参考,具体内容如下
目录操作
1、获取当前目录
import os
curr_path=os.path.dirname(__file__) #返回当前文件所在的目录,即当前运行的脚本所在父目录
print curr_path
运行示例
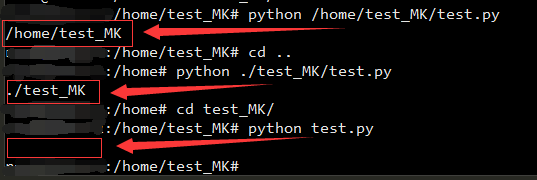
(1)使用os.path.dirname(file)时,是针对运行时对所给程序脚本的路径来获取父目录的,即截取你输入的脚本路径的所在目录名称,如上图示例,输入绝对路径时返回绝对路径,输入相对路径时返回相对路径,如果只输入了脚本名称,则返回空。
(注:当从命令行中进入python环境时时,参数__file__不能使用)
(2)当直接使用os.path.dirname(“/home/test_MK/test.py”)时,直接返回“/home/test_MK”
2、获取目录文件列表
1
2
file_list=os.listdir("/home/test_MK/test"))
print file_list
运行示例
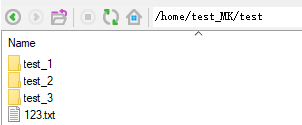
3、获取该目录下文件夹或者文件列表
path="/home/test_MK/test"
objects=os.listdir(path)
dir_list=[] #存放目录列表
file_list=[] #存放文件列表
for obj in objects:
if os.path.isdir(os.path.join(path, obj)):#判断是否是目录os.path.join()用来将路径拼接
dir_list.append(os.path.join(path, obj))#保存时保存完整路径才能对其进行后续操作
print "dir:",obj
else:
file_list.append(os.path.join(path, obj))
print "file:",obj
print "目录列表:",dir_list
print "文件列表:",file_list
#如果项判断是否是文件时用os.isfile()
(注:使用os.isdir()与os.isfile()时,参数必须是一个相对路径或者绝对路径,不能光是一个文件名或者目录名称,这也是上面示例代码中使用os.path.join()的原因,否则函数将判断不出正确结果)
运行示例

批量处理目录下同类文件
以处理pcap文件为例
1、获取某一文件夹下所有pcap包路径,过滤掉其它文件
def getPathFile(path):
'''
name:getPathFile
function:获取所给文件夹下所有pcap文件路径
path:所给文件夹路径
'''
Path = []
try:
pathDir = os.listdir(path)
for allDir in pathDir:
child = os.path.join('%s/%s' % (path, allDir))
#跳过文件夹以及非流量包文件,将后缀名改为自己需要的文件类型即可实现自己的过滤
if os.path.isfile(child) and (".pcap" in str(allDir) or (".cap" in str(allDir))):
Path.append(child)
except:
pass
return Path
2、处理函数,打印一个pcap文件中所有数据包的五元组信息{src_ip,src_port,dst_ip,dst_port}
def print_pack_f(file_path):
'''
name:print_pack_f
function:打印一个pcap文件中所有数据包的五元组信息
file_path:所给pcap文件路径
'''
file_p= open(file_path)
pcap = dpkt.pcap.Reader(file_p)
if not pcap:
return
print "\n\n*******file:%s*******\n"% file_path
for (ts,buf) in pcap:
try:
eth = dpkt.ethernet.Ethernet(buf) #解包,物理层
if not isinstance(eth.data, dpkt.ip.IP): #解包,网络层
continue
ip = eth.data
src_ip="%d.%d.%d.%d"%tuple(map(ord,list(ip.src)))
dst_ip="%d.%d.%d.%d"%tuple(map(ord,list(ip.dst)))
if (not isinstance(ip.data, dpkt.tcp.TCP)) and (not isinstance(ip.data, dpkt.udp.UDP)): #解包,传输层
continue
transf= ip.data
print "<",src_ip,":",transf.sport,"-->",dst_ip,":",transf.dport,">"
except Exception,err:
print "[error] %s" % err
3、调用示例
def main(dir_path):
all_file_path=getPathFile(dir_path) #获取目录下所有pcap文件路径
for file in all_file_path: #遍历处理
print_pack_f(file) #单个pcap文件处理,可将本函数替换成自定义的功能,便可实现批量处理
if __name__ == '__main__':
opts,args = getopt.getopt(sys.argv[1:], "hi:") #从命令行获取参数
if not opts: #若没有带参数
print "\n\
*******************\n\
warn! please enter related parameters,enter -h for help!\n\n\
*******************\n"
sys.exit()
input_path=''
for op, value in opts:
if op == "-i":
input_path = value
elif op == "-h":
usage() #帮助信息,只是简单的一个输出函数,输出内容自定义
sys.exit()
main(input_path)
结果展示
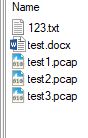
测试目录如下
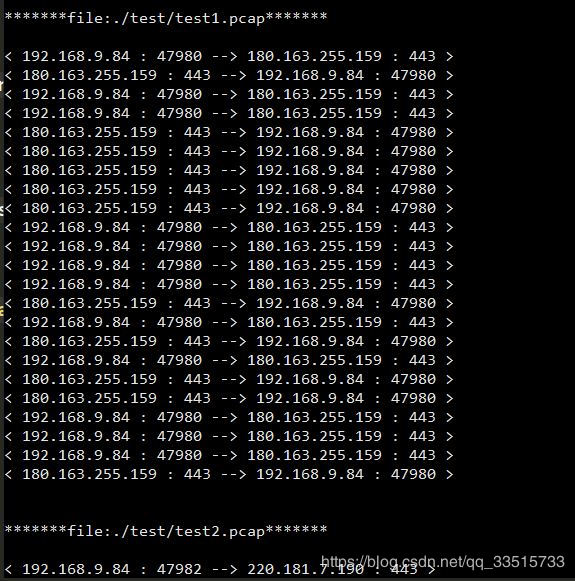
运行结果(python test.py -i ./test)
完毕
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持vb.net教程C#教程python教程SQL教程access 2010教程xin3721自学网















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









